Para obter os dados necessários para renderizar um gráfico, o Charts cria um MongoDB Aggregation Pipeline e executa o pipeline no servidor de banco de dados de dados MongoDB . O pipeline consiste em vários estágios, cada um dos quais é gerado com base em diferentes configurações especificadas pelo autor do gráfico.
Este documento explica como as várias configurações do Construtor de Gráficos são usadas para construir o Aggregation Pipeline. Você pode visualizar o pipeline usado para criar um gráfico escolhendo a opção View Aggregation Pipeline no menu suspenso de reticências do Construtor de gráficos no canto superior direito.
Os Atlas Charts constroem um pipeline que consiste nos seguintes segmentos na seguinte ordem:
Observação
Ao criar um gráfico, você pode configurar alguns, mas não todos os segmentos de gráfico anteriores. Quando o Charts gera o pipeline de agregação , ele ignora segmentos não especificados.
Exemplo
O gráfico a seguir mostra os valores totais de venda de uma empresa de suprimentos de escritório, categorizados pelo método de compra. Cada documento na collection de dados representa uma única venda.
Usando este gráfico como exemplo, exploraremos como as especificações de cada uma das configurações acima alteram o pipeline de agregação gerado pelos Atlas Charts.

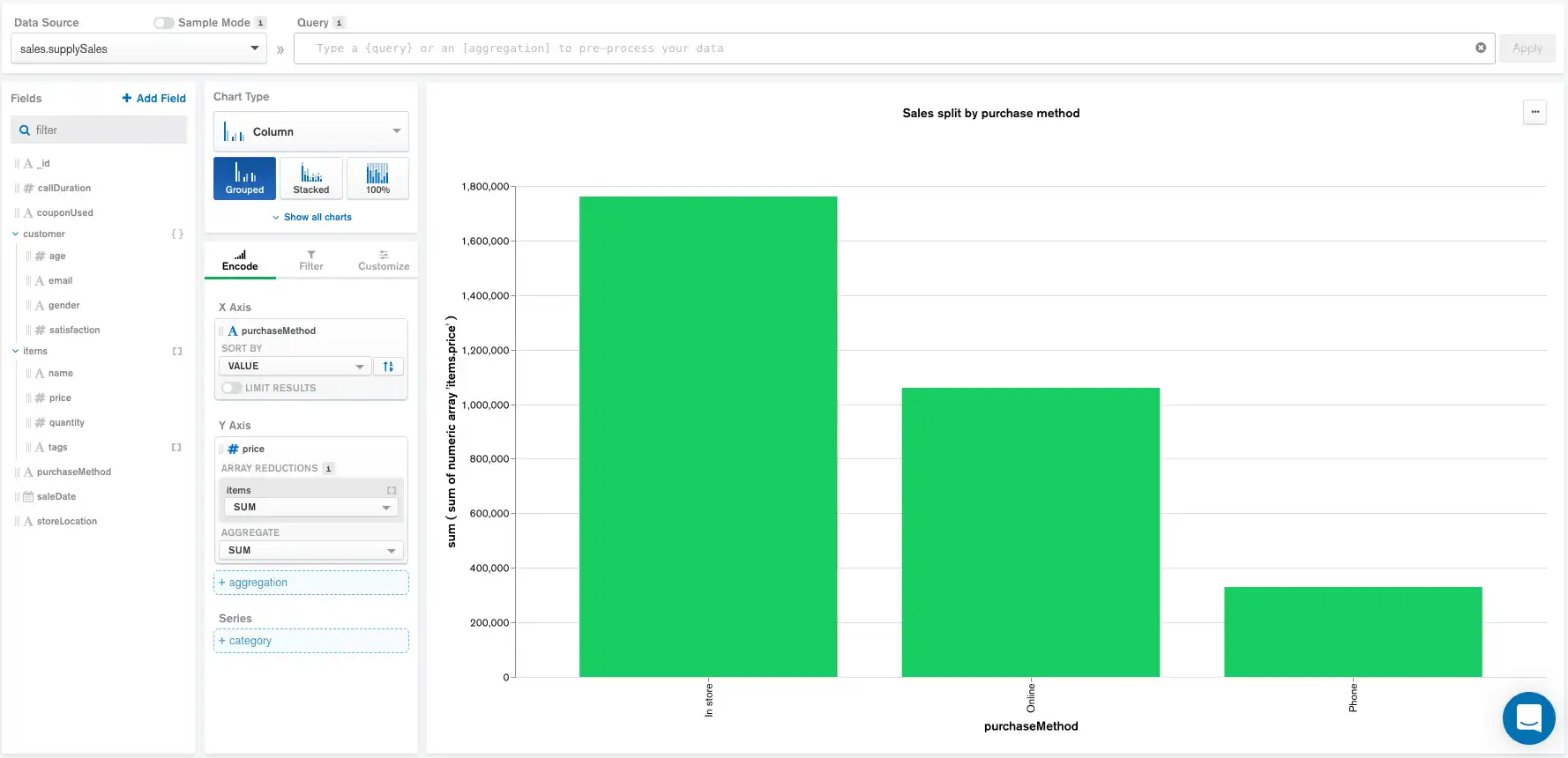
Codificação
Sem nenhum pipeline Data Source , query de barra Query , campo calculados e filtros adicionados no painel Filter , o Charts gera o seguinte pipeline de agregação:
1 { 2 "$addFields": { // Encoding 3 "__alias_0": { 4 "$sum": "$items.price" 5 } 6 } 7 }, 8 { 9 "$group": { 10 "_id": { 11 "__alias_1": "$purchaseMethod" 12 }, 13 "__alias_0": { 14 "$sum": "$__alias_0" 15 } 16 } 17 }, 18 { 19 "$project": { 20 "_id": 0, 21 "__alias_1": "$_id.__alias_1", 22 "__alias_0": 1 23 } 24 }, 25 { 26 "$project": { 27 "x": "$__alias_1", 28 "y": "$__alias_0", 29 "_id": 0 30 } 31 }, 32 33 { 34 "$addFields": { // Sorting 35 "__agg_sum": { 36 "$sum": [ 37 "$y" 38 ] 39 } 40 } 41 }, 42 { 43 "$sort": { 44 "__agg_sum": -1 45 } 46 }, 47 { 48 "$project": { 49 "__agg_sum": 0 50 } 51 }, 52 { 53 "$limit": 5000 54 }
O pipeline neste ponto consiste em grupos do painel Encode , estágios para a ordem de classificação padrão e o limite máximo de documentos, que é definido como 5000 pelo Atlas Charts.
Adicionando query
A query abaixo restringe os documentos exibidos somente àqueles com um saleDate igual ou mais recente a January 1, 2017 com pelo menos 5 elementos na array items . items é uma matriz onde cada elemento é um item comprado durante uma venda.
