Storing unstructured data is the first step of data analysis.
But what constitutes unstructured data? Is it really unstructured? Let’s take a closer look.
Although unstructured data has an internally predefined structure, it does not follow a fixed data model. Unstructured data may not always fit into a structure predefined by a structured database or data table. Here are some examples:
- Social media data—Social media text such as comments and feedback are unstructured, but social media data like friends, followers, and likes are structured.
- Email—The body copy is unstructured, whereas the “to,” “cc,” and “subject” fields are structured.
- Multimedia—This can be represented in multiple ways, including vectors, bitmaps, GIFs, frames, and so on, making them unstructured.
Unstructured data forms about 80% of big data. Businesses use various unstructured data analysis techniques and tools to get insights from unstructured data. However, storing unstructured big data is complex because of its usually high volume, variety, and velocity.
In this article, we’ll discuss:
Unstructured data storage challenges
No fixed format
Suppose you have to store details about all the employees of an organization. One employee may own many cars or have more than one child. Another may not have either of these. Because of this, each employee has characteristics that others might not have, and we don't necessarily require all of the fields for all of the employees.
In a relational database, we would be creating fields for each of these, many of which might be unused. In addition, if we later want to add new fields, like car insurance details, we'd need a schema change and downtime. With no predefined format of unstructured data, this could soon become a nightmare.
Scaling issues
As the amount of unstructured data keeps increasing, traditional storage systems may not scale out. Adding more resources (disks) to the system will increase the cost—and you cannot do so indefinitely, because the data will again outgrow the number of disks. Scaling out is not easy with a relational database—the system performance suffers because the table joins across nodes become too complex.
Complex data retrieval and querying
If you just dump all the big data into a storage system, not knowing what to do with it, the data will lie there without adding any value. For example, once you store multimedia data, you may not get an efficient way to find, update, or even delete it, even with indexing.
Therefore, to handle unstructured data, you need storage infrastructure that can scale out and provide efficient data management. A good example of such storage is an object database, where the entire data is an object and has metadata and a unique id to easily identify data.
Storage requirements for unstructured data
Companies should strategize storing unstructured data during the planning phase of a big data project. The storage infrastructure should be agile, cost-effective, scalable, and cater to a wide range of use cases.
Consider the following requirements for unstructured data storage:
Flexibility
The data model should be flexible to accommodate new fields and data types with minimum impact on existing schema or data, thus requiring no downtime.
The article NoSQL explained details how NoSQL databases, like MongoDB, are flexible enough to store vast amounts of data in varied formats.
Purpose
If your workload is mainly analytics, you need a robust storage system that supports low latency and faster data updates. Cloud storage would be a good option for this purpose as opposed to an on-premise system.
Easy access to archived data
Data archiving prevents data loss, and reduces the cost of primary storage. Data that is old but still required should be stored in such a way that it’s easy to retrieve and doesn’t increase overall storage cost.
Scalability
The storage system should be horizontally and vertically scalable at all times without any data loss. Modern storage systems like AWS and Azure provide automatic scaling depending on the application requirements.
A NoSQL database is a good approach that satisfies all the above unstructured data storage requirements. To handle scalability and online archiving capabilities as the data continues to grow, cloud-based databases like MongoDB Atlas and a database-as-a-service like MongoDB clusters are excellent options.
Best options for storing unstructured data
Now that you understand the requirements of unstructured data storage and the challenges that relational databases pose for storing unstructured data, we’ll discuss some robust ways to store unstructured big data.
You can store unstructured data on-premise or in the cloud using a database, data warehouse, or data lake.
While cloud storage does offer security, companies might prefer on-premise storage for highly sensitive data.
Non-relational database for storing unstructured data
Non-relational (NoSQL) databases have emerged as a convenient way of storing unstructured big data. They are flexible, scalable, highly available, secure, and help to minimize the unstructured data storage challenges. NoSQL databases make data management more efficient and cost-effective.
There are various types of NoSQL database systems. One type is the document (object) store, which provides a simple query mechanism to quickly retrieve data as the system recognizes the data structure. Documents consist of various attributes with different data types. Document stores are highly scalable and available by design, and can partition, replicate, and persist the data. MongoDB is a document-based NoSQL database that stores data in a BSON (JSON-like format). Such a format is easy to read and traverse. MongoDB is also suitable for handling transactional data.
{
"studentID": "stud20210903",
"name" : "Ben Park",
"address": {
"zip" : "W1J9LL",
"city" : "London",
},
"hobbies": ["gardening", "travelling", "reading"],
"familydetails":{
"motherName": "Alicia",
"fatherName": "Ricky",
"sibling":["Carol"]
}
}If you were to store the above information in a relational database, you’d probably need three or more tables and would need to join the tables to see all this information in one view.
