Visão geral
Neste guia, você aprenderá como armazenar e recuperar arquivos grandes no MongoDB usando o GridFS. O GridFS é uma especificação que descreve como fazer a divisão dos arquivos em parte durante o armazenamento e remontá-los durante a recuperação. A implementação do driver Rust do GridFS managed as operações e organização do armazenamento de arquivos.
Use o GridFS se o tamanho do arquivo exceder o limite de tamanho do documento BSON de 16 MB. O GridFS também ajuda a acessar arquivos sem carregar todo o arquivo na memória. Para obter informações mais detalhadas sobre se o GridFS é adequado para seu caso de uso, consulte a página GridFS no manual do servidor MongoDB.
Para saber mais sobre o GridFS, navegue até as seguintes seções deste guia:
Como funciona o GridFS
O GridFS organiza os arquivos em um bucket, que é um grupo de collection do MongoDB que contêm parte de arquivos e informações descritivas. Os buckets contêm as seguintes collection, nomeadas de acordo com a convenção definida na especificação GridFS:
chunks, que armazena as partes de arquivos bináriosfiles, que armazena os metadados do arquivo
Quando você cria um novo bucket GridFS, o driver Rust executa as seguintes ações:
Cria a collection
chunksefiles, prefixadas com o nome de bloco padrãofs, a menos que você especifique um nome diferenteCria um índice em cada collection para garantir a recuperação eficiente de arquivos e metadados relacionados
Você pode criar uma referência a um bucket GridFS seguindo as etapas na seção Referenciar um bucket GridFS desta página. No entanto, o driver não cria um novo bucket GridFS e seus índices até a primeira operação de gravação. Para obter mais informações sobre os índices do GridFS, consulte a página Índices do GridFS no manual do servidor MongoDB.
Ao armazenar um arquivo em um contêiner GridFS, o driver Rust cria os seguintes documentos:
Um documento na coleção
filesque armazena um ID de arquivo exclusivo, nome de arquivo e outros metadados de arquivoUm ou mais documento na collection
chunksque armazenam o conteúdo do arquivo, que o driver faz a divisão em partes menores
O diagrama a seguir descreve como o GridFS divide os arquivos ao fazer upload para um bucket:

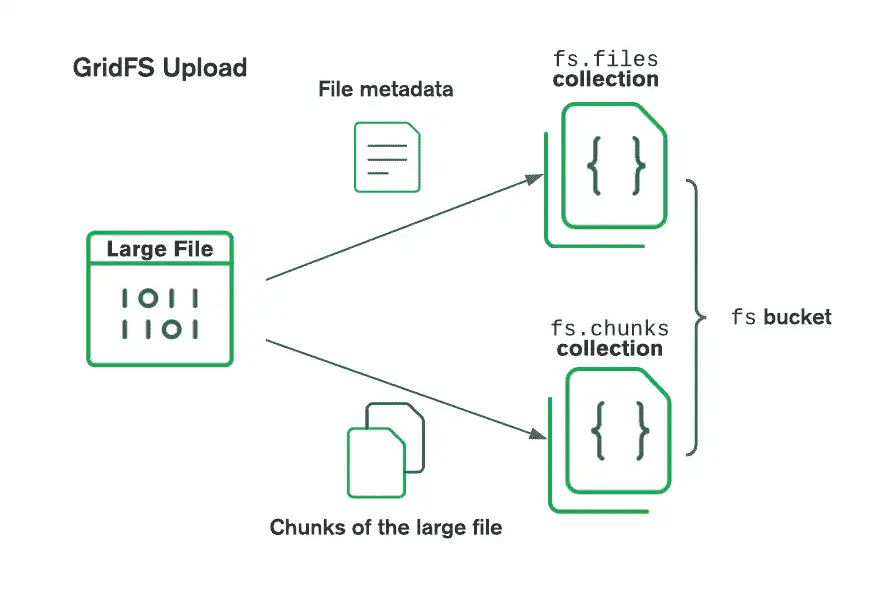
Ao recuperar arquivos, o GridFS obtém os metadados da coleção files no contêiner especificado e utiliza as informações para reconstruir o arquivo a partir de documentos na coleção chunks. Você pode ler o arquivo na memória ou enviá-lo para um fluxo.
