Visão geral
Neste guia, você pode aprender como armazenar e recuperar arquivos grandes no MongoDB usando o GridFS. O GridFS é uma especificação que descreve como dividir os arquivos em partes durante o armazenamento e remontá-los durante a recuperação. A implementação do driver GridFS gerencia as operações e organização do armazenamento de arquivos.
Use o GridFS se o tamanho do arquivo exceder o limite de tamanho do documento BSON de 16 megabytes. Para obter informações mais detalhadas sobre se o GridFS é adequado para seu caso de uso, consulte a página de manual do servidor GridFS.
Navegue pelas seções a seguir para saber mais sobre as operações e a implementação do GridFS:
Como funciona o GridFS
O GridFS organiza os arquivos em um bucket, um grupo de coleções do MongoDB que contém os blocos de arquivos e as informações descritivas. Os buckets contêm as seguintes coleções, nomeadas usando a convenção definida na especificação GridFS:
A coleção
chunksarmazena os blocos de arquivo binário.A coleção
filesarmazena os metadados do arquivo.
Quando você cria um novo bucket GridFS, o driver cria as coleções chunks e files, prefixadas com o nome de bucket padrão fs, a menos que você especifique um nome diferente. O driver também cria um índice em cada coleção para garantir a recuperação eficiente de arquivos e metadados relacionados. O driver só cria o bucket GridFS na primeira operação de gravação se ele ainda não existir. O driver só cria índices se eles não existirem e quando o bucket estiver vazio. Para obter mais informações sobre os índices do GridFS, consulte a página do manual do servidor em Índices do GridFS.
Ao armazenar arquivos com GridFS, o driver divide os arquivos em partes menores, cada um representado por um documento separado na coleção do chunks. Ele também cria um documento na coleção files que contém um ID de arquivo exclusivo, um nome de arquivo e outros metadados de arquivo. Você pode fazer upload do arquivo da memória ou de um stream. O diagrama a seguir descreve como o GridFS divide os arquivos ao fazer upload para um bucket:

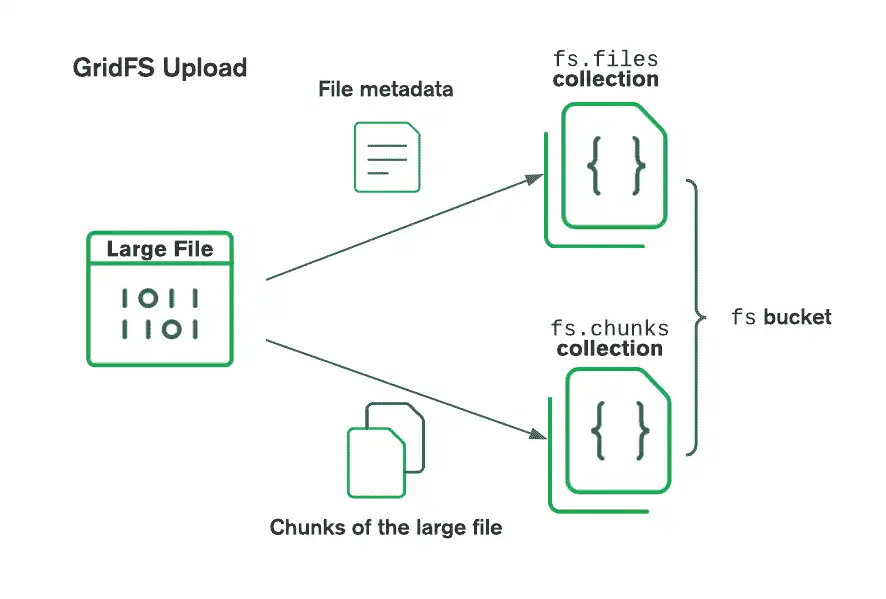
Ao recuperar arquivos, o GridFS obtém os metadados da coleção files no contêiner especificado e utiliza as informações para reconstruir o arquivo a partir de documentos na coleção chunks. Você pode ler o arquivo na memória ou enviá-lo para um fluxo.
Crie um intervalo GridFS
Crie um bucket ou obtenha uma referência a um existente para começar a armazenar ou recuperar arquivos do GridFS. Crie uma instância GridFSBucket , passando um banco de dados como parâmetro. Você pode então usar a instância GridFSBucket para chamar operações de leitura e gravação nos arquivos do seu bucket:
const db = client.db(dbName); const bucket = new mongodb.GridFSBucket(db);
Passe o nome do bloco como o segundo parâmetro para o método create() para criar ou fazer referência a um bloco com um nome personalizado diferente do nome padrão fs, conforme mostrado no exemplo a seguir:
const bucket = new mongodb.GridFSBucket(db, { bucketName: 'myCustomBucket' });
Para obter mais informações, consulte a documentação da API do GridFSBucket.
Fazer upload de arquivos
Use o método openUploadStream() de GridFSBucket para criar um fluxo de upload para um determinado nome de arquivo. Você pode usar o método pipe() para conectar um fluxo de leitura do Node.js ao fluxo de upload. O método openUploadStream() permite que você especifique informações de configuração, como o tamanho da parte do arquivo e outros pares de campo/valor a serem armazenados como metadados.
O exemplo a seguir mostra como canalizar um fluxo de leitura em Node.js, representado pela variável fs, para o método openUploadStream() de uma instância GridFSBucket :
fs.createReadStream('./myFile'). pipe(bucket.openUploadStream('myFile', { chunkSizeBytes: 1048576, metadata: { field: 'myField', value: 'myValue' } }));
Consulte a documentação da API para openUploadStream() para obter mais informações.
Recuperar informações do arquivo
Nesta seção, você pode aprender como recuperar metadados de arquivo armazenados na coleção files do contêiner GridFS. Os metadados contêm informações sobre o arquivo a que se refere, incluindo:
O
_iddo arquivoO nome do arquivo
O tamanho/comprimento do arquivo
A data e a hora do carregamento
Um documento
metadatano qual você pode armazenar qualquer outra informação
Ligue para o método find() na instância do GridFSBucket para recuperar arquivos de um bucket GridFS. O método retorna uma instância do FindCursor da qual você pode acessar os resultados.
O exemplo de código a seguir mostra como recuperar e imprimir metadados de arquivos de todos os seus arquivos em um bucket do GridFS. Entre as diferentes maneiras de percorrer os resultados recuperados do iterável FindCursor, o exemplo a seguir usa a sintaxe for await...of para exibir os resultados:
const cursor = bucket.find({}); for await (const doc of cursor) { console.log(doc); }
O método find() aceita várias especificações de consulta e pode ser combinado com outros métodos como sort(), limit() e project().
Para obter mais informações sobre as classes e métodos mencionados nesta seção, consulte os seguintes recursos:
Baixar arquivos
Você pode baixar arquivos do seu banco de dados MongoDB utilizando o método openDownloadStreamByName() do GridFSBucket para criar um stream de download.
O exemplo a seguir mostra como fazer o download de um arquivo referenciado pelo nome do arquivo, armazenado no campo filename, para o seu diretório de trabalho:
bucket.openDownloadStreamByName('myFile'). pipe(fs.createWriteStream('./outputFile'));
Observação
Se houver vários documentos com o mesmo valor de filename, o GridFS transmitirá o arquivo mais recente com o nome fornecido (conforme determinado pelo campo uploadDate).
Alternativamente, você pode utilizar o método openDownloadStream(), que utiliza o campo _id de um arquivo como um parâmetro:
bucket.openDownloadStream(ObjectId("60edece5e06275bf0463aaf3")). pipe(fs.createWriteStream('./outputFile'));
Observação
A API de streaming do GridFS não pode carregar blocos parciais. Quando um fluxo de download precisa extrair um bloco do MongoDB, ele puxa todo o bloco para a memória. O tamanho padrão do bloco de 255 kilobytes geralmente é suficiente, mas você pode reduzir o tamanho do bloco para reduzir a sobrecarga de memória.
Para obter mais informações sobre o método openDownloadStreamByName(), consulte a documentação da API.
Renomear arquivos
Utilize o método rename() para atualizar o nome de um arquivo GridFS em seu bucket. Você deve especificar o arquivo para renomear pelo campo _id em vez do nome do arquivo.
Observação
O método rename() suporta somente a atualização do nome de um arquivo de cada vez. Para renomear vários arquivos, recupere uma lista de arquivos correspondentes ao nome do arquivo do contêiner, extraia o campo _id dos arquivos que você deseja renomear e passe cada valor em chamadas separadas para o método rename().
O exemplo a seguir mostra como atualizar o campo filename para "newFileName" fazendo referência ao campo _id de um documento:
bucket.rename(ObjectId("60edece5e06275bf0463aaf3"), "newFileName");
Para obter mais informações sobre este método, consulte a documentação da API renomear().
Excluir arquivos
Use o método delete() para remover um arquivo do seu bucket. Você deve especificar o arquivo pelo campo _id em vez do nome do arquivo.
Observação
O método delete() suporta apenas a exclusão de um arquivo por vez. Para excluir vários arquivos, recupere os arquivos do bucket, extraia o campo _id dos arquivos que deseja excluir e passe cada valor em chamadas separadas para o método delete().
O seguinte exemplo mostra como excluir um arquivo referenciando seu campo _id:
bucket.delete(ObjectId("60edece5e06275bf0463aaf3"));
Para obter mais informações sobre esse método, consulte a documentação da API para delete().
Excluir um bucket do GridFS
Utilize o método drop() para remover as coleções files e chunks de um bucket, que efetivamente exclui o bucket. O seguinte exemplo de código mostra como excluir um bucket GridFS:
bucket.drop();
Para obter mais informações sobre esse método, consulte a documentação da API para drop().