Does MongoDB support stored procedures?
Modern databases have redefined the strategies for addressing complex queries and data manipulation tasks. For example, MongoDB has harnessed the power of the document model as well as advanced techniques such as aggregation pipelines, which provide a powerful and flexible mechanism for performing data transformations and analysis, akin to the functionalities traditionally achieved through a stored procedure.
Thus, In MongoDB, a stored procedure is not necessary as in relational databases.
Stored functions in MongoDB
In earlier versions of MongoDB, a concept similar to stored procedures, called stored functions, was available. These JavaScript functions could be stored on the server and later reused as part of a map-reduce API.
However, both stored functions and map-reduce API have been deprecated. A wide variety of stages and operators within the aggregation pipeline have significantly reduced the need for custom code.
The modern equivalent of stored procedures
MongoDB replaces traditional stored procedures with powerful, flexible, and efficient alternatives tailored to the demands of today's digital landscape.
A host of features available in the database and additional features available on the developer data platform, MongoDB Atlas, simplify building modern applications.
Some of the features in MongoDB are:
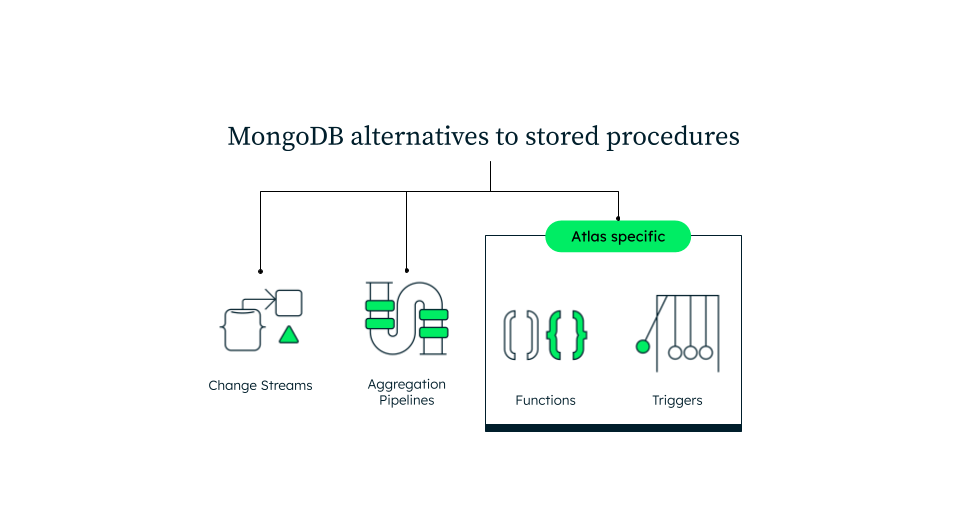
Aggregation pipelines: Process and analyze data records, grouping values from multiple documents and performing operations on grouped data to deliver results in a single set.
Change Streams: Subscribe to real-time data changes for single collections, databases, and entire deployments, with the ability to leverage aggregation pipelines for filtering or transforming notifications.
Atlas, the developer data platform, provides additional features like:
Atlas functions: Server-side JavaScript functions define app behavior, allowing direct calls from client applications or integration with services like Atlas triggers and Atlas API services for automatic execution.
Atlas triggers: Automatically execute serverless functions in response to events or on a schedule. Triggers and functions run on a serverless compute layer that scales independently of the database server, unlike traditional SQL data triggers.
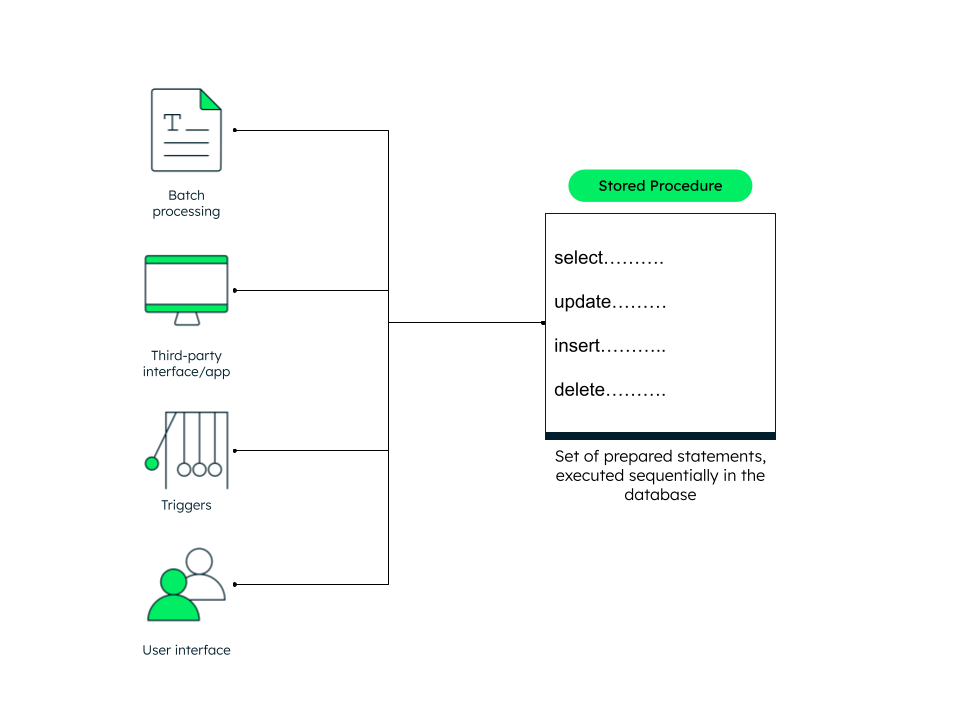
Stored procedures are often used when complex queries need to be performed on the database server. In MongoDB, this is where aggregation pipelines shine.
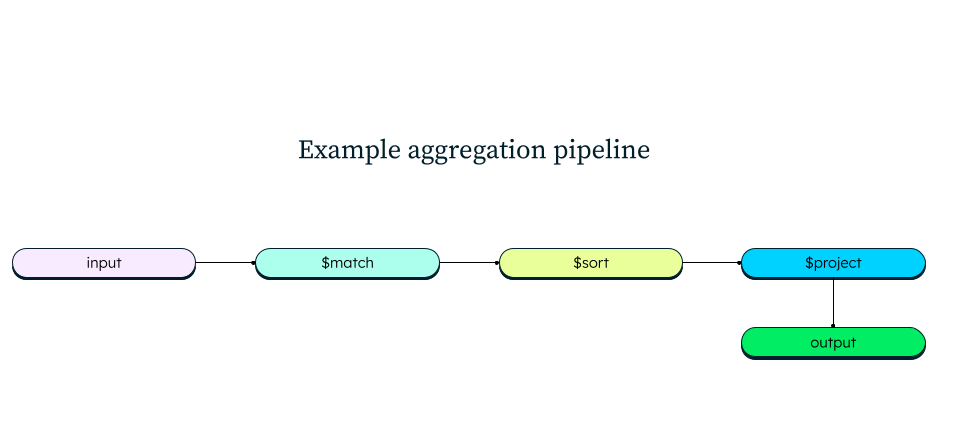
An aggregation pipeline consists of one or more stages that process documents:
Each stage performs an operation on the input documents. For example, a stage can filter documents, group documents, and calculate values.
The documents that are output from a stage are passed to the next stage.
An aggregation pipeline can calculate results for groups of documents. For example, compute the total, average, maximum, and minimum values.
In this example, we are breaking down how an aggregation pipeline functions in MongoDB.
Aggregations are best suited to:
- Group values from multiple documents together.
- Perform operations on the grouped data to return a single result.
- Analyze data changes over time.
The aggregation pipelines framework is a fully Turing complete programming language and can be used for many things, ranging from complex data analytics to mining bitcoins.
Aggregation pipelines can be called directly from your application using one of the native drivers to connect to your database.
The MongoDB Atlas web UI (user interface) provides an easy-to-use interface to learn how to build aggregation pipelines. Compass, the GUI for MongoDB, also offers an interface to build pipelines. It even includes previews at each of the stages to better understand how to optimize your queries.
The Practical MongoDB Aggregation book is a valuable resource for learning more about aggregation pipelines and how to use them optimally.
Change streams
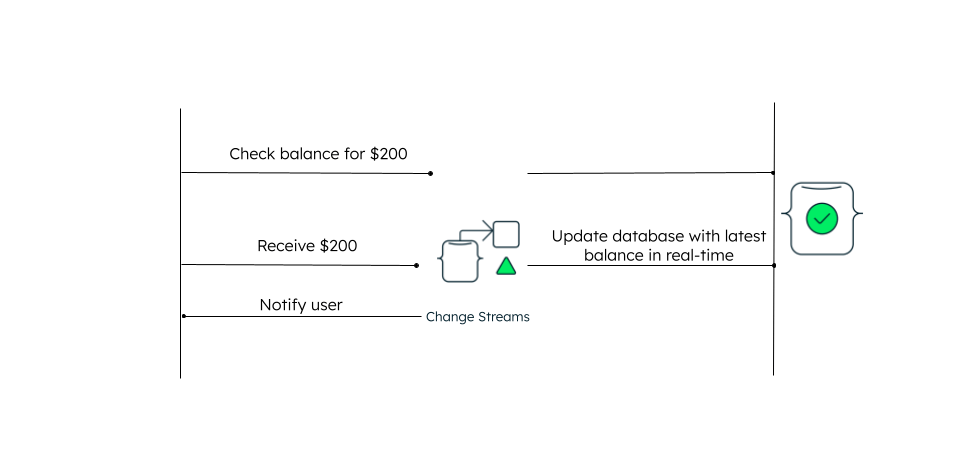
A change stream is a MongoDB feature that allows an application to sync and access real-time data, and react to the real-time stream of data from the database to your application. Change streams are well-suited for event-driven architecture and provide a more dynamic and flexible approach to database events without the need to run scheduled jobs or stored procedures.
Consider an example of a banking platform that needs to update database changes as fast as possible. Let’s say you want to pay $200 for a purchase but are running short. You ask a friend to transfer the amount to your account, so you in turn can pay the merchant. All this needs to happen in real time for the transactions to be successful. Change streams update database changes in real time, enabling you to get the latest amount as soon as it is put in the account.
Atlas functions and triggers
In MongoDB Atlas, when functions need to be stored on the database server, you can use Atlas functions. You can then invoke these functions via Atlas triggers or Atlas API services. These services run on a fully managed, serverless compute layer that scales independently from the database server, allowing you to implement them quickly without the hassle of spinning up or managing an app server.
Atlas functions use ES6+ JavaScript and can import Node.js modules, just like any other Node.js application that you would run on your server.