Table of contents
- Large language models lead the way
- Understanding foundation models
- What are the different types of foundation models?
- Foundation models: from data collection to end user
- The input and output of a foundation model application
- Foundation models in real life applications
- Challenges and limitations of foundation models
- Conclusion
- Learn more about MongoDB Atlas
Foundation models are a class of advanced artificial intelligence (AI) models characterized by their deep neural network architectures. They are generative AI models that train on massive, diverse datasets, which lets them perform a wide array of tasks far beyond the capabilities of traditional, single-purpose models, such as email spam filters.
Foundation models can learn and adapt for use in a broad range of applications instead of just one task. Their capabilities as an artificial intelligence model include but are not limited to language understanding, image generation, and audio processing, and they’re continually improving as they learn from new data and use cases. They are reshaping our interactions with technology and stand at the forefront of AI technology and large language models.
Large language models lead the way
Foundation models come in several forms, each with unique capabilities. As we progress through this article, we’ll discuss each one in more detail. For now, we’ll focus on the large language model (LLM). LLMs have gained the most traction of all foundation model types, standing out for their advanced abilities in handling and generating text. They’re adept not just in linguistic tasks but also in areas requiring creativity and complex problem-solving.
Another key strength of LLMs and, therefore, foundation models is that they are highly adaptable, which means they are used in a wide range of applications. Their impact spans multiple industries, from technology and healthcare to education, making them more than just an enhancement of existing artificial intelligence capabilities.
One of the most well-known LLMs is GPT-4, which has become synonymous with high-quality text generation because of its versatility and effectiveness in processing and generating human language across various applications. Alongside GPT-4 are OpenAI’s DALL-E, leading the way in image generation, and WaveNet, which sets the standard in generating lifelike audio.
Understanding foundation models
Introduced by the Stanford Institute for Human-Centered AI, foundation models are defined as models trained on a broad array of data, typically through self-supervision at scale, enabling adaptation to a wide range of tasks.1 This broad array of data includes labeled and unlabeled data. However, foundation models are often primarily fed with unlabelled data, which allows them to sift through and learn from vast quantities of information without reliance on predefined tags or categories. Let’s take a closer look.
1 Stanford Institute for Human-Centered Artificial Intelligence; “Reflections on Foundation Models”
Foundation models effortlessly tackle unlabeled data
Imagine teaching a computer to cook a variety of dishes, but instead of giving it recipes (which are like labeled data), you let it watch thousands of unlabelled cooking videos. These videos show a wide array of dishes being prepared, from pasta and sushi to cakes and salads, but no descriptions, ingredient lists, or instructions are provided.
As the computer watches these videos, it begins to notice patterns and common steps in cooking: how vegetables are chopped, what it looks like to sauté onions, or how the dough is kneaded. Over time, the computer starts to understand the process of cooking various dishes, recognizing techniques and ingredients, even though it was never directly taught what each thing is. It learns to identify and predict cooking processes, much like a chef who has observed and absorbed various cooking styles.
Foundation models can mimic the ability to reason based on training data
A key feature in many foundation models is their reliance on deep learning techniques, including the attention mechanism found in transformers. Transformers, a type of neural network architecture integral to numerous foundation models, are specifically designed to process sequential data, such as language, more efficiently than earlier machine learning models.
Within transformers, the attention mechanism is crucial. It enables the model to identify and give more weight to relevant or nuanced elements within the data, like specific words in a sentence, while reducing emphasis on less pertinent details.
For instance, when processing a sentence, the model focuses on specific words or phrases it recognizes from previous training, understanding their significance in the current context. While this approach doesn't fully replicate human-like learning, it significantly narrows the gap by offering a more nuanced and context-aware interpretation of data.
What are the different types of foundation models?
While large language models like GPT-4 and Llama by Meta are the most popular foundation models, other types of foundation models are available. Let's take a look at other foundation models.
Image and vision models: Image and vision foundation models, such as Vision Transformers (ViT), are trained on extensive image datasets. They are used in image recognition, object detection, and even complex image generation. These can be used for various business-critical applications, such as real-time inventory tracking.
Multimodal models: Foundation models like CLIP (from OpenAI) and Google's Multimodal Transformer are trained on datasets containing text and images. They are distinct from LLMs because they understand and generate content that combines visual and textual elements, whereas LLMs primarily focus on text. They are adept image captioning and cross-modal searches.
- Cross-modal searches are when an AI foundation model receives a text prompt and searches across different data types to produce a result. For example, if you type in “pictures of a red car” as a search, the AI can show you pictures of red cars, even though you used text to search.
Audio processing models: Foundation models in the audio domain, such as WaveNet, are focused on processing and generating audio. They differ from LLMs because they are used for realistic speech synthesis, music generation, and sound effect creation. For example, one of MongoDB’s customers, Potion, uses audio models to personalize sales videos to make them more effective, saving teams a significant amount of time.
Reinforcement learning models: Designed to learn strategies and decision-making through trial and error in simulated environments, these models are used in game playing, robotics, and simulations, where the model makes decisions.
Generative models for art and design: Models like DALL-E and StyleGAN train to generate artistic and design content. Their ability to create new images, artworks, and designs based on input parameters or styles separates them from the text-based capabilities of LLMs.
Robotics and control models: These models are trained in simulated environments and are capable of learning complex physical tasks like object manipulation and autonomous movement. This is an entirely different domain compared to the language procession of LLMs.
Foundation models: from data collection to end user
Up to this point, we’ve discussed foundation models and how different types perform diverse tasks. But now it’s time to closely examine how they are built. Every step, from acquiring the data, to training the model, to producing a good result for the end user, is an important one.
Data collection and preprocessing: The foundation model journey begins with the extensive collection of varied data types, including text, images, structured data, and speech inputs, which are sourced from books, websites, articles, and more. Once the data is collected, it is cleaned and occasionally annotated to set it up for effective learning.
Compute power: Next up is procuring the substantial computing resources required for processing the large datasets used in foundation models. The sheer volume of data necessitates powerful tools like graphical processing units (GPUs), and sometimes tensor processing units (TPUs), an AI accelerator application-specific integrated circuit (ASIC) created by Google for neural network learning. This stage in creating foundation models is a testament to the technological prowess required to train them.
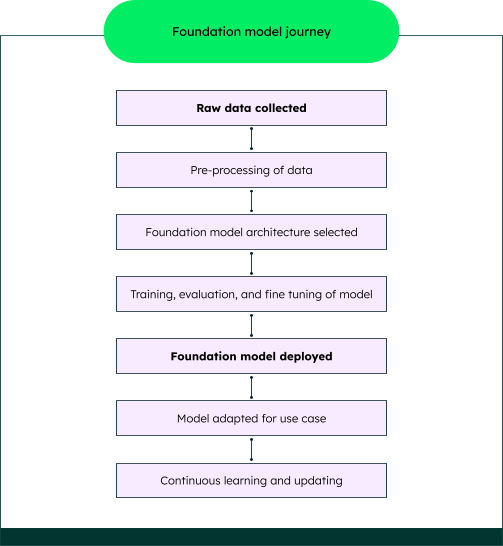
Training process: During this stage in foundation model development, AI researchers and engineers begin the process of training data. This involves a meticulous process where the model is exposed to data for learning and prediction, a complex task managed by using advanced algorithms such as transformers, generative adversarial networks (GANs), and variational autoencoders (VAEs).
These technologies are instrumental in refining the model’s capabilities, enabling it to understand and generate text (transformers), generate realistic images (GANs), and handle complex data distributions (VAEs). The training involves a delicate dance of adjusting parameters and reassessing connections to align predictions with reality. After extensive evaluation and fine-tuning, which enhances accuracy and reduces biases, the model becomes more attuned to domain-specific tasks.
Model completion: The foundation model is ready for release once it hits its performance benchmarks. This marks its transition to a deployable state, poised for integration across various platforms.
Hosting: Enter the hosting stage, where the model becomes accessible. Hosted either through an API or a direct download, the foundation model is made available by cloud services or specialized in-house divisions, bridging the gap between creation and real-time use.
Adaptation and application: The foundation model now enters the world of practical application, which can be tailored to fit into specific use cases like chatbots, translation services, and content generation tools. This stage, known as fine-tuning, highlights the model's flexibility and capability to meet unique application requirements.
End-user engagement: Finally, the model reaches its end-users. Companies, organizations, and individuals can now leverage the power of generative AI in their respective domains.
The input and output of a foundation model application
Now that we’ve covered how the foundation model is created, let’s examine what happens when a user inputs data into a foundation model application.
Input processing
When a user provides input, such as a question or a prompt, the foundation model converts the input into a format that can be understood by the model. Behind the scenes, the model uses its trained parameters to understand the context of the input, which involves using layers of neural networks to analyze the patterns, relationships, and nuances in the input data.
Based on understanding the context, the model makes some predictions that align with the inputs. The response is then refined for coherence, relevance, and fluency, which may involve additional processing steps like checking for grammatical correctness or adjusting the tone to match the input.
Output delivery
Finally, the generated response is delivered to the user. This response should ideally address the user's input accurately and informatively in the form of human- language instructions.
Foundation models in real life applications
Foundation models are making a significant impact in real-life applications, primarily through their capabilities in natural language processing (NLP) and computer vision, but more task-specific applications are widely used, as well.
Natural language processing applications
Foundation models are revolutionizing NLP and often use LLMs to perform various language-related tasks. LLMs are potent tools in NLP because they have been trained on vast amounts of text data, enabling them to understand, interpret, and generate human language with high sophistication. However, it's important to note that NLP encompasses a wider range of techniques and models beyond just LLMs, and LLMs are one of the many approaches used in the field of NLP.
Computer vision applications
Foundation models are making strides in computer vision by improving object and image recognition accuracy, with notable applications within the security and retail sectors. In robotics and autonomous driving, they are indispensable for visual processing, guiding navigation and operations. Beyond simple recognition, they generate images from textual descriptions and enhance photo and video content, marking a significant leap in image-related applications.
Task-specific applications
Predictive analytics uses vast amounts of data to predict trends and outcomes, which is useful in finance, healthcare, and marketing. Sentiment analysis analyzes text data to understand opinions, emotions, and attitudes, commonly used in customer service and social media monitoring.
Other task-specific applications include:
- Customized recommendations, used in engines for personalized content and product suggestions in e-commerce and streaming services.
- Audio and speech processing, to understand spoken language, aiding voice-controlled applications and audio analysis.
- Automated code generation, to assist in software development by generating code snippets, debugging, and creating simple programs based on requirements.
- Real-time decision-making, to support systems in making autonomous decisions, such as in IoT devices, smart homes, and advanced manufacturing processes.
Challenges and limitations of foundation models
Foundation models, known for their advanced capabilities and versatility, have significantly reshaped the landscape of AI. However, like any innovative technology, they come with their own challenges and limitations.
One major challenge is the substantial infrastructure demands these models require. In terms of both time and financial resources, the development of foundation models is a hefty investment. Additionally, the operational aspect of foundation models is highly resource-intensive. They require considerable computational power and energy, which can be a limiting factor, especially regarding scalability and environmental impact.
Another notable concern is the potential for misuse. As AI systems become more advanced and integrated into various aspects of society, ensuring their safe and responsible use is paramount. This is the goal of AI safety, a critical field that addresses the potential risks and ethical considerations associated with artificial intelligence.
AI safety tackles the challenge of aligning AI systems with human values and ensuring that they behave as intended in complex real-world scenarios. Moreover, it includes the development of robust systems that can withstand adversarial attacks and prevent unintended consequences. Researchers in AI safety strive to anticipate and mitigate risks, ensuring that AI advancements contribute positively to society and do not inadvertently cause harm or ethical dilemmas.
Other challenges and limitations include:
Contextual comprehension: Understanding context of prompts can be challenging for foundation models, which affects the relevance and appropriateness of their responses.
Reliability: Answers generated by foundation models can sometimes be unreliable or inappropriate. Since they are often trained on data from the internet, which isn’t always vetted, the quality and accuracy of responses can vary.
Opaque training data: For many open-source foundation models, the specific datasets used for training are not always disclosed, raising questions about the integrity and origins of the data.
Bias: The large datasets used for training these models can contain biases, including hate speech and biased tones, which the models may inadvertently learn and replicate.
Legal: Many foundation models are trained on a large corpus of data from the Internet or proprietary or sensitive business data, which may raise legal questions.
These challenges underscore the need for careful consideration developing and deploying foundation models, balancing their remarkable capabilities with the responsibility to address and mitigate these limitations.
Conclusion
Emerging at the forefront of AI innovation, language models like GPT-4 and image models like DALL-E are redefining the AI landscape with their advanced, versatile capabilities. Their impact extends across multiple sectors, signaling a significant shift in how AI integrates into daily life.
While marveling at their groundbreaking qualities, it’s important to remember that foundation models have a critical limitation: they lack access to real-time, private and domain-specific data. Indeed, foundation models, such as large language models, are trained on vast amounts of data and generalize well to most tasks, but rely solely on their inherent parametric knowledge. This limitation becomes particularly evident in scenarios demanding timely and up-to-date information.
As we embrace this new era, balancing the excitement with a mindful approach to the inherent challenges, such as legal and ethical considerations, potential for misuse, and responsible development, is essential.
Learn more about MongoDB Atlas
MongoDB Atlas provides AI engineers and builders with the necessary platform and tools to build generative AI applications that leverage the RAG architecture.
MongoDB Atlas Vector Search enables the development of intelligent applications that can process unstructured data and perform semantic searches using embeddings created by foundation models and LLMs.