O Data Explorer fornece um construtor de pipeline de agregação para processar seus dados. Os aggregation pipelines transformam seus documentos em resultados agregados com base em estágios de pipeline selecionados.
O construtor de pipeline de agregação do MongoDB Atlas é projetado principalmente para criar pipelines, em vez de executá-los. O construtor de pipeline oferece uma maneira fácil de exportar sua pipeline para ser executada em um driver.
Acessar dados
Para interagir com seus dados na UI do Cloud Manager :
No MongoDB Cloud Manager, acesse aGo Processes página do seu projeto.
Se ainda não tiver sido exibido, selecione a organização que contém seu projeto no menu Organizations na barra de navegação.
Se ainda não estiver exibido, selecione o projeto desejado no menu Projects na barra de navegação.
Na barra lateral, clique em Processes sob o título Database.
A página Processos é exibida.
Funções obrigatórias
Para criar e executar pipelines de agregação no Data Explorer, você deve ter recebido pelo menos o role Project Data Access Read Only .
Para utilizar o estágio $out em seu pipeline, você deve ter recebido pelo menos a função Project Data Access Read/Write .
Acessar o Construtor de Pipeline de Agregação

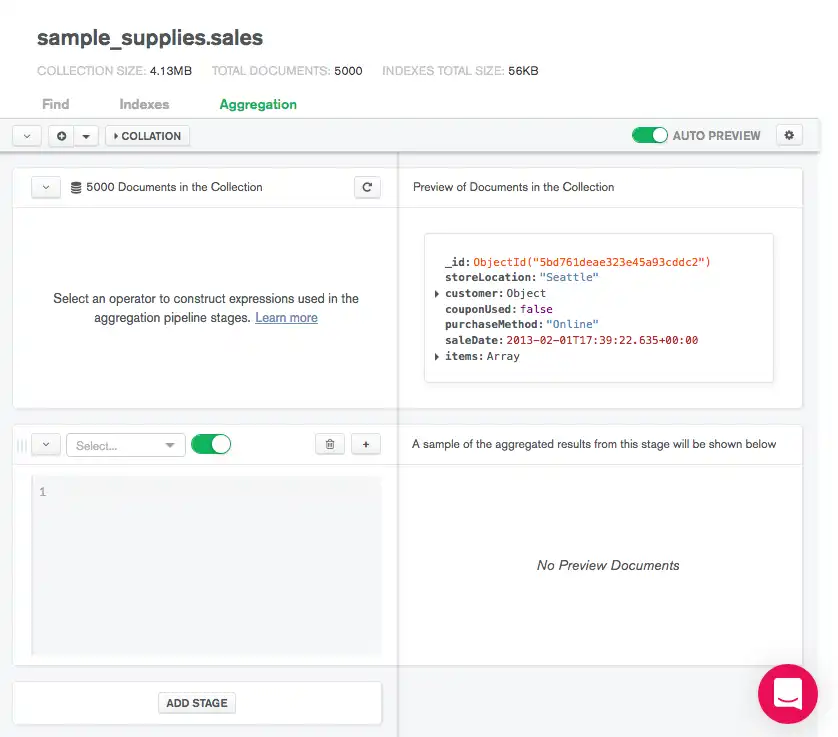
Criar um pipeline de agregação

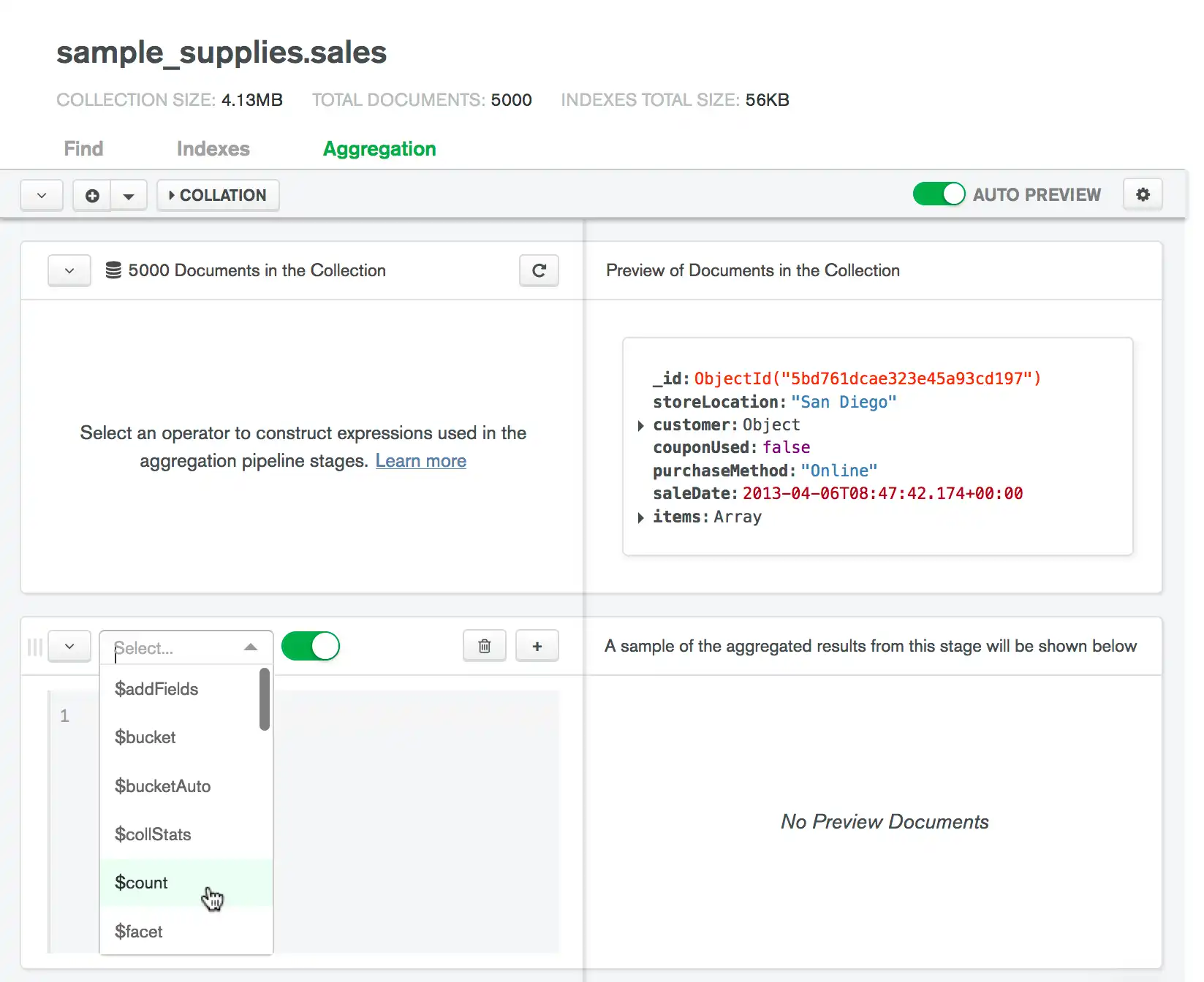
Preencha seu estágio de agregação.
Preencha seu estágio com os valores apropriados. Se o Modo de Comentário estiver habilitado, o construtor de pipeline fornecerá diretrizes sintáticas para o estágio selecionado.
À medida que você modifica seu estágio, o Data Explorer atualiza os documentos de visualização à direita com base nos resultados do estágio atual.

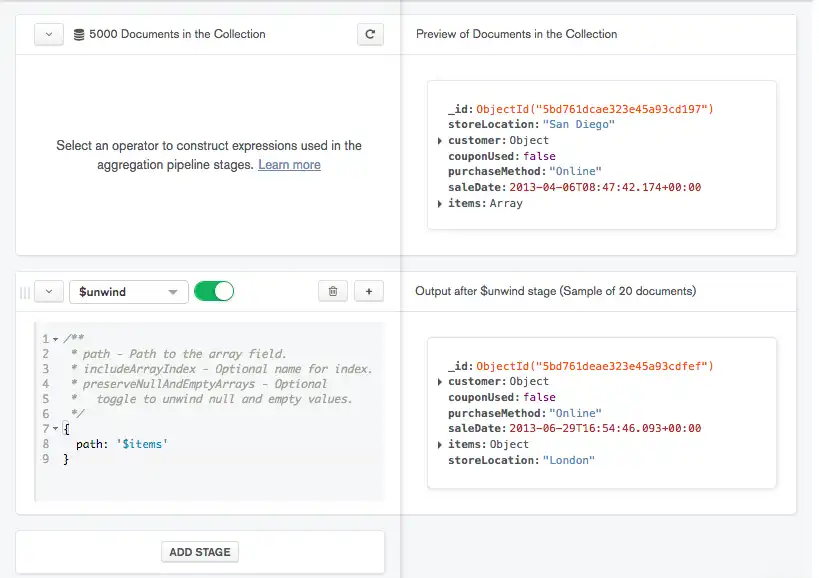
Adicione estágios adicionais ao seu pipeline conforme desejado.
Há duas maneiras de adicionar estágios adicionais ao seu pipeline:
Clique no botão Add Stage na parte inferior do pipeline para adicionar um novo estágio no final do pipeline:
Clique no botão em um estágio para adicionar um novo estágio diretamente após o estágio em que o botão foi clicado.

