Vector embeddings are numerical representations of the data, created by translating words, sentences, or other media into multidimensional arrays of floating point numbers (numerical representation) that computers can understand. They’re created so machine learning models can process and analyze incoming data. Correct embeddings are crucial to understanding semantic relationships between data points and capture important features and analyze complex relationships in the data.
In this article, we will dive into vectors, their embeddings, why we need these embeddings, and how MongoDB Atlas and VoyageAI provide a unified platform to create, store, and query vector embeddings.
Key takeaways
- Vector embeddings are numerical representations of data in a high-dimensional space.
- By representing data (text, image, video, audio and so on) as embeddings, we can capture their features and relationships, and analyze data more efficiently using machine learning models.
- Vector embeddings are used in many machine learning and LLM-based applications for natural language processing, search and recognition tasks, and context based-information retrieval.
- VoyageAI is a state-of-the-art tool to create embeddings—and it provides a reranking model to get more relevant search results.
- MongoDB Atlas provides vector search capabilities and allows vector embeddings to be stored alongside application data, enabling semantic search and retrieval within a unified data platform.
Table of contents
- What is a vector?
- What are vector embeddings?
- How vector embeddings work
- Creating vector embeddings
- Advantages of vector embeddings
- Challenges and limitations
- Use cases of vector embeddings
- Using VoyageAI and MongoDB Atlas for vector embeddings and vector search
- Conclusion
- FAQs
- Related content
What is a vector?
In machine learning, a vector is an ordered list of numbers. When we convert incoming data—text, images, audio, video, and unstructured data—into vectors, each piece of text plots as a point in a vast, multidimensional space, typically more than three dimensions, each representing a different feature of the data.
For example, an image consisting of multiple pixels can be represented as a set of vectors. Each pixel consists of red, green and blue (RGB) subpixels and a color is represented as the combination of the three. For simplicity, consider a three-dimensional vector space, where the color “plum” can be represented as the vector:

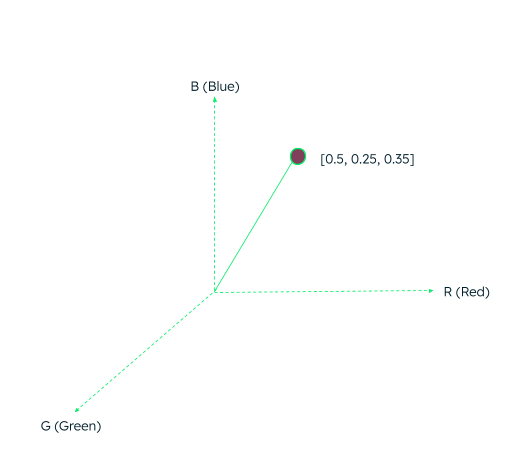
What are vector embeddings?
Embeddings give meaning to the vector representations. Each vector embedding represents non-zero data points corresponding to different characteristics or features of the data. The numbers point to a word’s contextual meaning and its similarity to other words in the same shared space.
The unstructured data received from various sources is huge and has many dimensions when represented as a vector. Embeddings help in dimensionality reduction, determining semantic relationships between data, and reduce the overall computational complexity, thus enabling faster processing.
Continuing our earlier example of colors in a three-dimensional vector space, let’s see what other colors are matching or close or similar to the plum color from the below image, and which colors are not. Let's consider a few colors: spring green, evergreen, sky and lime, present in the reference image.
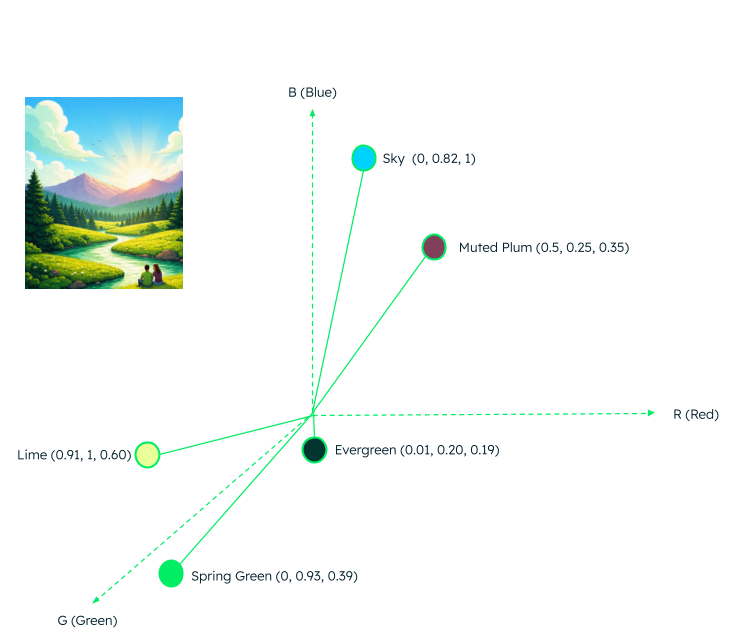
Notice that each of these colors in the three-dimensional plane depict their points and the distance to other colors based on how close they are to the base (primary colors)—red, green, and blue.
We can use the same approach for words, sentences, images, videos, and other unstructured data. All these vectors are represented in a multi-dimensional space depicting multiple features—three dimensions is the simplest example we can use.
Consider the word “voyage.”
The exact vector embedding value of this word depends on the context of the word, the model used for creating the embeddings, and the semantic space. For example, the word voyage is similar to journey, trip, cruise, or travel in meaning. However, in different contexts, it doesn’t necessarily mean travel or a trip.
“The company began its voyage into global markets very recently”,
or
“Let’s take a spiritual voyage every Sunday through meditation”.
In the above sentences, the word voyage has been used figuratively and a vector value will be assigned by the model based on the context and semantics (words like “markets” and “spiritual”).
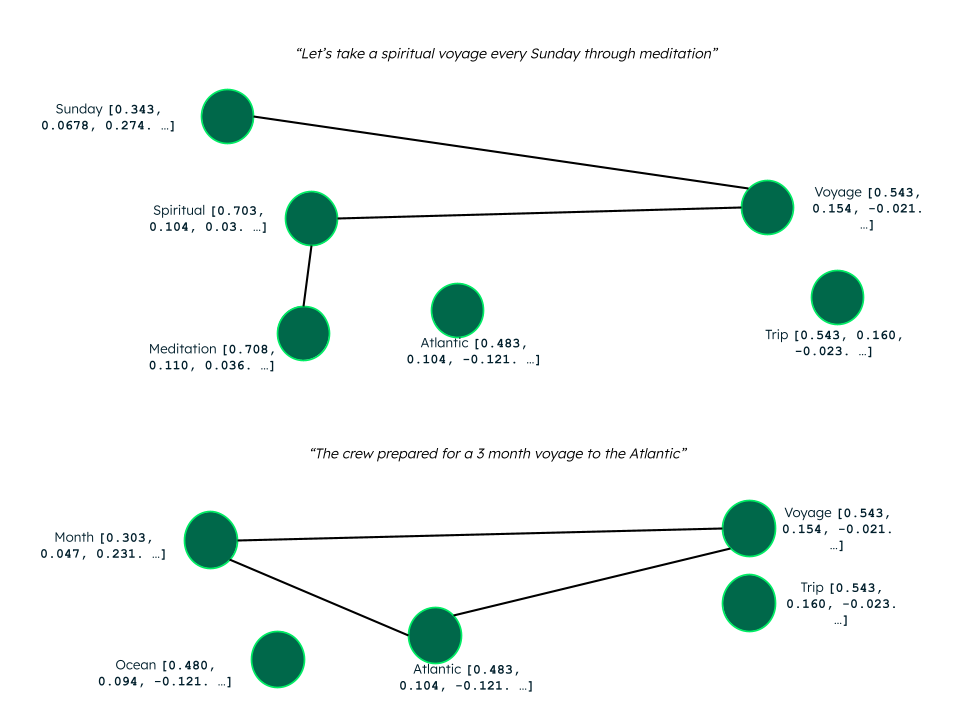
The above drawings represent the vector embeddings in a multidimensional space and the lines depict the distance between each word, indicating the closeness in meaning/context from the word. As we see, the words voyage and Sunday or month are farthest, while voyage and trip are close. Generally, when we talk about a voyage, the mind thinks of a sea journey and hence the next closest word is Atlantic. Atlantic and ocean—and spiritual and meditation—are close due to their usage.
