Armazenar arquivos grandes
Nesta página
- Visão geral
- Como funciona o GridFS
- Crie um intervalo GridFS
- Personalizar o bucket
- Fazer upload de arquivos
- Escrever em um fluxo de upload
- Carregar um stream existente
- Recuperar informações do arquivo
- Exemplo
- Baixar arquivos
- Ler de um fluxo de download
- Baixar em um stream existente
- Excluir arquivos
- Documentação da API
Visão geral
Neste guia, você pode aprender como armazenar e recuperar arquivos grandes no MongoDB usando GridFS. O GridFS é uma especificação implementada pelo driver C++ que descreve como divisão os arquivos em blocos ao armazená-los e remontá-los ao recuperá-los. A implementação do driver do GridFS é uma abstração que gerencia as operações e a organização do armazenamento de arquivos.
Use o GridFS se o tamanho dos seus arquivos exceder o limite de tamanho de documento BSON de 16MB. Para obter informações mais detalhadas sobre se o GridFS é adequado para seu caso de uso, consulte GridFS no manual do MongoDB Server .
Como funciona o GridFS
O GridFS organiza os arquivos em um bucket, um grupo de coleções do MongoDB que contém os blocos de arquivos e as informações que os descrevem. O bloco contém as seguintes coleções, nomeadas usando a convenção definida na especificação do GridFS:
chunkscollection, que armazena os chunks de arquivos bináriosfilescoleção, que armazena os metadados do arquivo
O driver cria o bucket GridFS , se ele não existir, quando você grava dados pela primeira vez. O bucket contém as collections anteriores prefixadas com o nome de bucket padrão fs, a menos que você especifique um nome diferente. Para garantir a recuperação eficiente dos arquivos e de seus respectivos metadados, o driver cria um índice em cada collection. O driver garante que esses índices existam antes de realizar operações de leitura e gravação no bucket GridFS .
Para obter mais informações sobre os índices do GridFS , consulte Índices do GridFS no manual do MongoDB Server .
Ao usar o GridFS para armazenar arquivos, o driver divide os arquivos em partes menores, cada um representado por um documento separado na coleção chunks. Ele também cria um documento na coleção files que contém um ID de arquivo, nome de arquivo e outros metadados de arquivo. Você pode carregar o arquivo passando um fluxo para o driver C++ para consumir ou criando um novo fluxo e gravando diretamente nele.
O diagrama a seguir mostra como o GridFS divide os arquivos quando eles são carregados em um bucket:

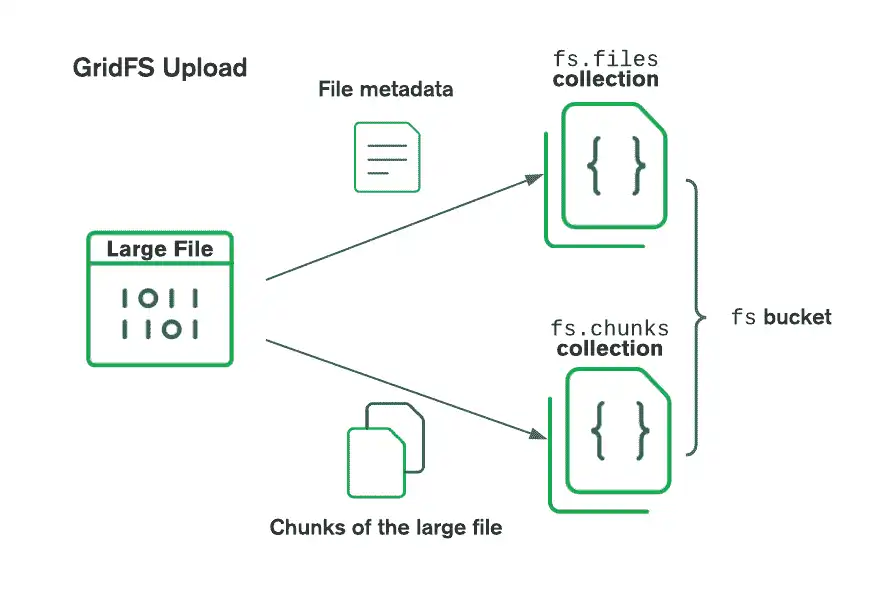
Ao recuperar arquivos, o GridFS obtém os metadados da coleção files no bloco especificado e utiliza as informações para reconstruir o arquivo a partir de documentos na coleção chunks. Você pode ler o arquivo gravando seu conteúdo em um fluxo existente ou criando um novo fluxo que aponte para o arquivo.