Para excluir uma etapa do pipeline, clique em ícone no estágio desejado.
Agrupamentos
Use o agrupamento para especificar regras específicas do idioma para comparação de strings, como regras para letras maiúsculas e acentos.
Para especificar um documento de agrupamento, clique em Collation na parte superior do construtor de pipeline.
Um documento de agrupamento tem os seguintes campos:
{ locale: <string>, caseLevel: <boolean>, caseFirst: <string>, strength: <int>, numericOrdering: <boolean>, alternate: <string>, maxVariable: <string>, backwards: <boolean> }
O campo locale é obrigatório; todos os outros campos de compilação são opcionais. Para obter descrições dos campos, consulte Documento de agrupamento.
Importar um Pipeline de Agregação do Texto
Você pode importar pipelines de agregação de texto sem formatação para o construtor de pipelines para modificar e verificar facilmente seus pipelines.
Para importar um pipeline de texto sem formatação:

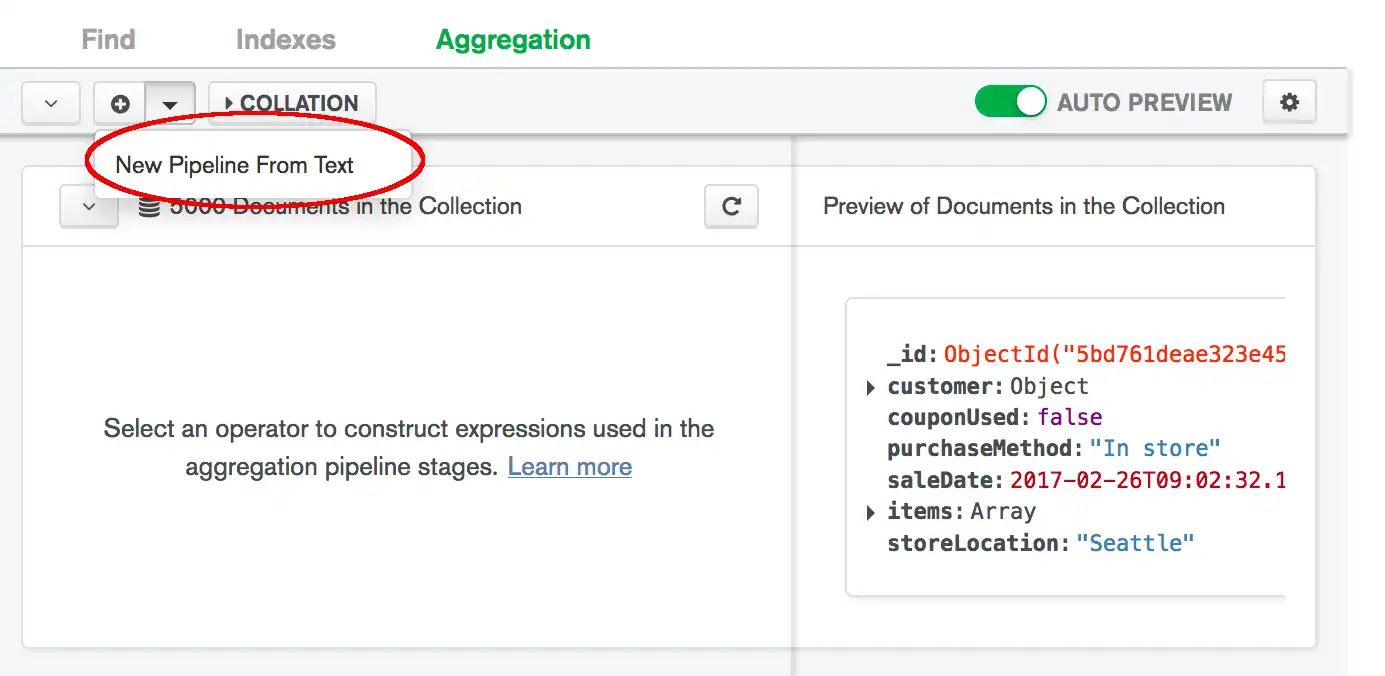
Digite ou cole seu pipeline na caixa de diálogo.
Seu pipeline deve corresponder à sintaxe do parâmetro pipeline do método db.collection.aggregate().
Redefinir Seu Pipeline
Para retornar seu pipeline ao estado inicial em branco, clique no ícone de "mais" na parte superior do construtor de pipeline.
Exportar um pipeline de agregação para o idioma do acionador
Você pode usar o construtor de pipeline de agregação para exportar seu pipeline finalizado para uma das linguagens de driver compatíveis; Java, Nó, C# e Python 3. Use esse recurso para formatar e exportar pipelines para usar em seus aplicativos.
Para exportar seu aggregation pipeline:
Construir um pipeline de agregação.
Para obter instruções sobre como criar um pipeline de agregação, consulte Criar um pipeline de agregação.
Selecione o idioma de exportação desejado.
No menu suspenso Export Pipeline To, selecione o idioma desejado.
O painel My Pipeline à esquerda exibe seu pipeline na sintaxe mongosh.
O painel à direita exibe seu pipeline no idioma selecionado.
Configurações do pipeline de agregação
Para modificar as configurações do construtor de pipeline de agregação:


Modifique as configurações do pipeline conforme desejado.
Você pode modificar as seguintes configurações:
Contexto | Descrição | Default |
|---|---|---|
Comment Mode | Quando ativado, o Data Explorer adiciona comentários auxiliares a cada estágio. A alteração dessa configuração afeta apenas novos estágios e não modifica os estágios que já foram adicionados ao seu pipeline. | Ligado |
Number of Preview Documents | Quantidade de documentos a serem exibidos na visualização de cada estágio. | 20 |