Framework de agregação com tutorial do Node.js






Avalie esse Início rápido


Quando quiser analisar dados armazenados no MongoDB, você pode usar o poderoso framework de agregação do MongoDB para fazer isso. Hoje, darei a você uma visão geral de alto nível do framework de agregação e mostrarei como usá-lo.
Esta publicação usa o MongoDB 4.0, Driver MongoDB Node.js 3.3.2 e Node.js 10.16.3.
Clique aqui para ver uma versão mais recente desta publicação que usa o MongoDB 4.4, Driver MongoDB Node.js 3.6.4 e Node.js 14.15.4.
Se você acabou de chegar nesta série Início rápido com MongoDB e Node.js, seja bem-vindo! Até agora, vimos como se conectar ao MongoDB e executar cada uma das operações CRUD (criar, ler, atualizar e excluir). O código que escrevemos hoje usará a mesma estrutura do código que criamos na primeira publicação da série. Então, se você tiver alguma dúvida sobre como começar ou como o código está estruturado, volte a essa primeira publicação.
E, com isso, vamos nos aprofundar no framework de agregação!
Se você gosta mais de vídeos do que de artigos, não se preocupe. Fiz um vídeo só para você! O vídeo abaixo aborda o mesmo conteúdo deste artigo.
Comece hoje mesmo com um cluster M0 no Atlas. É gratuito para sempre e é a maneira mais fácil de experimentar as etapas desta série de blogs.
O framework de agregação permite que você analise seus dados em tempo real. Usando-o, você pode criar um pipeline de agregação que consiste em um ou mais estágios. Cada estágio transforma os documentos e passa a saída para o próximo estágio.
Se você estiver familiarizado com o pipeline do Linux (
|), poderá pensar no pipeline de agregação como um conceito muito semelhante. Assim como a saída de um comando é passada como entrada para o próximo comando quando você usa o piping, a saída de um estágio é passada como entrada para o próximo estágio quando você usa o pipeline de agregação.O framework de agregação tem uma variedade de estágios disponíveis para você usar. Hoje, discutiremos os fundamentos de como usar $match, $group, $sort e $limit. Observe que o framework de agregação tem muitos outros estágios avançados, incluindo $count, $geoNear, $graphLookup, $project, $unwind e outros.
Estou esperando para visitar em breve a bonita cidade de Sydney, na Austrália. Sydney é uma cidade enorme com muitos subúrbios, e não sei por onde começar a procurar um aluguel barato. Quero saber quais subúrbios de Sydney têm, em média, os anúncios mais baratos de um quarto no Airbnb.
Eu poderia escrever uma query para puxar todos os anúncios de um quarto na área de Sydney e, em seguida, escrever um script para agrupar os anúncios por bairro e calcular o preço médio por bairro. Ou poderia escrever um único comando usando o pipeline de agregação. Vamos usar o pipeline de agregação.
Há várias maneiras de criar pipelines de agregação. Você pode escrevê-los manualmente em um editor de código ou criá-los visualmente dentro do MongoDB Atlas ou do MongoDB Compass. Em geral, não recomendo escrever pipelines manualmente, pois é muito mais fácil entender o que seu pipeline está fazendo e detectar erros quando você usa um editor visual. Como você já está configurado para usar o MongoDB Atlas para esta série de blogs, criaremos nosso pipeline de agregação no Atlas.
A primeira coisa que precisamos fazer é navegar até o construtor de pipelines de agregação no Atlas.
- No menu Organizações, no canto superior esquerdo, selecione a organização que você está usando para esta série de Início Rápido.
- No menu Projetos, localizado abaixo do menu Organizações, selecione o projeto que você está usando para esta série de Início Rápido.
- No painel direito do cluster, clique em coleções.
- Na lista de bancos de dados e coleções que aparece, selecione listingsAndReviews.
- No painel direito, selecione a visualização Agregação para abrir o construtor de pipeline de agregação.
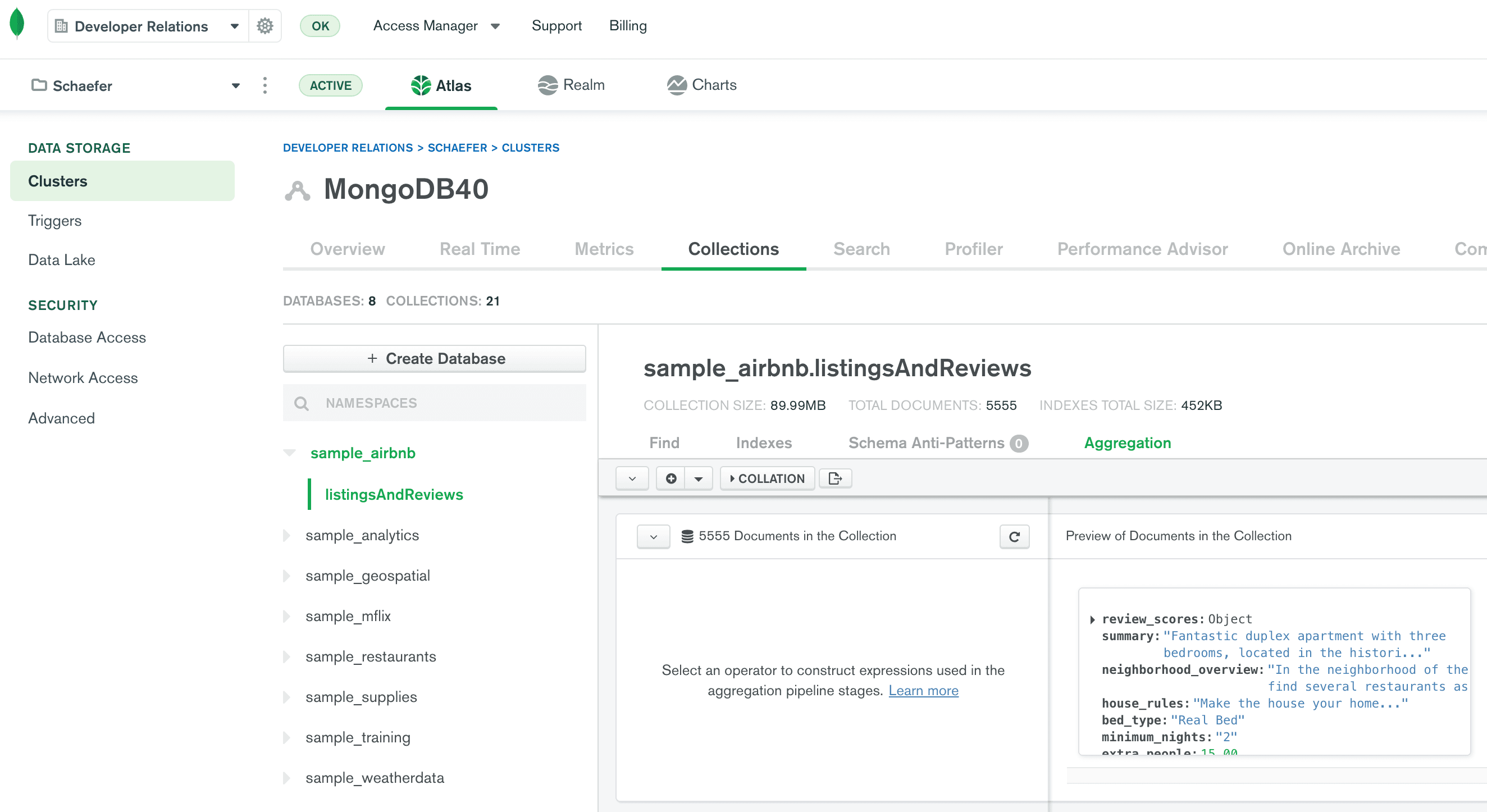
O construtor de pipelines de agregação fornece uma representação visual do pipeline de agregação. Cada estágio é representado por uma nova linha. Você pode colocar o código de cada estágio no lado esquerdo de uma linha, e o construtor de pipelines de agregação fornecerá automaticamente uma amostra ao vivo dos resultados desse estágio no lado direito da linha.
Agora estamos prontos para criar um pipeline de agregação.
Vamos começar restringindo os documentos em nosso pipeline a anúncios de um quarto no mercado de Sydney, Austrália, onde o tipo de quarto é “Casa inteira/apto”. Podemos fazer isso usando o estágio $match.
- Na linha que representa o primeiro estágio do pipeline, escolha $match na caixa Selecionar.... O construtor de pipelines de agregação fornece automaticamente códigos de amostra de como usar o operador
$matchna caixa de código do estágio.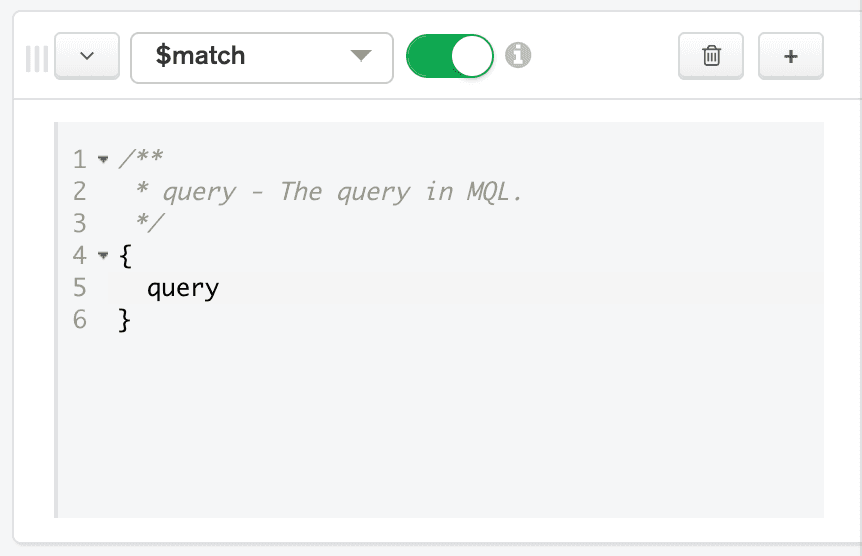
- Agora podemos inserir uma query na caixa de código. A sintaxe para
$matché a mesma sintaxe defindOne()que usamos em uma publicação anterior. Substitua o código na caixa de código do estágio$matchpelo seguinte:
1 { 2 bedrooms: 1, 3 "address.country": "Australia", 4 "address.market": "Sydney", 5 "address.suburb": { $exists: 1, $ne: "" }, 6 room_type: "Entire home/apt" 7 }
Observe que usaremos o campo
address.suburb mais tarde no pipeline, portanto, estamos filtrando documentos em que address.suburb não existe ou é representado por uma string vazia.O construtor de pipeline de agregação atualiza automaticamente a saída no lado direito da linha para apresentar uma amostra de 20 documentos que serão incluídos nos resultados após a execução do estágio
$match.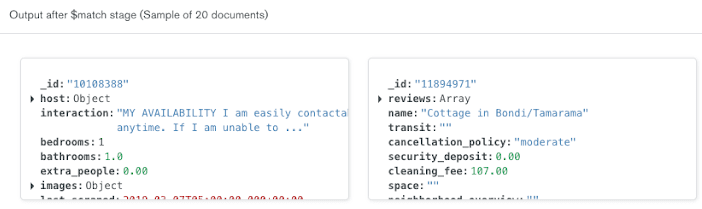
Agora que reduzimos nossos documentos a listagens de um quarto no mercado de Sydney, Austrália, estamos prontos para agrupá-los por subúrbio. Podemos fazer isso usando o estágio $group.
- Clique em ACRESCENTAR ESTÁGIO. Um novo estágio aparece no pipeline.
- Na linha que representa o novo estágio do pipeline, escolha $group na caixa Selecionar... O Aggregation Pipeline Builder fornece automaticamente um exemplo de código de como usar o
$groupoperador na caixa de código do estágio.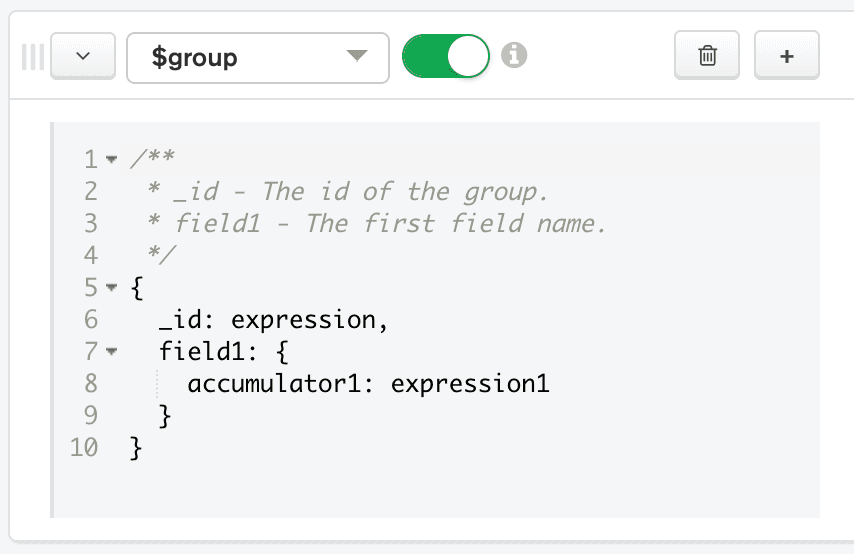
- Agora podemos inserir o código para o estágio
$group. Forneceremos um_id, que é o campo que o Aggregation Framework usará para criar nossos grupos. Neste caso, usaremos$address.suburbcomo nosso_id. Dentro da fase $group, também criaremos um novo campo chamadoaveragePrice. Podemos usar o operador de pipeline de agregação $avg para calcular o preço médio de cada subúrbio. Substitua o código na caixa de código do estágio $group pelo seguinte:
1 { 2 _id: "$address.suburb", 3 averagePrice: { 4 "$avg": "$price" 5 } 6 }
O construtor de pipelines de agregação atualiza automaticamente a saída no lado direito da linha para mostrar uma amostra de 20 documentos que serão incluídos nos resultados após a
$group execução do estágio . Observe que os documentos foram transformados. Em vez de ter um documento para cada anúncio, agora temos um documento para cada subúrbio. Os documentos de subúrbio têm apenas dois campos: _id (o nome do subúrbio) e averagePrice.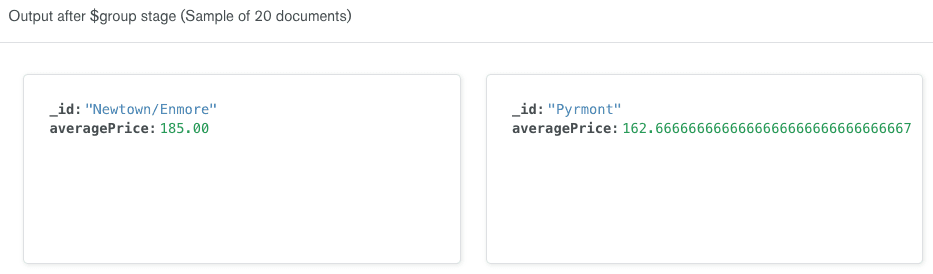
Agora que temos os preços médios dos subúrbios no mercado de Sydney, estamos prontos para classificá-los e descobrir quais são os mais baratos. Podemos fazer isso usando o estágio $sort.
- Clique em ACRESCENTAR ESTÁGIO. Um novo estágio aparece no pipeline.
- Na linha que representa o novo estágio do pipeline, escolha $sort na caixa Selecionar.... O construtor de pipelines de agregação fornece automaticamente códigos de amostra de como usar o operador
$sortna caixa de código do estágio.
- Agora estamos prontos para inserir o código para o estágio
$sort. Classificaremos no campo$averagePriceque criamos na etapa anterior. Indicaremos que queremos classificar em ordem crescente passando1. Substitua o código na caixa de código do estágio$sortpelo seguinte:
1 { 2 "averagePrice": 1 3 }
O construtor de pipelines de agregação atualiza automaticamente a saída no lado direito da linha para mostrar uma amostra de 20 documentos que serão incluídos nos resultados após a execução do estágio
$sort. Observe que os documentos têm o mesmo formato dos documentos do estágio anterior; os documentos são simplesmente classificados do mais barato para o mais caro.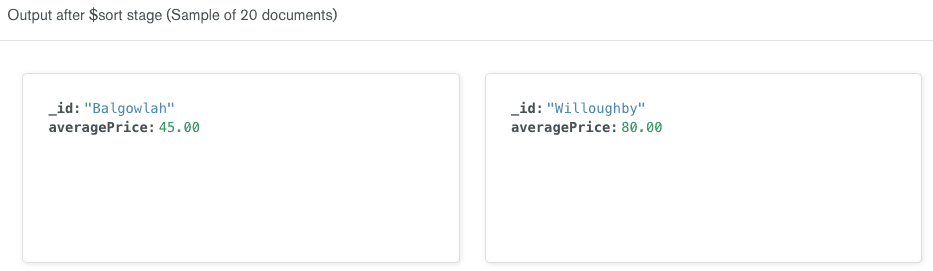
Agora temos os preços médios para os subúrbios no mercado de Sydney, Austrália, classificados do mais barato ao mais caro. Podemos não querer trabalhar com todos os documentos do subúrbio em nosso aplicativo. Em vez disso, podemos querer limitar nossos resultados aos 10 subúrbios mais baratos. Podemos fazer isso utilizando o estágio $limit.
- Clique em ACRESCENTAR ESTÁGIO. Um novo estágio aparece no pipeline.
- Na linha que representa o novo estágio do pipeline, escolha $limit na caixa Selecionar... O construtor de pipelines de agregação fornece automaticamente um exemplo de código de como usar o operador
$limitna caixa de código do estágio.
- Agora estamos prontos para inserir código para o estágio
$limit. Vamos limitar nossos resultados a 10 documentos. Substitua o código na caixa de código do estágio $limit pelo seguinte:
1 10
O construtor de pipelines de agregação atualiza automaticamente a saída no lado direito da linha para mostrar uma amostra de 10 documentos que serão incluídos nos resultados após a execução do estágio
$limit. Observe que os documentos têm o mesmo formato dos documentos do estágio anterior; simplesmente limitamos o número de resultados a 10.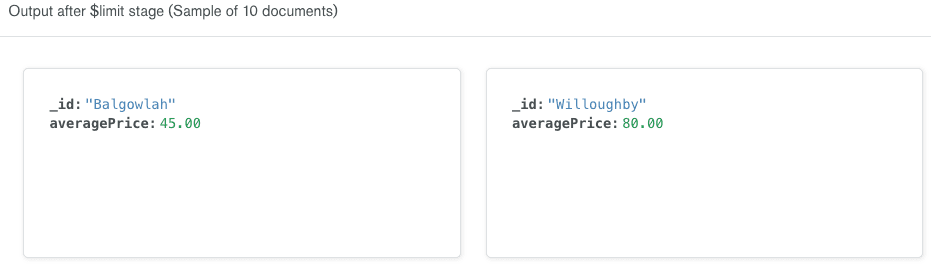
Agora que criamos um pipeline de agregação, vamos executá-lo de dentro de um script Node.js.
Para facilitar o acompanhamento desta publicação no blog, criei um modelo inicial para um script do Node.js que acessa um cluster do Atlas.
- Abra
template.jsno seu editor de código favorito. - Atualize o URI de conexão para apontar para seu cluster do Atlas. Se não tiver certeza de como fazer isso, consulte a primeira publicação desta série.
- Salve o arquivo como
aggregation.js.
Você pode executar esse arquivo executando
node aggregation.js em seu shell. Nesse ponto, o arquivo simplesmente abre e fecha uma conexão com o cluster do Atlas, portanto, nenhuma saída é esperada. Se você vir DeprecationWarnings, poderá ignorá-los para os fins deste post.Vamos criar uma função cuja tarefa seja imprimir os bairros mais baratos para um determinado mercado.
- Continuando a trabalhar no
aggregation.js, crie uma função assíncrona denominadaprintCheapestSuburbsque aceita um MongoClient conectado, um país, um mercado e o número máximo de resultados para imprimir como parâmetros.1 async function printCheapestSuburbs(client, country, market, maxNumberToPrint) { 2 } - Podemos executar um pipeline no Node.js chamando a função aggregate() da coleção. Cole o seguinte na sua nova função:
1 const pipeline = []; 2 3 const aggCursor = client.db("sample_airbnb") 4 .collection("listingsAndReviews") 5 .aggregate(pipeline); - O primeiro parâmetro para
aggregate()é um pipeline do tipo objeto. Podemos criar manualmente o pipeline aqui. Como já criamos um pipeline dentro do Atlas, vamos exportar o pipeline de lá. Retorne ao construtor de pipeline de agregação no Atlas. Clique no botão Exportar código do pipeline para a linguagem.
- A caixa de diálogo Exportar pipeline para linguagem é exibida. Na caixa de seleção Exportar pipleine para, escolha NODE.
- No painel Nó, no lado direito da caixa de diálogo, clique no botão copiar.
- Retorne ao seu editor de código e cole o
pipelineno lugar do objeto vazio atualmente atribuído à constante do pipeline.1 const pipeline = [ 2 { 3 '$match': { 4 'bedrooms': 1, 5 'address.country': 'Australia', 6 'address.market': 'Sydney', 7 'address.suburb': { 8 '$exists': 1, 9 '$ne': '' 10 }, 11 'room_type': 'Entire home/apt' 12 } 13 }, { 14 '$group': { 15 '_id': '$address.suburb', 16 'averagePrice': { 17 '$avg': '$price' 18 } 19 } 20 }, { 21 '$sort': { 22 'averagePrice': 1 23 } 24 }, { 25 '$limit': 10 26 } 27 ]; - Esse pipeline funcionaria bem como está gravado. No entanto, é codificado para pesquisar 10 resultados no mercado de Sydney, Austrália. Devemos atualizar esse pipeline para ser mais genérico. Faça as seguintes substituições na definição do pipeline:
- Substitua
'Australia'porcountry - Substitua
'Sydney'pormarket - Substitua
10pormaxNumberToPrint
aggregate()retorna um AggregationCursor, que estamos armazenando na constanteaggCursor. Um AggregationCursor permite percorrer os resultados do pipeline de agregação. Podemos usar forEach() do AggregationCursor para iterar sobre os resultados. Cole o seguinte dentro deprintCheapestSuburbs()abaixo da definição deaggCursor.
1 await aggCursor.forEach(airbnbListing => { 2 console.log(`${airbnbListing._id}: ${airbnbListing.averagePrice}`); 3 });
Agora estamos prontos para chamar nossa função para imprimir os 10 subúrbios mais baixos do mercado de Sydney, Austrália. Adicione a seguinte chamada na função
main() abaixo do comentário que diz Make the appropriate DB calls.1 await printCheapestSuburbs(client, "Australia", "Sydney", 10);
Executar aggregation.js resulta na seguinte saída:
1 Balgowlah: 45.00 2 Willoughby: 80.00 3 Marrickville: 94.50 4 St Peters: 100.00 5 Redfern: 101.00 6 Cronulla: 109.00 7 Bellevue Hill: 109.50 8 Kingsgrove: 112.00 9 Coogee: 115.00 10 Neutral Bay: 119.00
Agora sei em quais bairros devo começar a pesquisar enquanto me preparo para minha viagem a Sydney, Austrália.
O framework de agregação é uma maneira incrivelmente poderosa de analisar seus dados. Aprender a criar pipelines pode parecer um pouco trabalhoso no início, mas vale a pena. O framework de agregação pode obter resultados para os usuários finais mais rapidamente e evitar a necessidade de muitos scripts.
Hoje, nós apenas raspamos a superfície da estrutura de agregação . Recomendamos o curso gratuito da MongoDB University especificamente sobre a framework de agregação : MongoDB Aggregation. O curso tem uma explicação mais completa de como a estrutura de agregação funciona e fornece detalhes sobre como usar os vários estágios do pipeline.
Esta postagem incluiu muitos trechos de código que se basearam no código gravado na primeira postagem desta série de Início Rápido do MongoDB e do Node.js. Para obter uma cópia completa do código usado na postagem de hoje, visite o Repositório GitHub do Node.js Quick Start.
Agora você está pronto para passar para a próxima postagem desta série sobre change streams e triggers. Nessa postagem, você aprenderá como reagir automaticamente às alterações em seu banco de dados.
Questões? Comentários? Queremos muito nos conectar com você. Participe da conversa nos fóruns da MongoDB Community.