Visão geral
Neste guia, você aprenderá a armazenar e extrair arquivos grandes no MongoDB usando a especificação GridFS. O GridFS divide arquivos grandes em blocos e armazena cada bloco como um documento separado. Quando você consulta o GridFS para um arquivo, o driver monta os blocos conforme necessário. A implementação de driver do GridFS é uma abstração que gerencia as operações e a organização do armazenamento de arquivos.
Use o GridFS se o tamanho dos seus arquivos exceder o limite de tamanho de documento BSON de 16 MB. O GridFS também ajuda a acessar arquivos sem carregar todo o arquivo na memória. Para saber mais sobre se o GridFS é adequado para seu caso de uso, consulte GridFS no manual do servidor.
Como funciona o GridFS
O GridFS organiza arquivos em um bucket, um grupo de coleções do MongoDB que contêm os blocos de arquivos e as informações que os descrevem. O bucket contém as seguintes coleções:
chunks, que armazena as partes de arquivos bináriosfiles, que armazena os metadados do arquivo
Quando você cria um novo bucket GridFS, o driver cria as coleções anteriores. O nome de bucket padrão fs pré-estabelece os nomes da coleção, a menos que você especifique um nome de bucket diferente. O driver cria o novo bucket GridFS durante a primeira operação de gravação.
O driver também cria um índice em cada coleção para garantir a recuperação eficiente de arquivos e metadados relacionados. O driver cria índices se eles ainda não existem e quando o bucket está vazio. Para saber mais sobre índices GridFS, consulte Índices GridFS no manual do servidor.
Ao armazenar arquivos com GridFS, o driver divide os arquivos em partes menores, cada um representado por um documento separado na coleção do chunks. Ele também cria um documento na coleção files que contém um ID de arquivo, nome de arquivo e outros metadados de arquivo. O diagrama a seguir mostra como o GridFS divide os arquivos carregados:

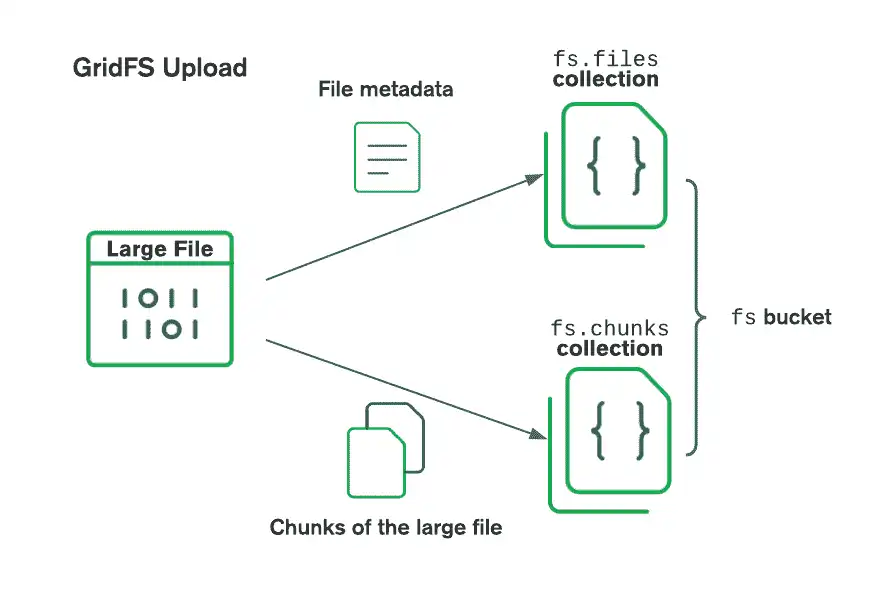
Ao recuperar arquivos, o GridFS obtém os metadados da coleção files no bucket especificado, e depois utiliza essas informações para reconstruir o arquivo a partir de documentos na coleção chunks. Você pode ler o arquivo na memória ou enviá-lo para um fluxo.
Operações GridFS
As seções abaixo descrevem como executar operações GridFS:
Crie um intervalo GridFS
Para armazenar ou recuperar arquivos do GridFS, crie um bucket ou obtenha uma referência a um bucket existente em um banco de dados MongoDB. Para criar uma instância do GridFSBucket, chame o método GridFSBucket() em uma instância de Database, conforme indicado no código abaixo:
db := client.Database("myDB") bucket := db.GridFSBucket()
Observação
Se um contêiner GridFS já existir, o método GridFSBucket() retornará uma referência ao contêiner em vez de instanciar um novo.
Por padrão, o driver define o nome do bucket como fs. Para criar um bucket com um nome personalizado, chame o método SetName() em uma instância do BucketOptions, conforme indicado no código abaixo:
db := client.Database("myDB") bucketOpts := options.GridFSBucket().SetName("myCustomBucket") bucket := db.GridFSBucket(bucketOpts)
Fazer upload de arquivos
Você pode carregar um arquivo em um bucket GridFS usando um dos seguintes métodos:
UploadFromStream(), que lê de um fluxo de entradaOpenUploadStream(), que grava em um fluxo de saída
Para qualquer processo de carregamento, você pode especificar as informações de configuração criando uma instância do UploadOptions. Para ver uma lista completa das opções disponíveis, consulte a documentação da API UploadOptions.
Fazer upload com um fluxo de entrada
Para carregar um arquivo com um fluxo de entrada, use o método UploadFromStream() e inclua os seguintes parâmetros:
Nome do arquivo
io.Readerinstância, incluindo seu arquivo aberto como parâmetrooptsparâmetro para modificar o comportamento deUploadFromStream()
O exemplo de código abaixo lê a partir de um arquivo denominado file.txt, cria um parâmetro opts para configurar metadados de arquivo e transfere o conteúdo para um bucket GridFS:
file, err := os.Open("home/documents/file.txt") uploadOpts := options.GridFSUpload().SetMetadata(bson.D{{"metadata tag", "first"}}) objectID, err := bucket .UploadFromStream( "file.txt", io.Reader(file), uploadOpts ) if err != nil { panic(err) } fmt.Printf("New file uploaded with ID %s", objectID)
New file uploaded with ID ...
Fazer upload com um fluxo de saída
Para carregar um arquivo com um fluxo de saída, use o método OpenUploadStream() e inclua os seguintes parâmetros:
Nome do arquivo
optsparâmetro para modificar o comportamento deOpenUploadStream()
O exemplo de código abaixo abre um fluxo de carregamento em um bucket GridFS e define o número de bytes em cada parte no parâmetro de opções. Em seguida, ele chama o método Write() no conteúdo de file.txt para gravar seu conteúdo no fluxo:
file, err := os.Open("home/documents/file.txt") if err != nil { panic(err) } // Defines options that specify configuration information for files // uploaded to the bucket uploadOpts := options.GridFSUpload().SetChunkSizeBytes(200000) // Writes a file to an output stream uploadStream, err := bucket.OpenUploadStream("file.txt", uploadOpts) if err != nil { panic(err) } fileContent, err := io.ReadAll(file) if err != nil { panic(err) } var bytes int if bytes, err = uploadStream.Write(fileContent); err != nil { panic(err) } fmt.Printf("New file uploaded with %d bytes written", bytes) // Calls the Close() method to write file metadata if err := uploadStream.Close(); err != nil { panic(err) }
Recuperar informações do arquivo
Você pode recuperar metadados de arquivo armazenados na coleção files do bucket GridFS. Cada documento na coleção files contém as seguintes informações:
ID do arquivo
Comprimento do arquivo
Tamanho máximo da parte
Data e hora de carregamento
Nome do arquivo
metadatadocumento que armazena quaisquer outras informações
Para recuperar dados do arquivo, chame o método Find() em uma instância GridFSBucket. Você pode passar um filtro de query como argumento para Find() para corresponder somente a determinados documentos de arquivo.
Observação
Você deve passar um filtro de queries para o método Find(). Para recuperar todos os documentos na coleção files, passe um filtro de queries vazio para Find().
O exemplo abaixo recupera o nome do arquivo e o comprimento dos documentos em que o valor length é maior que 1500:
filter := bson.D{{"length", bson.D{{"$gt", 1500}}}} cursor, err := bucket.Find(filter) if err != nil { panic(err) } type gridFSFile struct { Name string `bson:"filename"` Length int64 `bson:"length"` } var foundFiles []gridFSFile if err = cursor.All(context.TODO(), &foundFiles); err != nil { panic(err) } for _, file := range foundFiles { fmt.Printf("filename: %s, length: %d\n", file.Name, file.Length) }
Baixar arquivos
Você pode baixar um arquivo GridFS usando um dos seguintes métodos:
DownloadToStream(), que baixa um arquivo para um fluxo de saídaOpenDownloadStream(), que abre um fluxo de entrada
Baixar um arquivo para um fluxo de saída
Você pode baixar um arquivo em um bucket GridFS diretamente para um fluxo de saída usando o método DownloadToStream(). O método DownloadToStream() usa um ID de arquivo e uma instância io.Writer como parâmetros. O método baixa o arquivo com o ID de arquivo especificado e grava na instância io.Writer.
O exemplo a seguir baixa um arquivo e grava em um buffer de arquivo:
id, err := bson.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") fileBuffer := bytes.NewBuffer(nil) if _, err := bucket.DownloadToStream(id, fileBuffer); err != nil { panic(err) }
Baixar um arquivo para um fluxo de entrada
Você pode baixar um arquivo em um bucket GridFS na memória com um fluxo de entrada usando o método OpenDownloadStream(). O método OpenDownloadStream() obtém um ID de arquivo como um parâmetro e retorna um fluxo de entrada do qual você pode ler o arquivo.
O exemplo a seguir baixa um arquivo na memória e lê seu conteúdo:
id, err := bson.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") downloadStream, err := bucket.OpenDownloadStream(id) if err != nil { panic(err) } fileBytes := make([]byte, 1024) if _, err := downloadStream.Read(fileBytes); err != nil { panic(err) }
Renomear arquivos
Você pode atualizar o nome de um arquivo GridFS em seu bucket utilizando o método Rename(). Passe um valor de ID de arquivo e um novo valor de filename como argumentos para Rename().
O exemplo a seguir renomeia um arquivo para "mongodbTutorial.zip":
id, err := bson.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") if err := bucket.Rename(id, "mongodbTutorial.zip"); err != nil { panic(err) }
Excluir arquivos
Você pode remover um arquivo do bucket GridFS usando o método Delete(). Passe um valor de ID de arquivo como argumento para Delete().
O exemplo a seguir exclui um arquivo:
id, err := bson.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") if err := bucket.Delete(id); err != nil { panic(err) }
Excluir um bucket do GridFS
Você pode excluir um bucket GridFS usando o método Drop().
O exemplo de código abaixo remove um bucket GridFS:
if err := bucket.Drop(); err != nil { panic(err) }
Recursos adicionais
Para saber mais sobre o GridFS e armazenamento, consulte as seguintes páginas no manual do servidor:
Documentação da API
Para saber mais sobre os métodos e tipos mencionados neste guia, consulte a documentação da API abaixo: