Habilite a IA generativa e os cursos de pesquisa semântica em seu banco de dados com o MongoDB Atlas e o OpenAI






Avalie esse Tutorial


Nosso objetivo neste tutorial é aproveitar os LLMs de código aberto disponíveis e populares no mercado e adicionar os recursos e a potência desses LLMs no mesmo banco de dados de sua carga de trabalho operacional (ou, em outras palavras, primária).
A criação de um modelo de linguagem grande (LLM) não é um processo de um ou dois dias. Pode levar anos para construir um modelo ajustado e otimizado. A boa notícia é que já temos muitos LLMs disponíveis no mercado, incluindo BERT, GPT-3, GPT-4, Hugging Face e Claude, e podemos fazer bom uso deles de diferentes maneiras.
Os LLMs fornecem representações vetoriais de dados de texto, capturando relações semânticas e compreendendo o contexto da linguagem. Essas representações vetoriais podem ser aproveitadas para várias tarefas, incluindo pesquisa vetorial, para encontrar itens de texto semelhantes ou relevantes em conjuntos de dados.
As representações vetoriais de dados de texto podem ser usadas na captura de semelhanças semânticas, pesquisa e recuperação, recuperação de documentos, sistemas de recomendação, agrupamento e categorização de textos e detecção de anomalias.
Neste artigo, exploraremos o recurso semântica do Atlas Search com representações vetoriais de dados de texto com um caso de uso do mundo real. Usaremos o conjunto de dados de amostra do Airbnb do MongoDBno qual tentaremos encontrar uma sala de nossa escolha dando um prompt sincronizado.
Usaremos o MongoDB Atlas como uma plataforma de dados, onde teremos nosso conjunto de dados de amostra (uma carga de trabalho operacional) do Airbnb e habilitaremos recursos de pesquisa e pesquisa vetorial sobre ele.
O Semantic Atlas Search é uma técnica de recuperação de informações que melhora a experiência do usuário no Atlas Search por meio da compreensão da intenção ou do significado por trás das queries e do conteúdo. Semântica O Atlas Search concentra-se no contexto e na semântica, em vez da correspondência exata de palavras, como faria o Atlas Search tradicional. Saiba mais sobre a semântica Atlas Search e como ela difere do Google Atlas Search e da Atlas Search baseada em texto.
A pesquisa vetorial é uma técnica usada para sistemas de recuperação e recomendações de informações para encontrar itens semelhantes a itens de query ou vetores. Os itens de dados são representados como vetores de alta dimensão e a similaridade entre os itens é calculada com base nas propriedades matemáticas desses vetores. Essa é uma abordagem muito útil e comumente usada na recomendação de conteúdo, recuperação de imagens e pesquisa de documentos.
O Atlas Vector Search permite pesquisar em dados não estruturados. Você pode armazenar incorporações vetoriais geradas por modelos populares de aprendizado de máquina, como OpenAI e Hugging Face, utilizando-os para pesquisa semântica e experiências de usuário personalizadas, criando RAGs e muitos outros casos de uso.
Temos um conjunto de dados do Airbnb que contém uma boa descrição escrita para cada uma das propriedades. Permitiremos que os usuários Express sua escolha de localização em palavras - por exemplo, "Nice cozy, comfy room near beach," "3 bedroom studio apartment for couples near beach," "Studio with nice city view," etc. - e o banco de dados retornará os resultados relevantes com base na frase e nas palavras-chave adicionadas.
O que ele fará nos bastidores é fazer uma chamada de API para o LLM que estamos usando (OpenAI) e obter as incorporações vetoriais para a pesquisa/solicitação que passamos/consultamos (como fazemos na interface do ChatGPT). Em seguida, ele retornará as incorporações vetoriais e poderemos pesquisar com essas incorporações em nosso conjunto de dados operacional, o que permitirá que nosso banco de dados retorne resultados semânticos/contextuais.
Com apenas alguns cliques e com o poder dos LLMs existentes e muito avançados, podemos oferecer a melhor experiência de pesquisa ao usuário usando nosso conjunto de dados operacionais existente.
- Crie um banco de dados chamado sample_airbnb e adicione um único registro fictício na coleção chamada listagensAndReviews.
- Use uma máquina com a versão mais recente do Python (3.11.1 foi usado ao preparar este artigo) e o driver PyMongo instalado (a versão mais recente - 4.6.1 foi usado enquanto preparação deste artigo).
Neste ponto, supondo que a configuração inicial esteja concluída, vamos pular direto para as etapas de integração.
- Crie um trigger para adicionar/atualizar incorporações vetoriais.
- Crie uma variável para armazenar credenciais OpenAI. (Usaremos isso para recuperação no código do trigger.)
- Crie um índice Atlas Search .
- Carregue/insira seus dados.
- Consultar o banco de dados.
Seguiremos cada uma das etapas de integração mencionadas acima com as instruções úteis abaixo para que você possa encontrar as telas relevantes enquanto a executa e possa configurar facilmente seu próprio ambiente.
No menu esquerdo do seu Atlas cluster, clique em Triggers.

Clique em Adicionar Trigger, que estará visível no canto superior direito da página de triggers.

Selecione as opções apropriadas na páginaAdicionar trigger, conforme mostrado abaixo.



É aqui que o código de trigger precisa ser mostrado na próxima etapa.
Adicione o código a seguir na área de função, visível na Etapa 3 acima, para adicionar/atualizar incorporações vetoriais para documentos que serão acionados quando um novo documento for criado ou um documento existente for atualizado.
1 exports = async function(changeEvent) { 2 // Get the full document from the change event. 3 const doc = changeEvent.fullDocument; 4 5 // Define the OpenAI API url and key. 6 const url = 'https://api.openai.com/v1/embeddings'; 7 // Use the name you gave the value of your API key in the "Values" utility inside of App Services 8 const openai_key = context.values.get("openAI_value"); 9 try { 10 console.log(`Processing document with id: ${doc._id}`); 11 12 // Call OpenAI API to get the embeddings. 13 let response = await context.http.post({ 14 url: url, 15 headers: { 16 'Authorization': [`Bearer ${openai_key}`], 17 'Content-Type': ['application/json'] 18 }, 19 body: JSON.stringify({ 20 // The field inside your document that contains the data to embed, here it is the "plot" field from the sample movie data. 21 input: doc.description, 22 model: "text-embedding-3-small" 23 }) 24 }); 25 26 // Parse the JSON response 27 let responseData = EJSON.parse(response.body.text()); 28 29 // Check the response status. 30 if(response.statusCode === 200) { 31 console.log("Successfully received embedding."); 32 33 const embedding = responseData.data[0].embedding; 34 35 // Use the name of your MongoDB Atlas Cluster 36 const collection = context.services.get("AtlasSearch").db("sample_airbnb").collection("listingsAndReviews"); 37 38 // Update the document in MongoDB. 39 const result = await collection.updateOne( 40 { _id: doc._id }, 41 // The name of the new field you'd like to contain your embeddings. 42 { $set: { description_embedding: embedding }} 43 ); 44 45 if(result.modifiedCount === 1) { 46 console.log("Successfully updated the document."); 47 } else { 48 console.log("Failed to update the document."); 49 } 50 } else { 51 console.log(`Failed to receive embedding. Status code: ${response.statusCode}`); 52 } 53 54 } catch(err) { 55 console.error(err); 56 } 57 };
Neste ponto, com o bloco de código e configuração acima que fizemos, ele será acionado quando um(s) documento(s) for(em) atualizado(s) ou inserido(s) na collectionlistAndReviews do nossobanco de dados sample_airbnb . Este bloco de código chamará a API OpenAI, buscará os embeddings do campo body e armazenará os resultados nocampo description_embedding da collectionlistAndReviews .
Agora que configuramos um trigger, vamos criar variáveis para armazenar as credenciais da OpenAI na próxima etapa.
Depois de criar o cluster, você verá a guiaApp Services na área superior esquerda, ao lado de Charts.
Clique em App Services. Você verá o trigger que criou na primeira etapa.

Clique no trigger presente e ele abrirá uma página na qual você poderá clicar na guiaValues (Valores ) presente no menu à esquerda, conforme mostrado abaixo.

Clique em Criar Novo Valor com a variável chamada openAI_value e outra variável chamada openAI_key que vincularemos ao segredo que armazenamos na variávelopenAI_value.

Preparamos nosso serviço de aplicativo para buscar credenciais de API e também adicionamos uma função de trigger que será acionada/executada após a inserção ou atualização de documentos.
Agora, criaremos um Atlas Search, carregaremos os dados de amostra fornecidos pelo MongoDB e executaremos a query do banco de dados.
Clique no nome do cluster e, em seguida, na guia de pesquisa na página do cluster.

Clique em Criar índice como mostrado abaixo para criar um índice de pesquisa Atlas. 
Selecione Editor JSON e cole o objeto JSON.
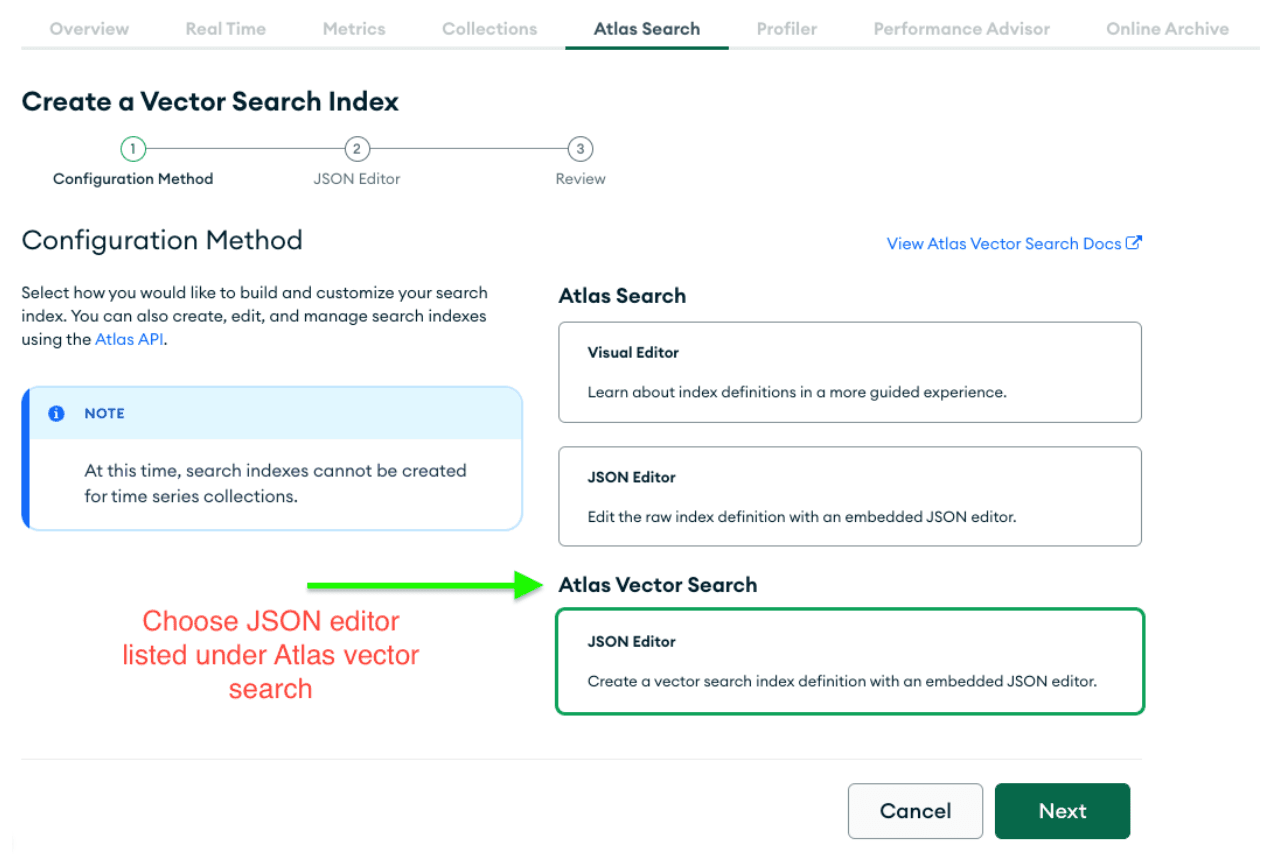
Adicione uma definição de índice de pesquisa de vetores, conforme mostrado abaixo.

Criamos o índice de pesquisa do Atlas na etapa acima. Agora, estamos todos prontos para carregar os dados em nosso ambiente preparado. Então, na próxima etapa, vamos carregar dados de amostra.
Como pré-requisito para esta etapa, precisamos garantir que o cluster esteja instalado e em execução e que a tela esteja visível, conforme mostrado na etapa 1 abaixo. Certifique-se de que a coleção chamada listagensAndReviews seja criada no banco de dadossample_airbnb . Se você ainda não o criou, crie-o alternando para a guia Explorador de Dados .
Podemos carregar o conjunto de dados de amostra da própria opção Atlas cluster, conforme mostrado abaixo.

Depois de carregar os dados, verifique se o campo de incorporação foi adicionado à coleção.
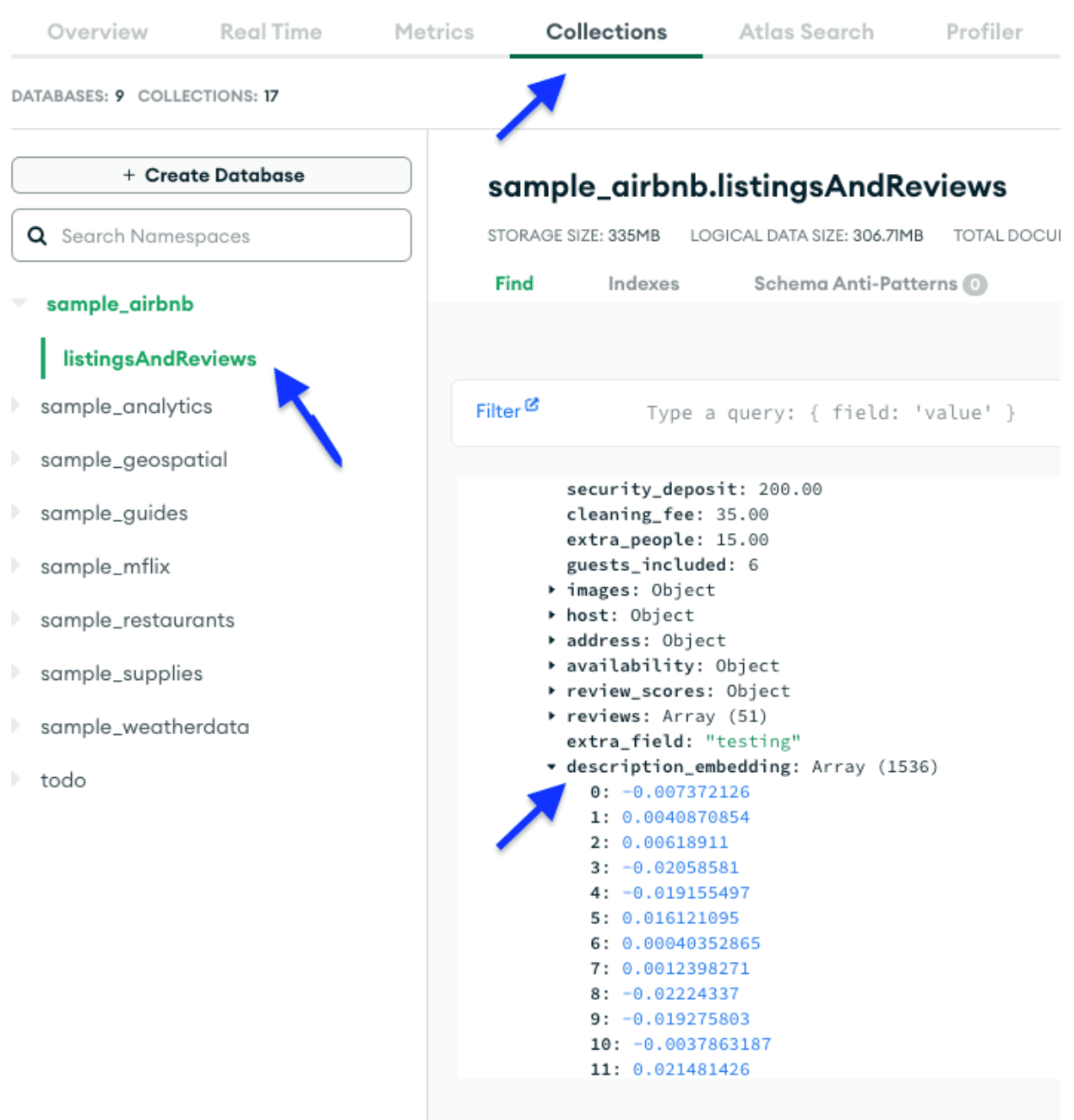
Neste ponto, carregamos o conjunto de dados de amostra. Ele deve ter acionado o código que configuramos para ser acionado na inserção ou nas atualizações. Como resultado disso, o campodescription_embedding será adicionado, contendo uma matriz de vetores.
Agora que preparamos tudo, vamos começar a consultar nosso conjunto de dados e ver os resultados empolgantes que obtemos com nosso prompt de usuário. Na próxima seção de consulta do banco de dados, passaremos nosso prompt de usuário de exemplo diretamente para o script Python.
Como pré-requisito para esta etapa, você precisará de um tempo de execução para o roteiro do Python. Pode ser sua máquina local, uma instância ec2 na AWS, ou você pode usar o AWS Lambda - qualquer que seja a opção mais conveniente. Certifique-se de ter instalado o PyMongo no ambiente de sua escolha. O bloco de código a seguir pode ser escrito em um notebook do Jupyter ou no VSCode e pode ser executado no tempo de execução do Jupyter ou por meio da linha de comando, dependendo da opção escolhida. O bloco de código a seguir demonstra como executar um Atlas Search e recuperar registros do seu banco de dados operacional encontrando incorporações de prompts de usuários recebidos da API OpenAI.
1 import pymongo 2 import requests 3 import pprint 4 5 def get_vector_embeddings_from_openai(query): 6 openai_api_url = "https://api.openai.com/v1/embeddings" 7 openai_api_key = "<your-open-ai-api-key>" 8 9 data = { 10 'input': query, 11 'model': "text-embedding-3-small" 12 } 13 14 headers = { 15 'Authorization': 'Bearer {0}'.format(openai_api_key), 16 'Content-Type': 'application/json' 17 } 18 19 response = requests.post(openai_api_url, json=data, headers=headers) 20 embedding = [] 21 if response.status_code == 200: 22 embedding = response.json()['data'][0]['embedding'] 23 return embedding 24 25 def find_similar_documents(embedding): 26 mongo_url = 'mongodb+srv://<username>:<password>@<cluster-url.mongodb.net>/?retryWrites=true&w=majority' 27 client = pymongo.MongoClient(mongo_url) 28 db = client.sample_airbnb 29 collection = db["listingsAndReviews"] 30 31 pipeline = [ 32 { 33 "$vectorSearch": { 34 "index": "default", 35 "path": "descriptions_embedding", 36 “queryVector”: “embedding”, 37 “numCandidates”: 150, 38 “limit”: 10 39 } 40 }, 41 { 42 "$project": { 43 "_id": 0, 44 "description": 1 45 } 46 } 47 ] 48 documents = collection.aggregate(pipeline) 49 return documents 50 51 def main(): 52 query = "Best for couples, nearby beach area with cool weather" 53 try: 54 embedding = get_vector_embeddings_from_openai(query) 55 documents = find_similar_documents(embedding) 56 print("Documents") 57 pprint.pprint(list(documents)) 58 except Exception as e: 59 print("Error occured: {0}".format(e)) 60 61 main()

Pesquisamos "best for couples, nearby beach area with cool weather " no bloco de código. Confira os resultados interessantes que obtivemos, que são contextual e semanticamente compatíveis e correspondem às expectativas do usuário.
Para resumir, usamos o Atlas Apps Services para configurar os triggers e as chaves de API OpenAI. No código de trigger, escrevemos uma lógica para buscar as incorporações do OpenAI e armazená-las em documentos importados/recém-criados. Com essas etapas, habilitamos os recursos de pesquisa semântica em nosso conjunto de dados de carga de trabalho principal que, neste caso, é o Airbnb.
Se tiver alguma dúvida ou quiser discutir esse ou quaisquer novos casos de uso, pode me procurar no LinkedIn.
Principais comentários nos fóruns
Ainda não há comentários sobre este artigo.
Avalie esse Tutorial