Dimensionality in vector embeddings
Think of dimensionality as the number of features used to represent a vector. For example, we saw three dimensional numerical vectors that represented each color in terms of three base colors. Dimensionality is crucial in embedding vectors. Generally speaking, the more dimensions a vector is represented with, the more accurate the results are because it holds more information about the vector.
If your task is simple, say just capture the meaning of the sentence, then lower-dimensional vectors are sufficient. However, if your use case is to capture semantic meaning, correct order of words (say for language translation), or context awareness for more complex machine learning systems that process data, then transformer-based embeddings in a high dimensional space will be more accurate.
How vector embeddings work
We can represent different types of data using vector embeddings—text, audio data, video, images, graphs, time-series data, documents, and so on. In the previous sections, we saw how different data can be represented as vectors (numerical representations) for machine learning models to understand not just the literal meaning, but also the semantic meaning.
Capturing semantic relationships
Vector embedding models create embeddings that can perform mathematical operations to capture semantic relationships. We saw how similar words are grouped close together to understand how similar or alike two objects are. Semantic similarity match is particularly helpful to the machine for image recognition (identification of images of dogs based on their features) as well as answering questions (where is the nearest Apple store in my area?).
It’s also helpful in recommendations—“If you liked this movie, I can suggest you more of similar genre/type,” and retrieval-augmented generation—cheap flights, budget airfare, discounted tickets, best deals, and low-cost airlines.
EXAMPLE
To understand how vector embeddings work, consider the sentences: “Today is a bright day” and “The weather is so good today.”
- When these sentences are processed by a model, the words are first converted into word embeddings.
- While traditional sequence models like recurrent neural networks (RNNs) process text tokens in order, transformer models look at all the words in a sentence at the same time using an attention mechanism.
- Through multiple layers, the model refines these relationships so that each word’s representation reflects the context and meaning of the entire sentence.
- From these contextual representations, the model can derive a single vector embedding that represents the meaning of each sentence.
Once these sentence embeddings are created, they can be compared using similarity measures to determine the semantic similarity between the sentences.
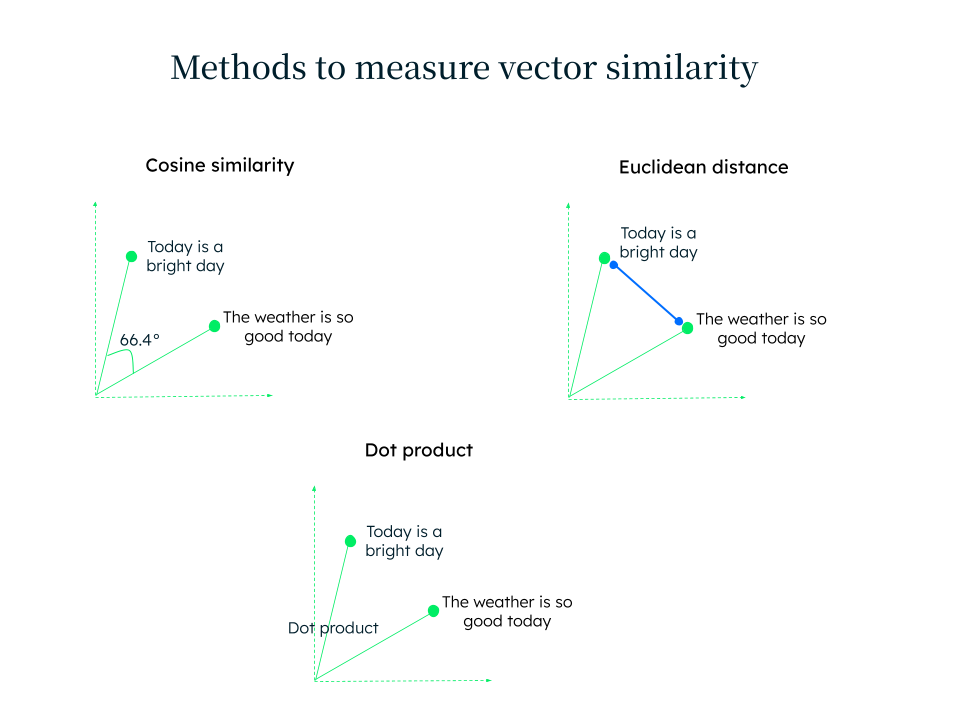
Similarity measurements
Once the preprocessed data is converted to vectors, we can perform mathematical operations on the data points. The similarity between the vectors can be measured using one of these three methods: cosine similarity, Euclidean distance, and dot product.
Cosine similarity
This measures the cosine of the angle between two vectors and is a normalized dot product of vectors. The value of vectors ranges from -1 to 1, where 1 represents highest similarity. This method is useful for comparing documents and sentences for similarity.
The formula to calculate the similarity of sentences/words using the cosine similarity method is below:

Here θ is the angle between the two text embeddings, A is a word from the first sentence, B is a word from the second sentence, i is the number of words in each sentence, and 𝚺 is the sum of the product of words from A and B. i=1 to n indicates the iteration for each word of each sentence.
Consider our previous example: The table below lists each word and the number of times it appears. Following the table is the formula to calculate the cosine. Notice that the dimensions of the text embeddings created is 9, which means there are 9 columns.
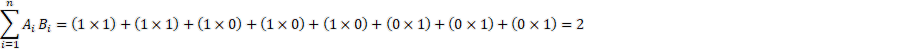



Euclidean distance
This calculates the straight-line shortest path between two points in the Euclidean space. It’s derived from the Pythagoras theorem and is used in computer vision, clustering, and classification tasks. In n-dimensional space, the formula to calculate Euclidean distance d is:

A and B are the points, whose distance we need to find; n is the number of dimensions;and Ai and Bi are the ith attributes of the values A and B respectively.
Calculating the euclidean distance for our previous example, we get the sum of the squared distances (from the table) as:


Dot product
The dot product computes the sum of the products of the corresponding entries of two sequences of numbers. This method, like the cosine similarity method, measures the overlap between the vectors. It’s fast, computationally efficient, and used where the magnitude of the vector is important, such as machine learning algorithms.
For MongoDB vector embeddings, this score can then be used for a myriad of implementations. It can be used for retrieval-augmented generation (RAG), vector search, and more. We’ll talk more about implementation at the end of this article.
Creating vector embeddings
In the above example, we created vector embeddings for two very simple sentences. However, in real-time, there will be lengthy sentences, complex or unpopular words, paragraphs, full documents, images, audios, videos, and even mixed types of data with text, image. and other types of media.
Types of vector embeddings
The different types of vector embeddings are described in the table below.
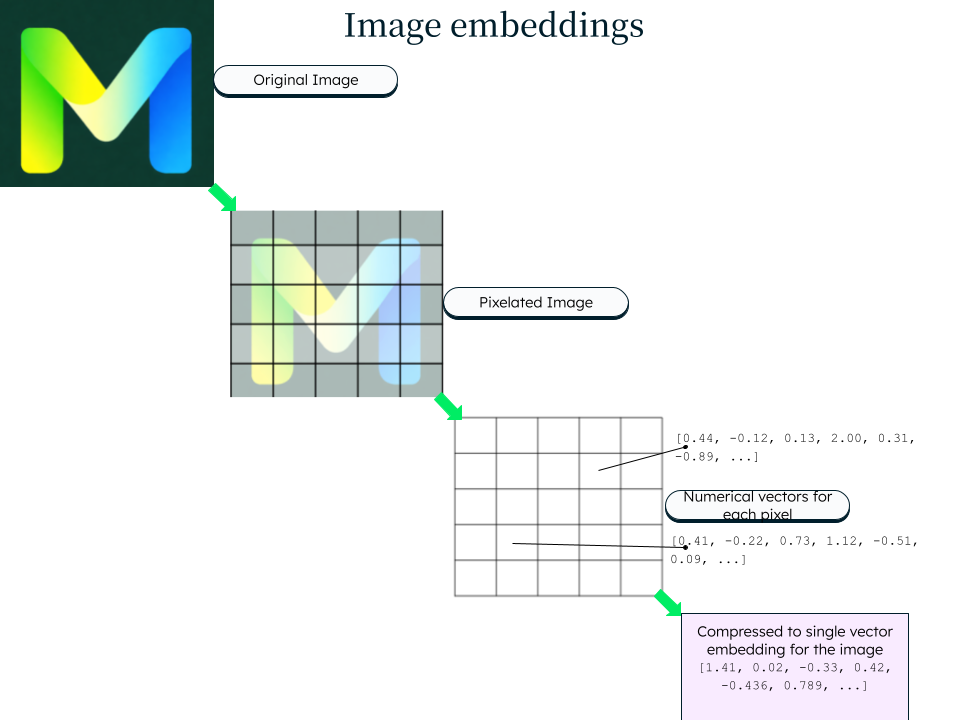
An example of image embedding is shown below.
Advantages of vector embeddings
Representing data in high‑dimensional spaces makes it useful across a wide range of applications. Vector embeddings help with sentiment analysis by detecting emotional tone in text, support machine translation by preserving meaning across languages, and power chatbots and virtual assistants to interpret queries naturally. They also enhance information retrieval in search engines and recommendation systems by categorizing data based on semantic similarity rather than keyword matching like we may see with full text search. By placing similar data points together, vector embeddings excel at text classification tasks such as spam filtering or content categorization.
Challenges and limitations
Vector embeddings are powerful, yet face several challenges that affect their effectiveness and fairness. Large language models often struggle with out‑of‑vocabulary words, contextual ambiguity, and transferability across languages, while embeddings can also inherit biases from training data. Maintaining and updating models could become complex because language evolves constantly and training requires huge volumes of high‑quality data, which may not be available for all domains or languages.
Further, embeddings demand significant computational resources to perform arithmetic operations on multiple dimensions, making them harder to scale for smaller organizations. As tasks grow in complexity, scalability too becomes a hurdle.
Use cases of vector embeddings
Vector embeddings are widely used across machine learning algorithms to represent complex data in high‑dimensional spaces. In natural language processing (NLP), they capture semantic meaning for tasks like sentiment analysis, translation, and text classification. In computer vision, embeddings represent images or image parts, enabling recognition, classification, similarity detection, and image generation. Recommendation systems use embeddings to make personalized suggestions based on similarity.
Embeddings play a role in bioinformatics by representing gene sequences or protein structures for predictive tasks, in graph analysis by modeling nodes and edges for link prediction and social network insights, and in time series analysis by capturing temporal patterns in financial or sensor data. These diverse applications highlight embeddings as a versatile tool across domains, not limited to language alone.
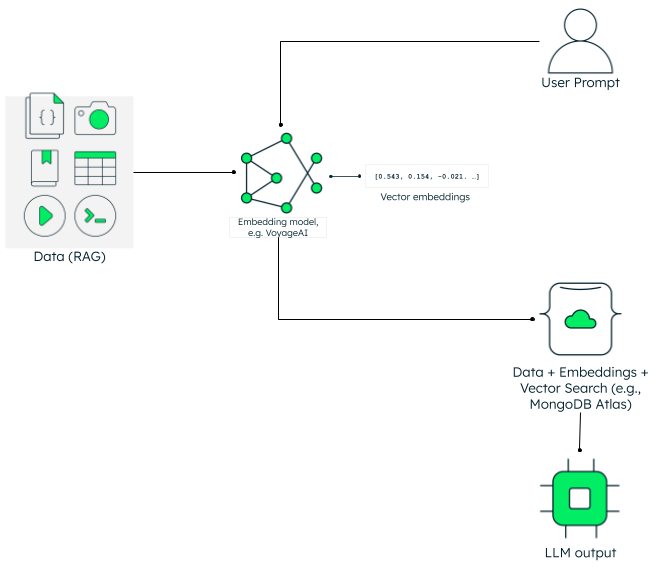
Vector embeddings and RAG
To get better responses and reduce hallucinations, the RAG framework uses semantic search and provides LLMs with contextually relevant data.
In a RAG architecture, embedding models like VoyageAI convert incoming data into vector embeddings and this corpus of data is then stored in a vector store. MongoDB Atlas provides an efficient way to store vector embeddings alongside data, eliminating the need for separate vector databases. Read more to know about which embedding model to choose for your LLM application.
Using VoyageAI and MongoDB Atlas for vector embeddings and vector search
MongoDB Vector Search is a built-in advanced tool designed to handle semantic similarity searches. It leverages the strengths of MongoDB's flexible data model and semantic search capabilities, making it a powerful solution for search and generative AI applications.
Voyage AI has state-of-the-art embedding models and re-rankers focused on search and retrieval that enables applications to extract meaning from any type of embedding, like word embeddings, sentence embeddings, image embeddings, multi-modal embeddings and so on.
Together, these features bring highly accurate and efficient data retrieval and search to AI workloads in MongoDB Atlas.
Consider the example of a user query: “find me a comfortable and affordable place to stay in NY”. We know that MongoDB stores data as collections and documents. Let’s say all the data about various types of accommodations, like a hotel, rented apartment, OYO rooms etc, are already stored in a MongoDB collection. With MongoDB Atlas, you can easily store the vector embeddings of the data, alongside the data itself. You also create a vector search index, for efficient retrieval. Further, VoyageAIs reranking model can re-rank the documents to get more precise results.

Once the above query is received by a search engine, chatbot, or travel assistance websites (any LLM application), it’s fed to VoyageAI for creating text embeddings. The embeddings are queried against the already stored accommodation details using MongoDB Vector search, bringing out the relevant results. MongoDB Vector Search performs k-nearest neighbor (k-NN) search, using approximate nearest neighbor (ANN) algorithms such as HNSW as well as exact nearest neighbor (ENN) search, to find the most relevant results. It also supports multiple similarity measurement algorithms. The results are then fed to the VoyageAI reranking model to further improve the quality of results.
Why use MongoDB Atlas and VoyageAI?
- Seamless integration: MongoDB Vector Search is built into MongoDB Atlas, allowing you to use the same database for both structured and unstructured data. This integration simplifies your architecture and data management processes and eliminates the need for separate vector databases.
- Scalability: MongoDB Atlas provides a highly scalable environment that can handle large volumes of data, making it ideal for applications requiring extensive vector searches.
- Accuracy: Voyage AI can generate embeddings that better capture meaning across text and multimodal data, while improving retrieval accuracy through advanced reranking models that refine search results for AI-powered applications.
- Flexible indexing: MongoDB's indexing capabilities enable efficient storage and retrieval of vector data, ensuring fast and accurate search results.
- Multi-cloud availability: MongoDB Vector Search is available across major cloud providers, ensuring flexibility and reliability.
- Security: Benefit from MongoDB's advanced security features, including encryption at rest and in transit, role-based access control, and comprehensive auditing.
Conclusion
Vector embeddings represent a significant leap in how machines process and understand data. From enhancing the capabilities of natural language processing in large language models, to their applications in fields like image search, object detection, object recognition, numerical vectors have proven to be invaluable. As technology evolves, so will the sophistication and utility of vector embeddings.
By storing vector embeddings in documents alongside metadata and contextual app data in a single, unified, fully managed, secure platform, developers can enjoy a seamless, flexible, and simplified experience, without additional vector databases. MongoDB's robust integrations with all major AI services and cloud providers enables developers to use the embedding model of their choice and then perform indexing and searching, building apps efficiently and securely all in one place. Further, VoyageAIs advanced embedding and reranking capabilities bring more precision to the results.
Learn more on how MongoDB and VoyageAI are used together to revolutionize information retrieval.
To see how MongoDB Vector Search works, visit the MongoDB Vector Search Quick Start Guide to create your first index in minutes.