Query:
{ $and: [ { saleDate: { $gte: new Date("2017-01-01") } }, { 'items.4': { $exists: true } } ] }
A aplicação da query acima na barra Query gera o seguinte gráfico e pipeline de agregação:

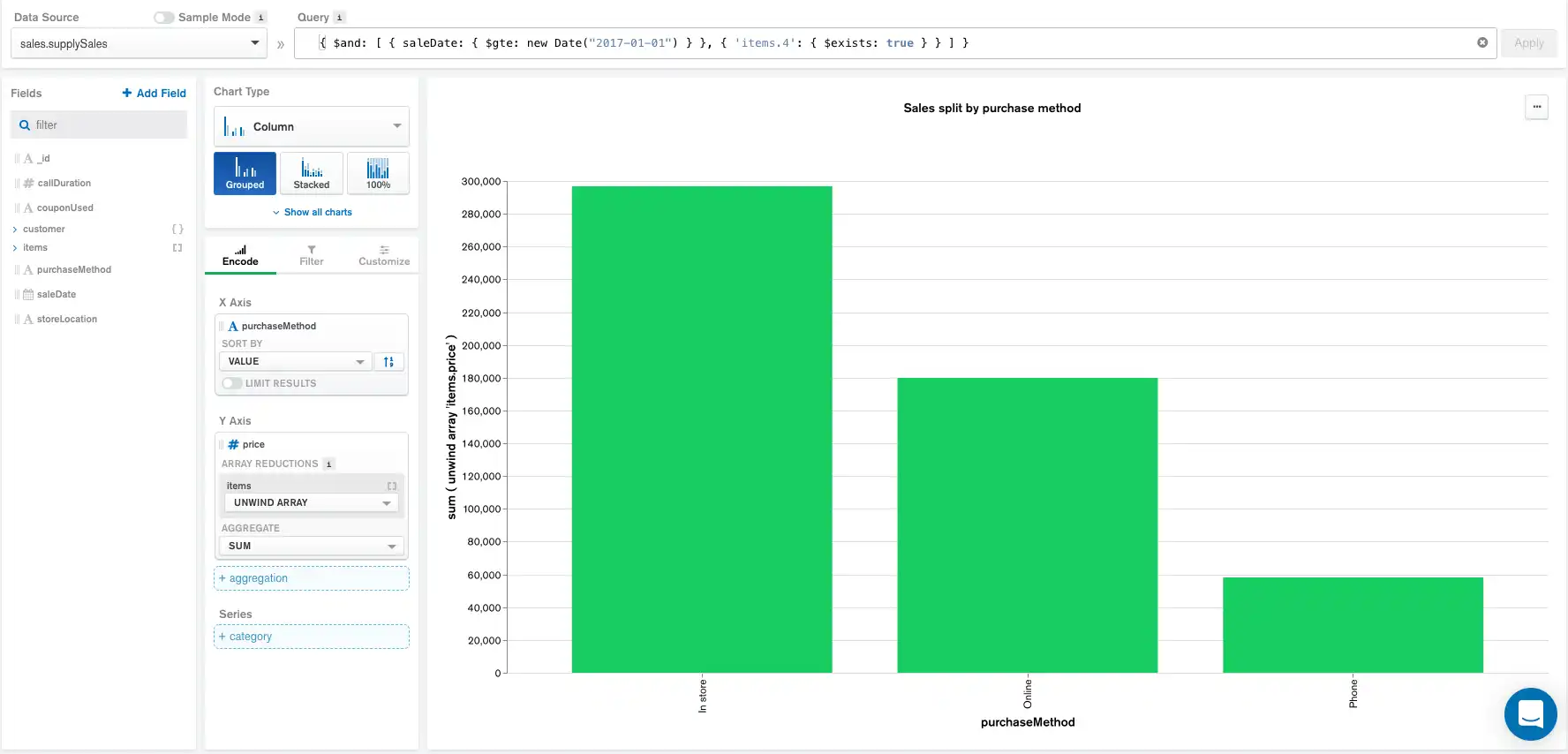
Aggregation pipeline:
1 { 2 "$match": { // Query 3 "$and": [ 4 { 5 "saleDate": { 6 "$gte": { 7 "$date": "2017-01-01T00:00:00Z" 8 } 9 } 10 }, 11 { 12 "items.4": { 13 "$exists": true 14 } 15 } 16 ] 17 } 18 }, 19 { 20 "$addFields": { 21 "__alias_0": { 22 "$sum": "$items.price" 23 } 24 } 25 }, 26 { 27 "$group": { 28 "_id": { 29 "__alias_1": "$purchaseMethod" 30 }, 31 "__alias_0": { 32 "$sum": "$__alias_0" 33 } 34 } 35 }, 36 { 37 "$project": { 38 "_id": 0, 39 "__alias_1": "$_id.__alias_1", 40 "__alias_0": 1 41 } 42 }, 43 { 44 "$project": { 45 "x": "$__alias_1", 46 "y": "$__alias_0", 47 "_id": 0 48 } 49 }, 50 { 51 "$addFields": { 52 "__agg_sum": { 53 "$sum": [ 54 "$y" 55 ] 56 } 57 } 58 }, 59 { 60 "$sort": { 61 "__agg_sum": -1 62 } 63 }, 64 { 65 "$project": { 66 "__agg_sum": 0 67 } 68 }, 69 { 70 "$limit": 5000 71 }
O aggregation pipeline agora começa com a query aplicada e é seguido pelos grupos selecionados no painel Encode e pelo limite máximo de documentos.
Adicionando campos calculados
Também podemos alterar o gráfico para mostrar a receita total gerada categorizada pelo método de compra. Para realizar esta tarefa, criaremos um campo calculado que calcula a receita total multiplicando o preço pela quantidade. Adicionar esse novo campo calculado, além da query acima, produz o seguinte gráfico e pipeline:
Expressão de campo calculada:

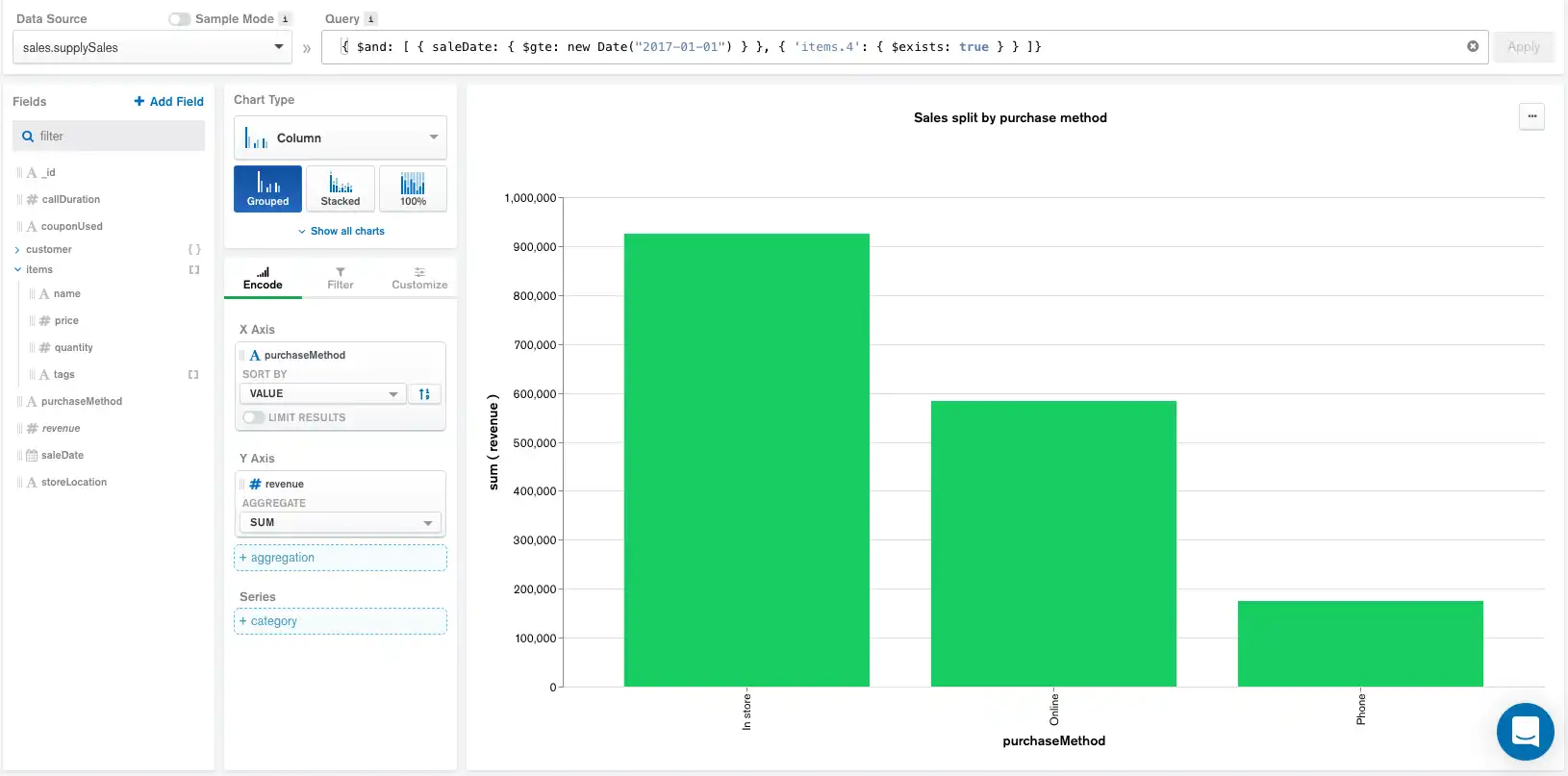
Aggregation pipeline:
1 { 2 "$match": { 3 "$and": [ 4 { 5 "saleDate": { 6 "$gte": { 7 "$date": "2017-01-01T00:00:00Z" 8 } 9 } 10 }, 11 { 12 "items.4": { 13 "$exists": true 14 } 15 } 16 ] 17 } 18 }, 19 { 20 "$addFields": { // Calculated Field 21 "revenue": { 22 "$reduce": { 23 "input": "$items", 24 "initialValue": 0, 25 "in": { 26 "$sum": [ 27 "$$value", 28 { 29 "$multiply": [ 30 "$$this.price", 31 "$$this.quantity" 32 ] 33 } 34 ] 35 } 36 } 37 } 38 } 39 }, 40 { 41 "$group": { 42 "_id": { 43 "__alias_0": "$purchaseMethod" 44 }, 45 "__alias_1": { 46 "$sum": "$revenue" 47 } 48 } 49 }, 50 { 51 "$project": { 52 "_id": 0, 53 "__alias_0": "$_id.