Crie um intervalo GridFS
Para começar a armazenar ou recuperar arquivos do GridFS, chame o método gridfs_bucket() no seu banco de dados de dados. Este método acessa um bucket existente ou cria um novo bucket se não existir.
O exemplo seguinte chama o método gridfs_bucket() no banco de dados de dados do db :
auto bucket = db.gridfs_bucket();
Personalizar o bucket
Você pode personalizar a configuração do bucket GridFS passando uma instância da classe mongocxx::options::gridfs::bucket como um argumento opcional para o método gridfs_bucket(). A tabela seguinte descreve os campos que você pode definir em uma instância do mongocxx::options::gridfs::bucket :
Campo | Descrição |
|---|---|
| Specifies the bucket name to use as a prefix for the files and chunks collections.
The default value is "fs".Type: std::string |
| Specifies the chunk size that GridFS splits files into. The default value is 261120.Type: std::int32_t |
| Specifies the read concern to use for bucket operations. The default value is the
database's read concern. Type: mongocxx::read_concern |
| Specifies the read preference to use for bucket operations. The default value is the
database's read preference. Type: mongocxx::read_preference |
| Specifies the write concern to use for bucket operations. The default value is the
database's write concern. Type: mongocxx::write_concern |
O exemplo seguinte cria um bucket denominado "myCustomBucket" configurando o campo bucket_name de uma instância mongocxx::options::gridfs::bucket:
mongocxx::options::gridfs::bucket opts; opts.bucket_name("myCustomBucket"); auto bucket = db.gridfs_bucket(opts);
Fazer upload de arquivos
Você pode fazer upload de arquivos para um bucket GridFS usando os seguintes métodos:
open_upload_stream(): abre um novo fluxo de upload para o qual você pode escrever conteúdo de arquivo
upload_from_stream(): Faz o upload do conteúdo de um fluxo existente para um arquivo GridFS
Escrever em um fluxo de upload
Utilize o método open_upload_stream() para criar um fluxo de upload para um determinado nome de arquivo. O método open_upload_stream() permite a você especificar informações de configuração em uma instância do options::gridfs::upload, que você pode passar como um parâmetro.
Este exemplo usa um fluxo de upload para executar as seguintes ações:
Define o campo
chunk_size_bytesde uma instância de opçõesAbre um fluxo gravável para um novo arquivo GridFS chamado
"my_file"e aplica a opçãochunk_size_bytesChama o método
write()para gravar dados emmy_file, para o qual o stream apontaChama o método
close()para fechar o fluxo apontando paramy_file
mongocxx::options::gridfs::upload opts; opts.chunk_size_bytes(1048576); auto uploader = bucket.open_upload_stream("my_file", opts); // ASCII for "HelloWorld" std::uint8_t bytes[10] = {72, 101, 108, 108, 111, 87, 111, 114, 108, 100}; for (auto i = 0; i < 5; ++i) { uploader.write(bytes, 10); } uploader.close();
Carregar um stream existente
Utilize o método upload_from_stream() para carregar o conteúdo de um stream para um novo arquivo GridFS . O método upload_from_stream() permite a você especificar informações de configuração em uma instância do options::gridfs::upload, que você pode passar como um parâmetro.
Este exemplo executa as seguintes ações:
Abre um arquivo localizado em
/path/to/input_filecomo um stream no modo de leitura bináriaChama o método
upload_from_stream()para carregar o conteúdo do stream para um arquivo GridFS chamado"new_file"
std::ifstream file("/path/to/input_file", std::ios::binary); bucket.upload_from_stream("new_file", &file);
Recuperar informações do arquivo
Nesta seção, você pode aprender como recuperar metadados de arquivo armazenados na coleção files do contêiner GridFS. Os metadados contêm informações sobre o arquivo a que se refere, incluindo:
O
_iddo arquivoO nome do arquivo
O tamanho/comprimento do arquivo
A data e a hora do carregamento
Um documento
metadatano qual você pode armazenar outras informações
Para recuperar arquivos de um GridFS , chame o método mongocxx::gridfs::bucket::find() no seu contêiner. O método retorna uma instância do mongocxx::cursor da qual você pode acessar os resultados. Para saber mais sobre cursores, consulte o guiaAcessar dados de um cursor.
Exemplo
O seguinte exemplo de código mostra como recuperar e imprimir metadados de arquivo de arquivos em um bucket GridFS . Ele usa um for loop para iterar pelo cursor retornado e exibir o conteúdo dos arquivos carregados nos exemplos de Arquivos de upload:
auto cursor = bucket.find({}); for (auto&& doc : cursor) { std::cout << bsoncxx::to_json(doc) << std::endl; }
{ "_id" : { "$oid" : "..." }, "length" : 13, "chunkSize" : 261120, "uploadDate" : { "$date" : ... }, "filename" : "new_file" } { "_id" : { "$oid" : "..." }, "length" : 50, "chunkSize" : 1048576, "uploadDate" : { "$date" : ... }, "filename" : "my_file" }
O método find() aceita várias especificações de query. Você pode usar seu parâmetro mongocxx::options::find para especificar a ordem de classificação, o número máximo de documentos a serem retornados e o número de documentos a serem ignorados antes de retornar. Para visualizar uma lista de opções disponíveis, consulte a documentação da API.
Baixar arquivos
Você pode baixar arquivos de um bucket GridFS usando os seguintes métodos:
open_download_stream(): Abre um novo fluxo de download do qual você pode ler o conteúdo do arquivo
download_to_stream(): Escreve o arquivo inteiro em um fluxo de download existente
Ler de um fluxo de download
Você pode baixar arquivos do seu banco de banco de dados MongoDB utilizando o método open_download_stream() para criar um stream de download.
Este exemplo usa um fluxo de download para executar as seguintes ações:
Recupera o valor
_iddo arquivo GridFS denominado"new_file"Passa o valor
_idpara o métodoopen_download_stream()para abrir o arquivo como um fluxo legívelCria um vetor
bufferpara armazenar o conteúdo do arquivoChama o método
read()para ler o conteúdo do arquivo do fluxodownloaderpara o vetor
auto doc = db["fs.files"].find_one(make_document(kvp("filename", "new_file"))); auto id = doc->view()["_id"].get_value(); auto downloader = bucket.open_download_stream(id); std::vector<uint8_t> buffer(downloader.file_length()); downloader.read(buffer.data(), buffer.size());
Baixar em um stream existente
Você pode baixar o conteúdo de um arquivo GridFS para um fluxo existente ligando para o método download_to_stream() em seu bloco.
Este exemplo executa as seguintes ações:
Abre um arquivo localizado em
/path/to/output_filecomo um stream no modo de escrita bináriaRecupera o valor
_iddo arquivo GridFS denominado"new_file"Passa o valor de
_idparadownload_to_stream()baixar o arquivo para o stream
std::ofstream output_file("/path/to/output_file", std::ios::binary); auto doc = db["fs.files"].find_one(make_document(kvp("filename", "new_file"))); auto id = doc->view()["_id"].get_value(); bucket.download_to_stream(id, &output_file);
Excluir arquivos
Use o método delete_file() para remover o documento de collection de um arquivo e os chunks associados do seu bucket. Isso exclui efetivamente o arquivo. Você deve especificar o arquivo pelo campo _id em vez do nome do arquivo.
O exemplo a seguir mostra como excluir um arquivo chamado "my_file" passando seu valor _id para delete_file():
auto doc = db["fs.files"].find_one(make_document(kvp("filename", "my_file"))); auto id = doc->view()["_id"].get_value(); bucket.delete_file(id);
Observação
Revisões de arquivos
O método delete_file() suporta a exclusão de somente um arquivo de cada vez. Se você quiser excluir cada revisão de arquivo ou arquivos com tempos de carregamento diferentes que compartilham o mesmo nome de arquivo, colete os valores _id de cada revisão. Em seguida, passe cada valor _id em chamadas separadas para o método delete_file().
Documentação da API
Para saber mais sobre como usar o driver C++ para armazenar e recuperar arquivos grandes, consulte a seguinte documentação da API: