The AI stack
The AI stack, as we define it in the world of generative AI applications, is still in its infancy, even at the time of writing in early 2024. This means that some parts of the stack have yet to consolidate into a selection of tools, libraries, and frameworks — opening doors for business and investment opportunities. At the same time, other components of the stack have developed to the point where there are industry best practices and leading tooling and cloud service providers.
Key components of the AI stack include:
- Programming language: The language used to develop the components of the stack, including integration code and source code of the AI application.
- Model provider: Organizations that provide access to foundation models via inference endpoints or other means. Embedding and foundation models are typical models used in generative AI applications.
- LLM orchestrator and framework: A library that abstracts the complexities of integrating components of modern AI applications by providing methods and integration packages. Operators within these components also provide tooling to create, modify, and manipulate prompts and condition LLMs for different purposes.
- Vector database: A data storage solution for vector embeddings. Operators within this component provide features that help manage, store, and efficiently search through vector embeddings.
- Operational database: A data storage solution for transactional and operational data.
- Monitoring and evaluation tool: Tools for tracking AI model performance and reliability, offering analytics and alerts to improve AI applications.
- Deployment solution: Services that enable easy AI model deployment, managing scaling and integration with existing infrastructure.
One aspect that may stand out is the emphasis on the model provider rather than the model within the stack. This distinction highlights that in the generative AI space, the reputation and reliability of the model provider often carry more weight than the specific models they release. Factors important to this stack component are the provider’s ability to update models, provide support, and engage the community. Switching between models from model providers when using an API inference endpoint is as simple as changing the model's name within your code.
Programming languages
Programming languages play a significant role in the AI stack, driving the selection of the other components and ultimately shaping the application developed. Programming language considerations are essential for modern AI applications, especially when security, latency, and maintainability are important.
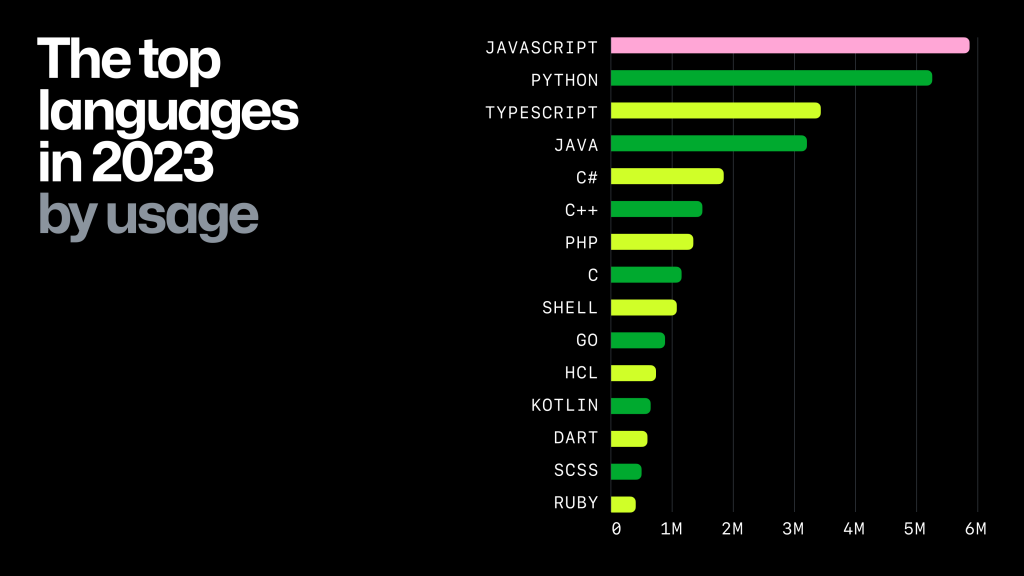
Selecting a programming language for AI applications is a process that involves a few options, the main choices being Python, JavaScript, and TypeScript (a subset of JavaScript). Undoubtedly, Python has a significant market share in language selection among data scientists and machine learning and AI engineers. This is primarily due to its extensive support for data science and AI libraries like TensorFlow, PyTorch, and Scikit-learn, not to mention the simplicity of the language. Python syntax is readable and offers flexibility in creating simple single-file scripts and full applications with an object-oriented programming (OOP) approach.
According to the February 2024 update on the PYPL (PopularitY of Programming Language) Index, Python leads the PYPL Index with a 28.11% share, reflecting a growth trend of +0.6% over the previous year. The PYPL index is a data-driven overview of which programming languages are gaining traction based on analysis of language tutorial searches on Google. The assumption is that the more a language tutorial is searched, the more popular the language is.
Within the PYPL Index, JavaScript holds the third position at 8.57%; its dominance in web application development has seamlessly transferred to the AI domain. This point is reinforced by the creation of libraries and frameworks that integrate AI functionalities into web environments. This development allows web developers to leverage AI infrastructure directly, eliminating the need to outsource development tasks or for companies to hire additional talent. LlamaIndex and LangChain, two widely utilized LLM/data frameworks for gen AI applications, have both Python and JavaScript/TypeScript implementations of their libraries.
According to GitHub’s 2023 state of open source and rise of AI, JavaScript is still the dominant programming language developers use, underscoring its wide adoption in web development, frameworks, and libraries. In the same report, the Python programming language observed a 22.5% year-over-year increase in usage on GitHub; again, this can be attributed to Python’s utilization in various appreciation, ranging from web applications to data-driven and machine learning systems.
The AI stack's programming language component has a more predictable future than the other components. Python and JavaScript (including TypeScript) have established their positions among software engineers, web developers, data scientists, machine learning and AI engineers.
Model providers
One API call away, and you have a powerful LLM with several billion parameters at your fingertips. This brings us to the AI stack's most crucial component, the model provider or model itself.
Model providers are organizations, small or large, that make readily available AI models, such as embedding models, fine-tuned models, and base foundation models for integration within generative AI applications.
The AI landscape today provides a vast selection of models that enable capabilities like predictive analytics, image generation, text completion, and more. The accessibility of models within the AI domain, including generative AI, is classified into closed- and open source models.
Closed-source models refer to models with internal configurations, architecture, and algorithms that are privatized and not shared with the model consumers. Instead, the creators or organizations responsible for the model hold key information regarding the model. Information about how the model was trained—and which data it was trained on—is also kept from the public and not made available for review, modification, or utilization. Closed source models are accessed via an API (application programming interface) endpoint or application interface.
The key aspect of closed-source models is that consumers of the models who are not creators are restricted from significantly altering the behavior of the model and can only alter parts of the model exposed by the creators via abstractions such as APIs. Common examples of closed-source models and their providers are:
- Claude, made available by Anthropic, is accessed via a web chat interface and API.
- OpenAI, which makes the LLMs GPT-3.5 and GPT-4, and embedding models like text-embedding-3-small, text-embedding-3-large, and text-embedding-ada-002 available via APIs and chat interfaces.
Open source model providers make elements liketheir internal architecture, network configuration, training data, weights, and parameters all publicly available. The open source community and its efforts foster collaboration and openness within the AI community.
Discussing the open source software framework in relation to AI models is convoluted because there are different versions of open source. Long story short, open source doesn’t necessarily mean entirely open. For simplicity, here are the common types of open source relevant to the AI stack.
- Open Source: All aspects of the model—such as weights, architecture configuration, training data, and training method—are made publicly available for use without any restrictions.
- Open Weight: Only the model weights and parameters are made publicly available for use.
- Open Model: Model weights and parameters are made available for use, but agreement to the creator’s terms of use is required.
The opportunity presented by open source models lies in the democratization of access to technology that was previously reserved for incumbents with enough resources to train and develop LLMs at scale. Open source LLMs reduce the entry barrier for developers to explore various use cases that are too niche for large companies to explore.
Examples of open LLMs include:
- LLaMA is a text generation model with variants and parameter counts in the of tens of billions. The LLaMA model family class has been created and released by Meta.
- Mixtral-8x7 by Mistral AI.
- BERT by Google.
- Grok by xAI.
AI engineers and machine learning practitioners often debate whether to incorporate open or closed-source large language models into their AI stacks. This choice is pivotal, as it shapes the development process, the project's scalability, ethical considerations, and the application's utility and commercial flexibility.
Below are typical considerations AI engineers have to make around LLMs and their providers’ selection.
Resource availability: The choice between selecting an open or closed-source model can often be quickly determined once the availability of compute resources and team expertise are examined. Closed-source model providers abstract the complexity of developing, training, and managing LLMs at the cost of either utilizing consumer data as training data or relinquishing control of private data access to third parties. Leveraging closed-source model providers within an AI stack can ensure more focus is placed on other components of the stack, like developing an intuitive user interface or ensuring strong data integrity and quality of proprietary data. Open source models provide a strong sense of control and privacy. Still, at the same time, careful consideration must be given to the resources required to fine-tune, maintain, and deploy open source models.
Project requirements: Understanding the technical requirements for any AI project is crucial in deciding whether to leverage open or closed-source LLMs. The project's scale is an ideal factor to consider. How many consumers or users does the deliverable in the AI project aim to serve? A large AI project that delivers value at scale will most likely benefit from the technical support and service guarantees that closed-source model providers offer. However, you are placing yourself at the mercy of the provider's API uptime and availability. Enterprise decision makers and practitioners building AI products and leveraging LLM capabilities via APIs should investigate the SLA(service level agreement) of the model provider.
In contrast, small-scale projects without strong uptime requirements or those which are still in the proof-of-concept phase could consider leveraging open source LLMs early on. Another advantage of open source models for both small and large scale project is that they can be fine-tuned for domain specific uses that do not require the generalizability of foundation models.
Privacy requirements: The topic of privacy in relation to generative AI is centered around sharing sensitive information and data with closed LLM providers such as OpenAI andAnthropic. In the age of generative AI, proprietary data is a valuable commodity, and areas of the internet where large corpuses of text, images, and video reside are making model providers agree to AI data licensing contracts. For AI practitioners, whether to utilize closed- or open source model providers lies in the delicate balance between accessing cutting-edge technologies and maintaining control over their data's privacy and security.
Other factors that AI engineers should consider when selecting the categories of their model are: ethical and transparency needs, prediction accuracy, maintenance cost, and overall infrastructure cost.
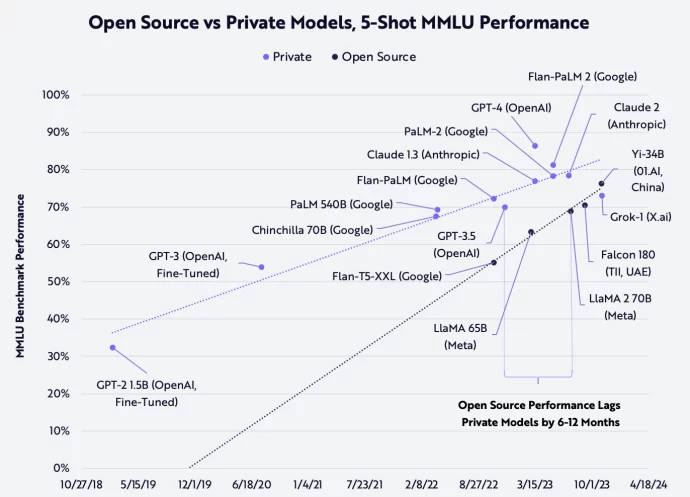
Another dimension of the conversation around open vs. closed-source models is the performance of the AI models on tasks. The MMLU (Massive Multitask Language Understanding) is a benchmark that evaluates foundation model performance on their intrinsic parametric knowledge by testing these models across 57 subjects, including philosophy, marketing, machine learning, astronomy, and more, at varying levels of complexity. The insight that can be extracted from observing the MMLU performance benchmark is that the efforts of the open source community in creating foundation models are very rapidly catching up to the efforts within closed/private model providers.
Of course, these can change at a whim as the activities within the providers of closed models aren’t released until a new model is announced, which can add a significant performance gap. But at the same time, it’s clear that in the near future, both closed and open AI models will have comparable performance, and the selection of open vs. closed-source models based on evaluative criteria will quickly become a secondary consideration. For context on the performance comparison between open-source models and private (closed) models, Ark Invest created a mapping of popular models and their performance on the MMLU evaluation criteria, shown below. At first glance, it does seem that the performance gap between open and private models is narrowing. However, the performance leaps of private models can be significant from one release to the next, and there are multiple dimensions to cognitive evaluations.
A big advantage for engineers leveraging closed/private models is that no significant engineering effort is put into deployment, as the functionality of closed models is behind APIs. Practitioners leveraging open source models also have to consider a deployment approach once downloaded, modified, or fine-tuned.
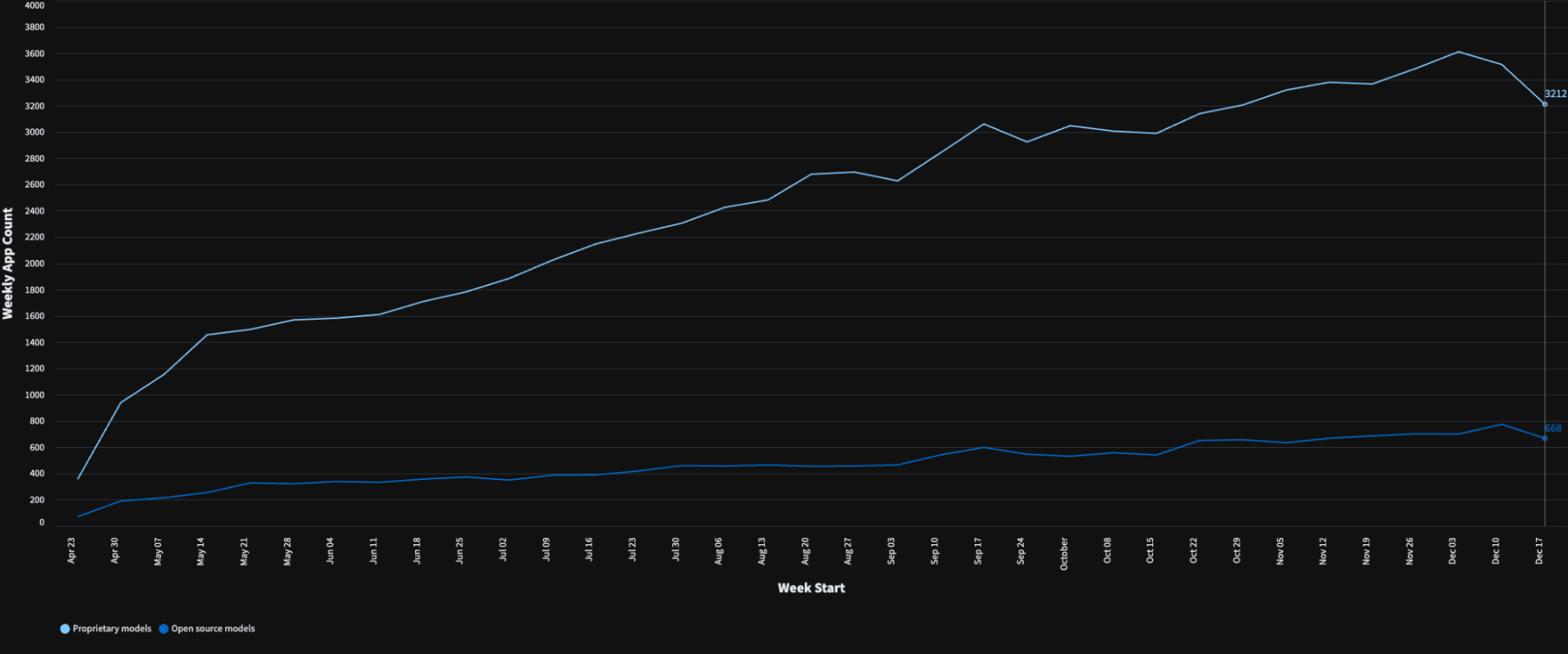
Notably, the ease of integration of closed models contributes to their adoption. The State Of LLM Apps report 2023 by Streamlit(image above) showed that 75% of apps built on Streamlit usually use a closed model. However, companies like Hugging Face and Ollama make running open source models locally or via hosted servers trivial; the Hugging Face inference endpoint solution closes any gap in deployment and compute availability for small- and medium-sized companies. Companies like Fireworks AI and TogetherAI make accessing open source models a simple API call away, a similar offering to closed-source providers. In 2024 and beyond, there could be a slight increase in the adoption of production apps that leverage open source models due to the accessibility and ease these companies provide, alongside a growing emphasis on transparency, proprietary data moat, and cost-effectiveness.
Incumbents also embrace the open source movement. Google, a massive player within the open source ecosystem, has defined a category of open source models, called “open models,” that refers to models with their weights and parameters publicly available, along with other model specifications. However, to utilize the models for research or commercial purposes, one must agree to the organization's terms of use.
LLM/AI frameworks and orchestrators
This component on the AI stack acts as a bridge between other components of the stack. LLM frameworks and libraries like LlamaIndex, LangChain, Haystack, and DSPy abstract the complexities involved in developing LLM-powered AI applications such as:
- Connecting vector databases with LLMs.
- Implementing prompt engineering techniques.
- Connecting multiple data sources with vector databases.
- Implementing data indexing, chunking, and ingestion processes.
Without LLM orchestrators and frameworks, AI applications will probably have more written code, which while not detrimental, does distract teams from key objectives, like implementing core unique features of products or hiring multiple developers to implement and maintain extensive code bases.
While acknowledging the potential of LLM orchestrators and frameworks, it's crucial to mention that these libraries are not silver bullets. Many of these tools have their respective language libraries, typically in Python and JavaScript (TypeScript) — read the programming languages section of this article to understand why — and these libraries could be said to still be in their infancy. This infancy presents its own set of challenges, particularly when it comes to upgrades and integration with existing systems. At the time of writing, the LangChain Python library is in version 0.1.9, and the LlamaIndex Python library is in version 0.10. These version numbers reflect a few things, notably stability and maturity. A library in version 1.0+ typically signifies a significant milestone in its development lifecycle. When it comes to selecting tooling for production-grade systems, engineers prioritize the stability and maturity of the library.
Another takeaway is that the rapid pace of development within the AI field means that new versions of these tools are released frequently. While innovation is certainly welcome, it can lead to compatibility issues with existing systems. AI teams and organizations might find themselves constantly needing to update their imported libraries and namespaces to stay compatible with the latest versions of these libraries, which can be both time-consuming and resource-intensive.
LLM frameworks have solidified their position within the AI/gen AI stack as a bridging tool that enables developers to integrate other parts of the AI stack component seamlessly. However, some engineers in the AI community have opinions about the strong presence of LLM frameworks. LLM frameworks are fundamentally abstraction layers that take away the implementation requirements to integrate with other tools; this is beneficial for teams that want to move to production quickly or iterate over several ideas relatively quickly without giving implementation details too much thought.
Nonetheless, it should also be acknowledged that due to the widespread adoption of such tools among AI developers and engineers, these middle-layer components influence the adoption of other components of the stack. However, this sentiment can change very quickly, especially when we explore the cannibalization of the current AI stack.
One aspect of the tech stack world is the divide that often occurs due to opinionated perspectives and philosophies in software engineering. Such a divide exists between Angular and React in web development and TensorFlow and PyTorch in machine learning. This pattern has not skipped the AI stack, as seen in the approaches and implementation of frameworks like DSPy and LangChain.
DSPy (Declarative Self-improving Language Programs, pythonically) is an opinionated LLM framework that approaches utilizing and tuning LLMs within AI applications as a programmatic and systematic process. Unlike traditional methods that rely on pipelines that are dependent specifically on prompt and prompting techniques, DSPy modularizes the entire pipeline and integrates the prompting, fine-tuning, and other weights of the pipeline into an optimizer that can be tuned and used as objective metrics to optimize the pipeline.
Below is a depiction of a RAG-modularized class using DSpy.
LangChain, one of the widely used LLM frameworks, has its expressive language, LCEL (LangChain Expressive Language), aimed at building production-ready, LLM-powered AI applications using a declarative implementation that embraces modularity and reusability. The general approach introduced by LCEL is chain composition, where the component or module of the pipeline can be configured in a manner that demonstrates a clear interface, enables parallelization, and allows for dynamic configuration.
Below is a code snippet of a RAG built using LangChain Expressive Language.
Vector and operational databases
Some modern AI applications need to include vector databases within their infrastructure and tech stack. This is due to the fact that the scope of tasks and their applicability to ML solutions is widening. AI applications involve more complex data types—like images, large text corpora, and audio, all of which all require efficient storage and retrieval. Complex data types can be stored as vector embeddings once an embedding model has processed the raw data. Vector embeddings are a high-dimensional numerical representation of data that captures the context and semantics of raw data.
Mapping a vast number of vector embeddings within a high-dimensional space and comparing their distances enables similarity searches based on semantics and context. This capability facilitates the development of recommendation systems, efficient chatbots, Retrieve-And-Generate (RAG) applications, and personalized services within AI applications. Notably, by representing unstructured data through vector embeddings, data can be searched and retrieved based on similarity metrics computed from semantics rather than lexical or exact content matches. This introduces another dimension of context-based search into modern AI applications.
Vector databases are specialized storage solutions for efficiently storing, indexing, managing, and retrieving vector embeddings. These specialized databases are optimized to perform operations on high-dimensional vectors by leveraging efficient indexing algorithms like HNSW (Hierarchical Navigable Small World) and computing the distance similarity between two or more vectors. The capabilities of vector database systems to quickly conduct vector similarity searches from a vector space of thousands or millions of vector embeddings improve the experience of an AI application user in terms of functionality capabilities, as well as LLMs’ response accuracy and relevance.
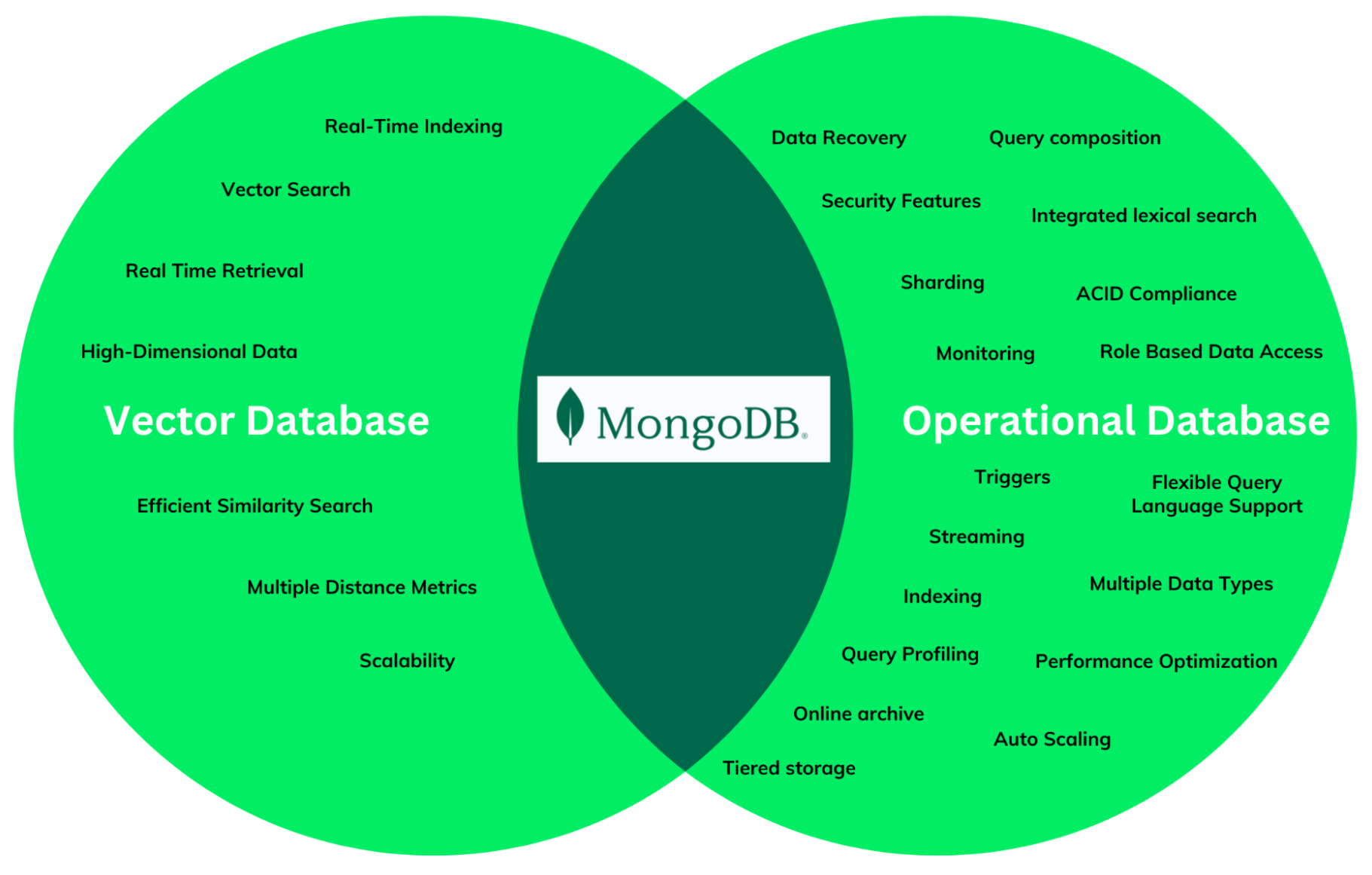
Other components of the AI stack have to interact seamlessly with the vector database; this particular consideration affects the choice of tools, libraries, and frameworks for the stack's components. In particular, the LLM orchestrator and framework selection could be shaped by the selection of the vector database or vice versa. LLM orchestrators and frameworks provide a range of integrations with popular vector database solutions. Still, their coverage needs to be more extensive for AI engineers and developers to disregard conducting a confirmation that the LLM orchestrator of choice integrates and supports the selected vector database solution. MongoDB is a popular choice as a vector database and has integration and consistent support from LLM orchestrators and frameworks such as LlamaIndex and LangChain.
Integrating your vector database seamlessly with the operational database is a crucial component of the AI stack. Although some providers offer solutions exclusively as vector databases, the complex data storage needs of modern AI applications make it essential to incorporate an operational database into your AI stack and infrastructure. This necessity arises from the requirement to manage transactional data interactions, ensure efficient data management, and meet real-time data requirements, among others.
An operational database within the AI technology stack serves as the storage system for securely storing, efficiently managing, and swiftly retrieving all data types; this includes metadata, transactional data, and operational and user-specific data. An operational database in the AI stack should be optimized for speed and low-latency transmission of data between the database server and client; typical considerations of operational databases are:
- High throughput
- Efficient transactional data operations
- Scalability (both horizontal and vertical)
- Data streaming capabilities
- Data workflow management capabilities
AI stacks require the consideration of an operational database, and when the AI application or team matures, the conversation of modern databases begins. Operational databases in AI applications are crucial for the following reasons:
- Real-time data processing
- User and session data management
- Complex data management
- Role-based access control and management
MongoDB's position within the AI stack acts as both the vector and operational database solution for modern applications, facilitating use cases like real-time data processing, data streaming, role-based access control, data workflow management, and, of course, vector search.
The composition of an AI stack should be based on simplicity, efficiency, and longevity. Having two storage solutions—one to handle vector embeddings and another for other data types—can create data silos, leading to complexities in data management and integration, potentially hindering the seamless flow of data across the stack and reducing overall system efficiency. MongoDB solves these problems by providing a modern database that handles both lexical and vector searches and operational and vector data. MongoDB has dedicated infrastructure for Atlas Search and Vector Search workloads. Find out more about this unique database infrastructure setup.
Monitoring, evaluation, and observability
Note: There is a nuanced difference between LLM evaluation and LLM system evaluation. LLM evaluation is the process of assessing the performance of an LLM based on factors like accuracy, comprehension, perplexity, bias, and hallucination rate. LLM system evaluation determines a system's overall performance and effectiveness with an integrated LLM to enable its capabilities. In this evaluation scenario, the factors considered are operational performance, system latency, and integration.
The topic of monitoring and observability signifies the considerations that come with a mature AI application transitioning from the proof-of-concept (POC) and demo phase to the minimal viable product (MVP) and production territory. Utilizing closed-source LLM providers requires attention and effort to monitor inference costs, particularly for applications expected to serve thousands of customers and process several million input tokens daily.
Even more so, the question of which combination of prompt engineering techniques yields quality responses from the LLMs becomes paramount to determining the value created for your application user. The evolution from POC to production application involves performing a balancing act between token reduction and LLM output quality maintenance for production AI applications.
Tools such as PromptLayer, Galileo, Arize, and Weight & Biases are tackling the problem of LLM observability, evaluation, and monitoring. Before diving into the reasons why AI practitioners should even consider such tools, let’s cover key terms you should be aware of when exploring this component of the AI stack.
What is LLM system observability and monitoring?
What a world it would be if we developed, trained, and deployed LLMs or other AI models into production and did not have to monitor their performance or output because they behaved predictably. But the reality is that for any software application deployed to production, even a simple calculator application, you need some form of monitoring of application performance and user interaction.
LLM system observability and monitoring refer to the efforts encapsulated in methodologies, practices, and tools to capture and track insights into the operational performance of LLMs in terms of their outputs, latency, inputs, prediction processes, and overall behavior within an AI application. You don’t need to look far to notice that there have been what can be described as “uncontrollable” outputs from application-embedded LLMs in the wild. Perhaps the uptick in the amount of generative AI spewing out unintended or unintelligible outputs reflects the pressure on incumbents to innovate and out-compete. This certainly will improve as the generative AI domain exits the infancy stage.
In the meantime…we should all probably buckle up.
What is LLM evaluation?
Evaluation is the next best thing to solving for unpredictable behaviors from LLMs.
LLM evaluation is the process of systematically and rigorously testing the performance and reliability of LLMs. This systematic process involves a series of tests that includes, but is not limited to:
- Benchmarking performance against datasets to ensure the model’s output quality.
- Passing model output to humans for feedback on output relevance and coherence.
- Adversarial testing to identify vulnerabilities in models or guardrails.
Hallucinations in LLMs can be considered both a feature and a bug. The capability that renders LLMs valuable to users — generating novel and contextually relevant content — can also be their downfall by producing incorrect or misleading information, highlighting flaws in their design. Reducing hallucinations in LLMs is an active area of research. However, there are efforts to mitigate or, at the very least, detect early hallucinations in systems before they are deployed to production.
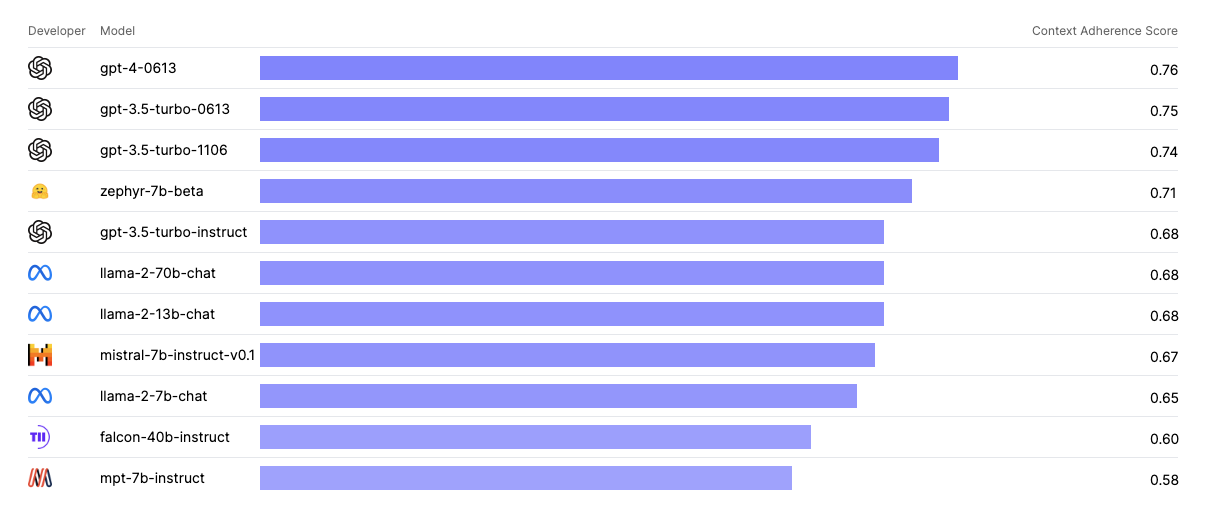
An interesting LLM benchmark I found while researching is the LLM Hallucination Index. The LLM Hallucination Index — created by the team at Galileo, a generative AI application evaluation company — tackles the challenge of hallucinations by evaluating LLMs' responses across three common task types:
- Question and answer
- Question and answer with RAG
- Long-form text generation
The Hallucination Index positions itself as a framework for ranking and evaluating LLM hallucinations by using two key metrics: Correctness and Context Adhesion.
Have you noticed the carnivorous nature of the current state of the modern AI stack? If you haven’t, you are about to see it in action.
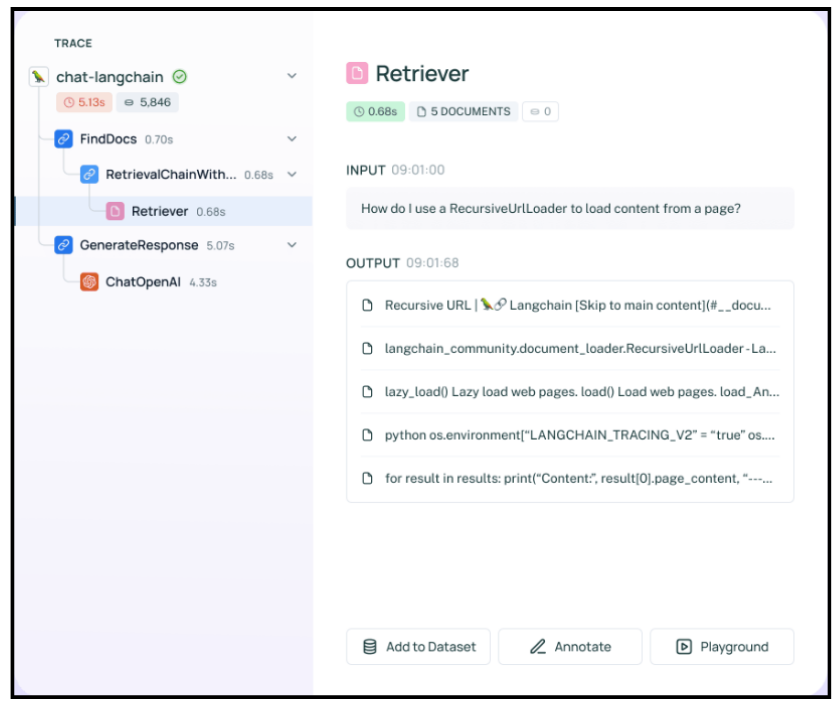
LLM orchestrators and data frameworks are taking a bite out of the LLM monitoring and evaluation pie. LangSmith is a platform solution created by LangChain that covers the breadth of the AI application lifecycle, from development to deployment and monitoring. The high-level objective of LangSmith is to provide developers with a controllable, easy-to-use, and understandable interface to monitor and evaluate the outputs of LLM-based systems, including metrics like response latency, the number of source documents utilized in RAG, process flow to response outcome, and more.