__alias_0", 54 "__alias_1": 1 55 } 56 }, 57 { 58 "$project": { 59 "x": "$__alias_0", 60 "y": "$__alias_1", 61 "_id": 0 62 } 63 }, 64 { 65 "$addFields": { 66 "__agg_sum": { 67 "$sum": [ 68 "$y" 69 ] 70 } 71 } 72 }, 73 { 74 "$sort": { 75 "__agg_sum": -1 76 } 77 }, 78 { 79 "$project": { 80 "__agg_sum": 0 81 } 82 }, 83 { 84 "$limit": 5000 85 }
O pipeline atualizado agora inclui o campo calculado logo abaixo da query aplicada na barra Query , enquanto a ordem do restante dos componentes permanece inalterada.
Adicionando filtros
Esse gráfico pode ser ainda mais refinado com a adição de um filtro no painel Filter para selecionar somente as vendas na loja feitas em Nova York. Adicionar este filtro produz o seguinte gráfico e pipeline de agregação:

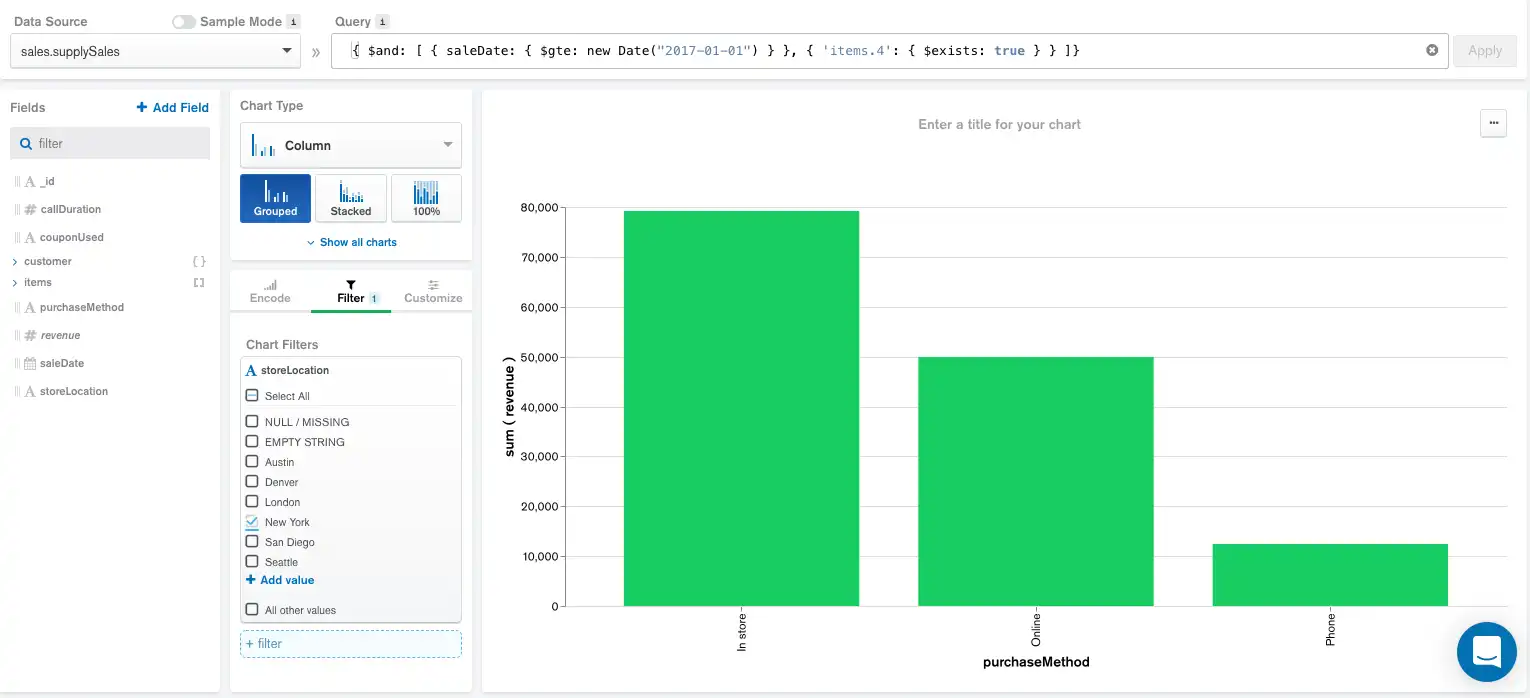
Aggregation pipeline:
1 { 2 "$match": { 3 "$and": [ 4 { 5 "saleDate": { 6 "$gte": { 7 "$date": "2017-01-01T00:00:00Z" 8 } 9 } 10 }, 11 { 12 "items.4": { 13 "$exists": true 14 } 15 } 16 ] 17 } 18 }, 19 { 20 "$addFields": { 21 "revenue": { 22 "$reduce": { 23 "input": "$items", 24 "initialValue": 0, 25 "in": { 26 "$sum": [ 27 "$$value", 28 { 29 "$multiply": [ 30 "$$this.price", 31 "$$this.quantity" 32 ] 33 } 34 ] 35 } 36 } 37 } 38 } 39 }, 40 { 41 "$match": { // Filter 42 "storeLocation": { 43 "$in": [ 44 "New York" 45 ] 46 } 47 } 48 }, 49 { 50 "$group": { 51 "_id": { 52 "__alias_0": "$purchaseMethod" 53 }, 54 "__alias_1": { 55 "$sum": "$revenue" 56 } 57 } 58 }, 59 { 60 "$project": { 61 "_id": 0, 62 "__alias_0": "$_id.__alias_0", 63 "__alias_1": 1 64 } 65 }, 66 { 67 "$project": { 68 "x": "$__alias_0", 69 "y": "$__alias_1", 70 "_id": 0 71 } 72 }, 73 { 74 "$addFields": { 75 "__agg_sum": { 76 "$sum": [ 77 "$y" 78 ] 79 } 80 } 81 }, 82 { 83 "$sort": { 84 "__agg_sum": -1 85 } 86 }, 87 { 88 "$project": { 89 "__agg_sum": 0 90 } 91 }, 92 { 93 "$limit": 5000 94 }
O pipeline agora inclui o filtro storeLocation logo abaixo do campo calculado, enquanto a ordem do restante dos componentes permanece inalterada.