Referenciar um bucket do GridFS
Antes de armazenar arquivos em um contêiner GridFS, crie uma referência de contêiner ou obtenha uma referência para um contêiner existente.
O exemplo a seguir chama o método gridfs_bucket() em um reconhecimento de data center, que cria uma referência a um GridFS novo ou existente:
let bucket = my_db.gridfs_bucket(None);
Você pode especificar um nome de bucket personalizado configurando o campo bucket_name da estrutura GridFsBucketOptions .
Observação
Instanciação de estruturas
O driver Rust implementa o padrão de design Builder para a criação de alguns tipos de estruturas, incluindo GridFsBucketOptions. Você pode usar o método builder() para construir uma instância de cada tipo encadeando métodos de construtor de opção.
A tabela seguinte descreve os métodos que você pode utilizar para configurar campos do GridFsBucketOptions :
Método | Valores possíveis | Descrição |
|---|---|---|
bucket_name() | Any String value | Specifies a bucket name, which is set to fs by default |
| Qualquer valor | Especifica o tamanho da parte usado para dividir o arquivo em partes, que é de 255 KB por padrão |
write_concern() | WriteConcern::w(),WriteConcern::w_timeout(),WriteConcern::journal(),WriteConcern::majority() | Specifies the bucket's write concern, which is set to the database's write concern by default |
|
| Especifica a referência de leitura do bucket, que é definida como a referência de leitura do reconhecimento de data center por padrão |
selection_criteria() | SelectionCriteria::ReadPreference,SelectionCriteria::Predicate | Specifies which servers are suitable for a bucket operation, which is set to the database's selection criteria by default |
O exemplo a seguir especifica opções em uma instância GridFsBucketOptions para configurar um nome de bucket personalizado e um limite de tempo de cinco segundos para operações de gravação:
let wc = WriteConcern::builder().w_timeout(Duration::new(5, 0)).build(); let opts = GridFsBucketOptions::builder() .bucket_name("my_bucket".to_string()) .write_concern(wc) .build(); let bucket_with_opts = my_db.gridfs_bucket(opts);
Fazer upload de arquivos
Você pode carregar um arquivo em um contêiner GridFS abrindo um fluxo de carregamento e gravando seu arquivo no fluxo. Chame o método open_upload_stream() na instância do bucket para abrir o stream. Este método retorna uma instância do GridFsUploadStream para a qual você pode escrever o conteúdo do arquivo. Para carregar o conteúdo do arquivo para GridFsUploadStream, chame o método write_all() e passe os bytes do arquivo como parâmetro.
Dica
Importar o módulo necessário
O struct GridFsUploadStream implementa a característica futures_io::AsyncWrite. Para usar os métodos de gravação AsyncWrite , como write_all(), importe o módulo AsyncWriteExt para o arquivo de aplicativo com a seguinte declaração de uso:
use futures_util::io::AsyncWriteExt;
O exemplo a seguir usa um fluxo de upload para carregar um arquivo chamado "example.txt" em um bucket GridFS:
let bucket = my_db.gridfs_bucket(None); let file_bytes = fs::read("example.txt").await?; let mut upload_stream = bucket.open_upload_stream("example").await?; upload_stream.write_all(&file_bytes[..]).await?; println!("Document uploaded with ID: {}", upload_stream.id()); upload_stream.close().await?;
Baixar arquivos
Você pode baixar um arquivo de um contêiner GridFS abrindo um fluxo de download e lendo o fluxo. Chame o método open_download_stream() na sua instância de bucket, especificando o valor _id do arquivo desejado como parâmetro. Este método retorna uma instância GridFsDownloadStream da qual você pode acessar o arquivo. Para ler o arquivo do GridFsDownloadStream, chame o método read_to_end() e passe um vetor como parâmetro.
Dica
Importar o módulo necessário
A estrutura GridFsDownloadStream implementa a funcionalidade futures_io::AsyncRead . Para usar os métodos de leitura AsyncRead , como read_to_end(), importe o módulo AsyncReadExt para o arquivo do aplicativo com a seguinte declaração de uso:
use futures_util::io::AsyncReadExt;
O exemplo a seguir usa um fluxo de downloads para baixar um arquivo com um valor _id de 3289 de um bucket GridFS:
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let mut buf = Vec::new(); let mut download_stream = bucket.open_download_stream(Bson::ObjectId(id)).await?; let result = download_stream.read_to_end(&mut buf).await?; println!("{:?}", result);
Observação
A API de streaming do GridFS não pode carregar partes parciais. Quando um fluxo de download precisa extrair uma parte do MongoDB, ele puxa toda a parte para a memória. O tamanho padrão da parte de 255 KB geralmente é suficiente, mas você pode reduzir o tamanho da parte para reduzir a sobrecarga de memória.
Recuperar informações do arquivo
Você pode recuperar informações sobre os arquivos armazenados na coleção files do bucket GridFS. Cada arquivo é armazenado como uma instância do tipo FilesCollectionDocument, contendo os seguintes campos que representam as informações do arquivo:
_id: o ID do arquivolength: o tamanho do arquivochunk_size_bytes: o tamanho das partes do arquivoupload_date: a data e hora de upload do arquivofilename: o nome do arquivometadata: um documento que armazena metadados especificados pelo usuário
Ligue para o método find() em uma instância de bucket GridFS para recuperar arquivos do bucket. O método retorna uma instância do cursor da qual você pode acessar os resultados.
O exemplo a seguir recupera e imprime o comprimento de cada arquivo em um contêiner GridFS:
let bucket = my_db.gridfs_bucket(None); let filter = doc! {}; let mut cursor = bucket.find(filter).await?; while let Some(result) = cursor.try_next().await? { println!("File length: {}\n", result.length); };
Dica
Para saber mais sobre o método find() , consulte o guia Recuperar dados . Para saber mais sobre como recuperar dados de um cursor, consulte o guia Acessar dados usando um cursor .
Renomear arquivos
Você pode atualizar o nome de um arquivo GridFS em seu bucket ligando para o método rename() em uma instância de bucket. Passe o valor _id do arquivo de destino e o novo nome do arquivo como parâmetros para o método rename() .
Observação
O método rename() suporta somente a atualização do nome de um arquivo de cada vez. Para renomear vários arquivos, recupere uma lista de arquivos correspondentes ao nome do arquivo do contêiner, extraia o campo _id dos arquivos que você deseja renomear e passe cada valor em chamadas separadas para o método rename().
O exemplo a seguir atualiza o campo filename do arquivo contendo um valor _id de 3289 para "new_file_name":
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let new_name = "new_file_name"; bucket.rename(Bson::ObjectId(id), new_name).await?;
Excluir arquivos
Você pode usar o método delete() para remover um arquivo do seu bucket. Para remover um arquivo, chame delete() na instância do bucket e passe o valor _id do arquivo como parâmetro.
Observação
O método delete() suporta apenas a exclusão de um arquivo por vez. Para excluir vários arquivos, recupere os arquivos do bucket, extraia o campo _id dos arquivos que deseja excluir e passe cada valor _id em chamadas separadas para o método delete() .
O exemplo a seguir exclui o arquivo no qual o valor do campo _id é 3289:
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); bucket.delete(Bson::ObjectId(id)).await?;
Excluir um bucket do GridFS
Você pode usar o método drop() para excluir um bucket, que remove a collection files e chunks de um bucket. Para excluir o bucket, ligue para drop() na sua instância do bucket.
O exemplo a seguir exclui um bucket GridFS:
let bucket = my_db.gridfs_bucket(None); bucket.drop().await?;
Informações adicionais
Documentação da API
Para saber mais sobre qualquer um dos métodos ou tipos mencionados neste guia, consulte a seguinte documentação da API: