Visão geral
Neste guia, você pode aprender as seguintes informações fundamentais sobre o Apache Kafka e o Kafka Connect:
O que são Apache Kafka e Kafka Connect
Quais problemas o Apache Kafka e Kafka Connect solucionam
A importância do Apache Kafka e Kafka Connect
Como os dados passam por uma pipeline do Apache Kafka e Kafka Connect
Apache Kafka
O Apache Kafka é um sistema de mensagens de publicação/inscrição open source. O Apache Kafka fornece um sistema flexível, tolerante a falhas e horizontalmente escalável para mover dados entre armazenamentos de dados e aplicativos. Um sistema é tolerante a falhas se o sistema puder continuar operando mesmo se determinados componentes do sistema pararem de funcionar. Um sistema é horizontalmente escalável se o sistema puder ser expandido para lidar com volumes de trabalho maiores adicionando mais máquinas em vez de melhorar o hardware de uma máquina.
Para obter mais informações sobre o Apache Kafka, veja os seguintes recursos:
Kafka Connect
O Kafka Connect é um componente do Apache Kafka que soluciona o problema de conectar o Apache Kafka a armazenamentos de dados como o MongoDB. O Kafka Connect soluciona esse problema fornecendo os seguintes recursos:
Um tempo de execução tolerante a falhas para transferir dados de e para armazenamentos de dados.
Um framework para a comunidade Apache Kafka compartilhar soluções para conectar o Apache Kafka a diferentes armazenamentos de dados.
O framework do Kafka Connect define uma API para os programadores escreverem conectores reutilizáveis. Os conectores permitem que as implantações do Kafka Connect interajam com um armazenamento de dados específico como fonte de dados ou coletor de dados. O conector Kafka MongoDB é um desses conectores.
Para obter mais informações sobre o Kafka Connect, consulte os seguintes recursos:
Como construir seu primeiro conector para o Kafka Connect a partir da Apache Software Foundation
Dica
Use o Kafka Connect em vez dos clientes de produtor/consumidor ao se conectar aos armazenamentos de dados
Embora você possa escrever seu próprio aplicativo para conectar o Apache Kafka a um armazenamento de dados específico usando clientes produtores e consumidores, recomendamos usar o Kafka Connect. Veja alguns motivos importantes para usar o Kafka Connect:
O Kafka Connect tem uma arquitetura distribuída tolerante a falhas que garante uma pipeline confiável.
Há um grande número de conectores mantidos pela comunidade para conectar o Apache Kafka a bancos de dados comuns, como MongoDB, PostgreSQL e MySQL usando a framework do Kafka Connect. Isso reduz a quantidade de código boilerplate que você deve escrever e manter para gerenciar conexões de banco de dados, o gerenciamento de erros, a integração de dead letter queue (DLQ) e outros problemas encontrados ao conectar o Apache Kafka a um armazenamento de dados.
Você tem a opção de usar um cluster gerenciado do Kafka Connect da Confluent.
Diagrama
O diagrama a seguir mostra como as informações fluem por um exemplo de pipeline de dados criado com Apache Kafka e Kafka Connect. O pipeline de exemplo usa um cluster MongoDB como fonte de dados e um cluster MongoDB como coletor de dados.

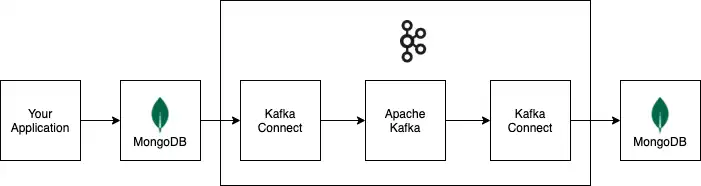
Todos os conectores e armazenamentos de dados na pipeline de exemplo são opcionais. Você pode substituí-los pelos conectores e armazenamentos de dados necessários para seu sistema.