Confissões de um PyMongoArrowholic: usando Atlas Vector Search e PyMongoArrow para pesquisar semanticamente itens de moda de luxo


Avaliar este tutorial

As a twenty-something-year-old living in New York City, online shopping is my second favorite hobby. What is my first, you ask? Figuring out ways to optimize my shopping addiction so I can spend fewer hours scrolling.
Anyone who fantasizes about luxury (it’s called manifestation, people!) knows about Net-A-Porter and all the incredible pieces the website offers. While my normal approach is sorting by price from low to high, I’d be lying if I said it isn’t incredibly fun to see the full scope of what’s out there. So, let’s use a fun dataset that holds last season's Net-A-Porter items, and semantically search to explore some of the most expensive items, from any brand, any category, and with natural language queries.
In this tutorial, we are going to be using MongoDB Atlas, the PyMongoArrow library, MongoDB Atlas Vector Search, and a luxury fashion dataset from Kaggle.
Before we dive in, let’s first cover some of the important aspects of what will help us achieve our overall outcome.
PyMongoArrow is a Python library for data analysis with MongoDB. Due to our dataset being a
.csv file, we are going to be reading it using the Pandas library, so it’ll be read in as a Pandas dataframe. With the pymongoarrow library, we can export all our data to MongoDB Atlas in the most ideal format for our tutorial with a handful of easy steps. It’s built on top of pymongo, so it allows us to work with MongoDB data in a super easy and performant manner. As you work through this tutorial, you’ll see how simple transferring your data and configuring it becomes when using the pymongoarrow library, an issue many data developers have dealt with in the past.MongoDB Atlas Vector Search has truly revolutionized search capabilities. It lets you easily search semantically through your database while keeping your vector embeddings in the same place as your source data. Searching semantically means to search by meaning, so instead of having to search using exact keywords, we can query and receive results that convey the same idea without the precise wording.
For example, instead of searching through our sample size using simple queries such as “dress,” we can actually use phrases or generalities, like “summer beach tropical” or just even “summer.” We are going to be utilizing the
$vectorSearch aggregation stage in this tutorial, which simplifies using Atlas Vector Search even more.Vamos começar!
- IDE of your choosing — this tutorial uses Google Colab. Feel free to run the commands directly in the notebook.
- A MongoDB Atlas account
- An OpenAI API key — this is how we will be embedding our data prior to uploading it into MongoDB Atlas.
Once your cluster has been created and you’ve downloaded the dataset locally, you’re ready to begin!
Our first step is to upload our 
.csv file into Google Colab. On the left-hand side of Google Colab, access the "Files" section. Select the downloaded net-a-porter.csv file and upload.
Once your file is uploaded, we need to do two important things:
- We need to use OpenAI to create embeddings on each item in our file.
- We need to clean up our dataset and reconfigure it into a format best suited for our end goal, which is to ensure we can use semantic search to find items in our database.
If you take a look at your 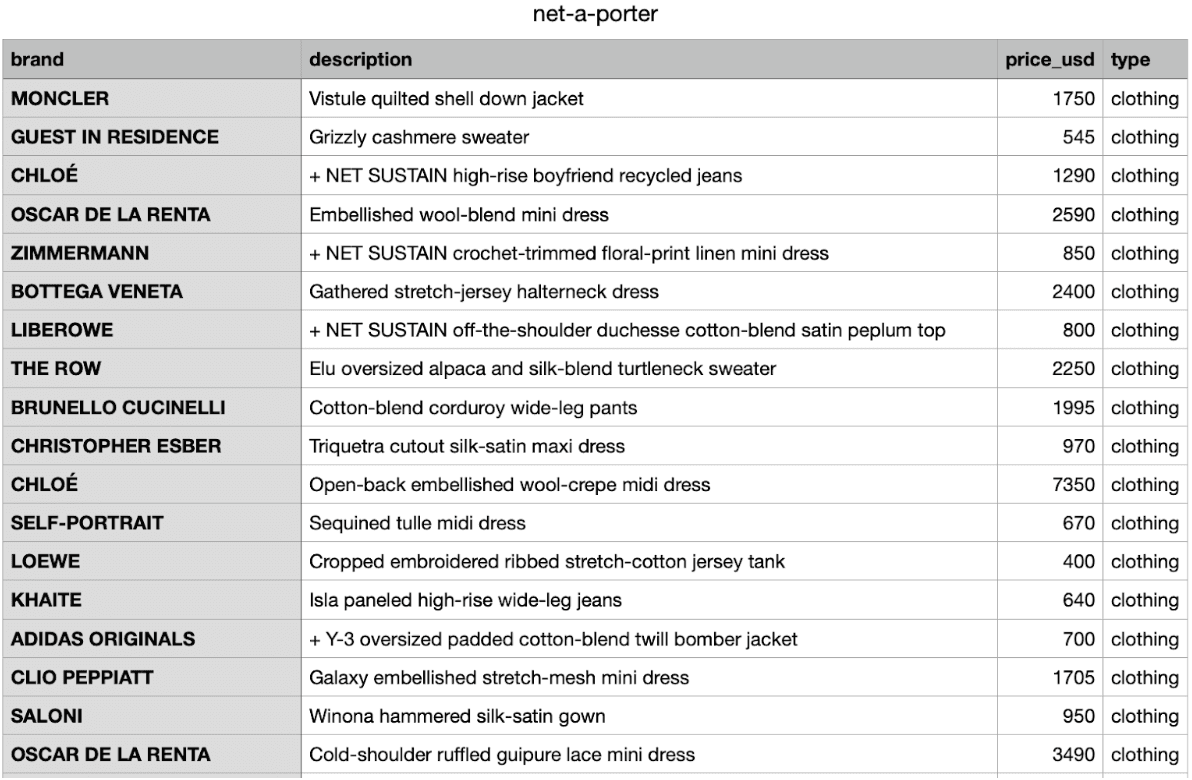
.csv file, you’ll notice it consists of four columns (brand, description, price_usd, type) and a multitude of rows.
We need to add a column in our dataframe that contains the embeddings for our item descriptions. To embed each item description, we will use the “text-embedding-3-small” embedding model, and this embedding function:
1 def get_embedding(text): 2 embedding = openai.embeddings.create(input=text, model=EMBEDDING_MODEL).data[0].embedding 3 return embedding
We also need to use the
pandas library to work with the data we have on hand. Pandas is a Python library used for working with data sets, and it’s super crucial when analyzing, cleaning, exploring, and manipulating data.To start off, we want to install our dependencies. This means installing
openai and importing pandas.1 !pip install openai 2 import pandas as pd 3 import openai
Now, we need to grab our OpenAI secret key. Make sure to save your key somewhere safe and do not share it anywhere, as it’s very sensitive. In this tutorial, to keep things simple and demonstrate other functionalities available, we are hard-coding in our API key, but in production or anywhere else, it’s important to store your sensitive values in a
.env file.Copy in your key and the embedding function from above:
1 # we need our openai secret key 2 openai.api_key = 'OPENAI-APIKEY' 3 4 5 # we are going to use this embedding model for text 6 EMBEDDING_MODEL = "text-embedding-3-small" 7 8 9 # this is the embedding function we will use to create our embeddings for the descriptions 10 def get_embedding(text): 11 embedding = openai.embeddings.create(input=text, model=EMBEDDING_MODEL).data[0].embedding 12 return embedding
We’ve set ourselves up for success with processing our embeddings, so let’s go ahead and configure our dataframe!
First, we want to read in the file that was just uploaded:
1 # we want to read in our file that we just uploaded 2 df = pd.read_csv('/content/net-a-porter.csv')
We only want to focus on the first three columns, since we don’t necessarily need the
type column, so let’s drop it:1 # drop the 'type' column 2 df.drop(columns=['type'], inplace=True)
It’s important to make sure that the columns we are dealing with are clean and don’t have any null values. This is crucial because null values can mess up our data in the long run, and it’s a good practice to always ensure you’re working with a clean dataset. To do this, use
dropna:1 # this is just saying to drop null values from our specific subsets, we want 'brand', price_usd', and 'description' 2 df.dropna(subset=['brand', 'price_usd', 'description'], inplace=True)
To ensure we are not spending a ton of money and time embedding each and every description in our large dataset, let’s slice it down to 100 rows. This will still provide us with an interesting sample size, but it won’t take up too many resources:
1 # cut our entire file down to just 100 rows so that we don't spend a million dollars embedding the file 2 df = df.head(100)
Now, we’re ready to create a new column for where our embeddings will go, and then we can print out our first 20 rows just to ensure we’re on the right track:
1 # this is creating a new column with the embeddings 2 df["description_embedding"] = df['description'].apply(get_embedding) 3 4 5 # this is going to give us the first twenty rows from our file 6 print(df.head(20))
This should be your output, with the new 
description_embedding column:
As you can see, we have a dataframe with the columns we need, and specifically, our newly included
description_embedding column! Let’s make sure we can save this into our cluster so we can use MongoDB Atlas Vector Search when we’re ready to do so.Since
pymongoarrow uses Apache Arrow behind the scenes, to move our data into MongoDB Atlas, we need to convert our Pandas dataframe into an Arrow table. The great part of Arrow tables is that they allow for nested columns, so if we had a more complicated dataset, we wouldn’t need to jump through too many hoops to accommodate nesting.Now that we have all our items and embeddings, let’s use
pymongoarrow to import all of our data into MongoDB Atlas. Use a pip command to install pymongo, pymongoarrow, e pyarrow.1 !pip install pymongo pymongoarrow pyarrow
Once that succeeds, we can sort our items by most expensive to least expensive (just for fun) and then we can import all our items into our cluster. Please ensure you have your MongoDB connection string on hand so you can connect to your cluster and do this step. While we are hard-coding this in for this tutorial, please keep in mind that it’s not secure and variables should always be stored in a separate file.
Copy the code below to do this:
1 from pymongo import MongoClient 2 from pymongoarrow.api import write 3 import pyarrow as pa 4 5 6 # I want to sort by most expensive item to least expensive 7 df = df.sort_values(by=['price_usd'], ascending=False) 8 9 10 # this is your connection to your cluster 11 connection_string = "MONGODB-CONNECTION-STRING" 12 client = MongoClient(connection_string) 13 14 15 # you can name your database and collection anything you like 16 database = client['net-a-porter'] 17 collection = database['average_prices_descending'] 18 19 20 # in order to save our data, we need to first convert our Pandas DataFrame to an Arrow Table using pyarrow 21 arrow_table = pa.Table.from_pandas(df) 22 23 24 write(collection, arrow_table) 25 26 27 print("Successful") 28 print(arrow_table)
Once you run this code block, be sure to double-check in MongoDB Atlas that everything looks as expected. The rows from your
.csv file will have been transformed into separate documents, with each column as a new field. Make sure that your new description_embedding field is included as well!
Now that we have our embedded documents in place, we can set up MongoDB Atlas Vector Search.
Let’s start searching semantically through our newly imported data.
We first need to create a Vector Search index. To do this, head into your Atlas account and follow the steps.
Once finished, it should look like this.
1 { 2 "fields": [ 3 { 4 "numDimensions": 1536, 5 "path": "description_embedding", 6 "similarity": "cosine", 7 "type": "vector" 8 } 9 ] 10 }
The path we are using is
description_embedding since we want our Vector Search index to be used against our newly incorporated embedding column. For the similarity field, we are choosing “euclidean,” but depending on your use case, you can either use “cosine” or “dot-product.”Keep your “Index Name” as “vector_index,” or change it to something that you’ll remember, but make sure you’ve selected the correct database and collection. Once you’ve saved your index and it’s uploaded, you’ll know it’s active when the status looks like this.
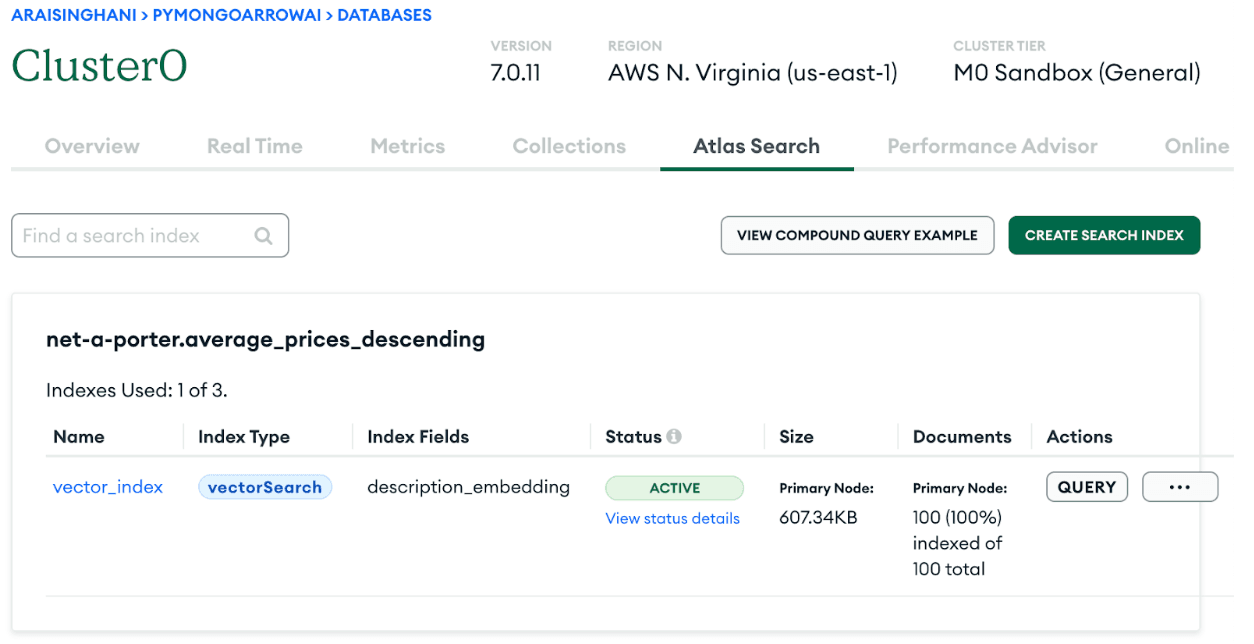
Keep in mind that your Vector Search index is isolated to MongoDB Atlas. It is not a part of your overall Python script and you should not be running the index in your script.
Now, go back to the Google Colab file. To search semantically, we need to embed our queries. This is a very important part: When we are using semantic search, we are not comparing vectors to text — we are comparing vectors to vectors!
Do this with these couple of lines:
1 # my query 2 query_description = "summer" 3 4 5 # we need to embed the query as well, since our documents are embedded 6 query_vector = get_embedding(query_description)
Since we’ve already used the embedding model above, it doesn’t take much work to embed our queries as well.
Now, we need to define the aggregation pipeline so that we can semantically search. We can do this using
$vectorSearch.
The pipeline looks like this:1 # write the aggregation pipeline 2 pipeline = [ 3 { 4 '$vectorSearch': { 5 'index': 'vector_index', 6 'path': 'description_embedding', 7 'queryVector': query_vector, 8 # I only had 100 rows saved so that it's easier to use OpenAI 9 'numCandidates': 100, 10 'limit': 5 11 } 12 }, 13 { 14 '$project': { 15 # i do not need to see the ID, but I do want to see my other columns. 16 '_id': 0, 17 'brand': 1, 18 'description': 1, 19 'price_usd': 1, 20 'score': { 21 '$meta': 'vectorSearchScore' 22 } 23 } 24 }, 25 { 26 '$sort': { 27 'price_usd': -1 # sort by most expensive to least expensive 28 } 29 } 30 ]
As you can see, we have used the
$project feature to only show the fields that we want. We’ve also used $vectorSearch to define the index, the path, and our query vector. Double-check to ensure all the fields are correct before you proceed. Otherwise, it will not run.Once your pipeline has been written, define which database and collection you want it to run on, and then print your results:
1 # the pipeline is run on this database and collection 2 database = client['net-a-porter'] 3 collection = database['average_prices_descending'] 4 result = collection.aggregate(pipeline) 5 6 7 8 9 for clothing in result: 10 print(clothing)
In this tutorial we used the simple query of “summer” and these are our results:

It’s interesting here because when I queried on “summer,” items that included summer months showed up, such as the month of August.
Let’s change our query to say “winter” and see the results. As you can see, out of our sample size, we are pulling up results that are oriented toward colder weather, such as coats, ski jackets, and wool pants.

They are also sorted in descending order from most expensive to least (to dream!) and we can search through the items with limited scrolling. So, if you’re ever in ultimate lounging mode and need a cashmere-hoodie-and-sweatpants ‘fit that’ll set you back almost $1300 (before tax), you know where to look.
While this tutorial was done using a flat dataset, once you truly understand the concepts around how to incorporate the platforms and libraries introduced, feel free to create a web scraper and try this same method on live data.
This tutorial gives you a great overview of what is possible with PyMongoArrow and MongoDB Atlas Vector Search. We were able to take a dataset, process it using Pandas, generate necessary embeddings with OpenAI, store our newly developed Arrow table into MongoDB Atlas using PyMongoArrow, and then semantically query on our database.
For more information on PyMongoArrow, please visit the documentation, and for more information on MongoDB Atlas Vector Search, explore the tutorial. If you have questions or want to share your work, join us in the MongoDB Developer Community.
Principais comentários nos fóruns

Arya_BhaskaraArya Bhaskara2 weeks ago
Thank you! It’s very insightful.