MongoDB Atlas, MongoDB’s database-as-a-service, utilizes major cloud platforms like AWS, Azure, and Google Cloud for its database servers. This means you don’t need to install MongoDB and still get all the benefits of a NoSQL document database in a cloud environment.
Unstructured data storage with data lake
A data lake is a central storage repository that stores data in its native format. It uses flat architecture to store data, usually as object or file storage. Data lakes are vast and store any amount of unstructured, structured, or semi-structured big data. They work on the schema-on-read principle (i.e., do not have a predefined schema).
The data sources can be IoT devices, streaming data, web applications, and many others. Some of the data ingested might be filtered and ready to use as well — the kind of flexibility impossible with relational databases.
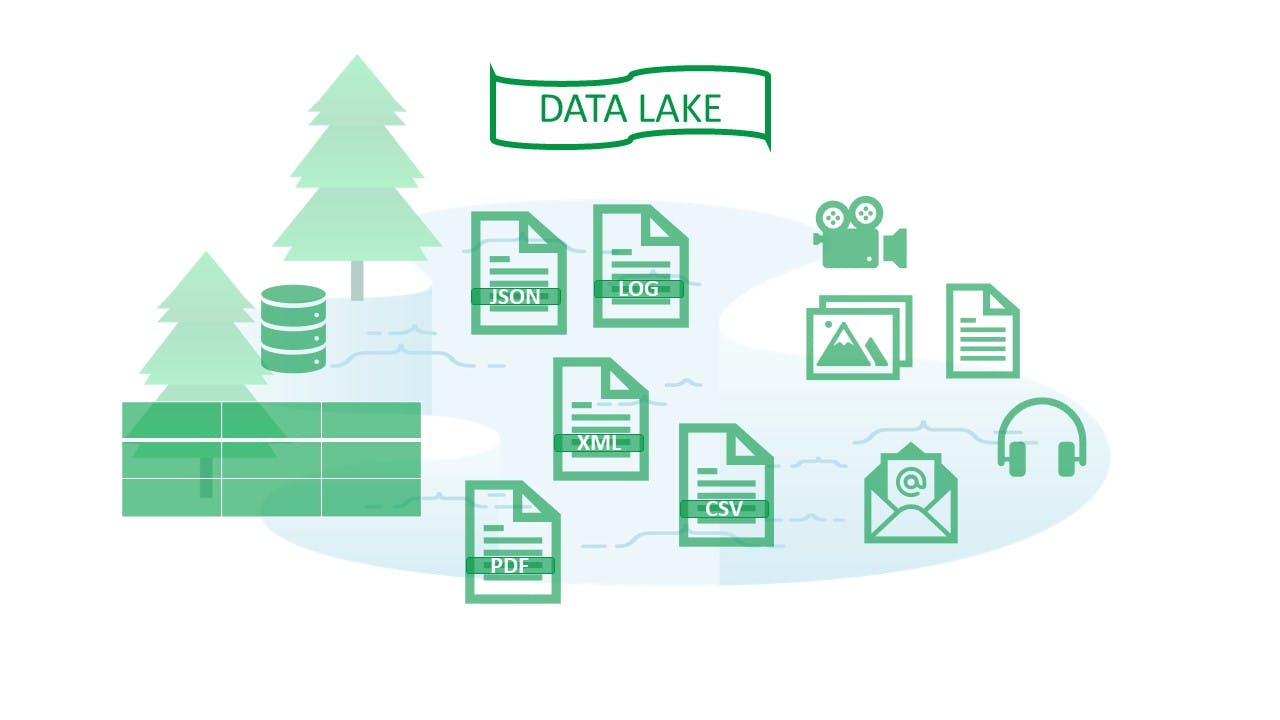
Since data lakes are configured on commodity hardware and clusters, they are highly scalable and inexpensive.
Data lakes can be configured on-premise or in the cloud. Again, on-premise data lakes are suitable for highly sensitive and secure data. However, having a cloud data lake reduces the cost of infrastructure and is easier to scale out.
Data warehouse
A data warehouse is a repository created for analytics and reporting purposes. It usually works on a structured storage (schema-on-write), unlike data lakes. Data warehouses primarily store past and current structured or semi-structured data, which is internal to the organization and available in standard format. Unstructured data (like that from the internet) should be processed and formatted with an ETL step before being ingested into a data warehouse. This makes the data consistent and of high quality—and, therefore, ready for analysis. You can say that a data warehouse is an analytical database used for business intelligence. The schema-based format makes data analysis easier.
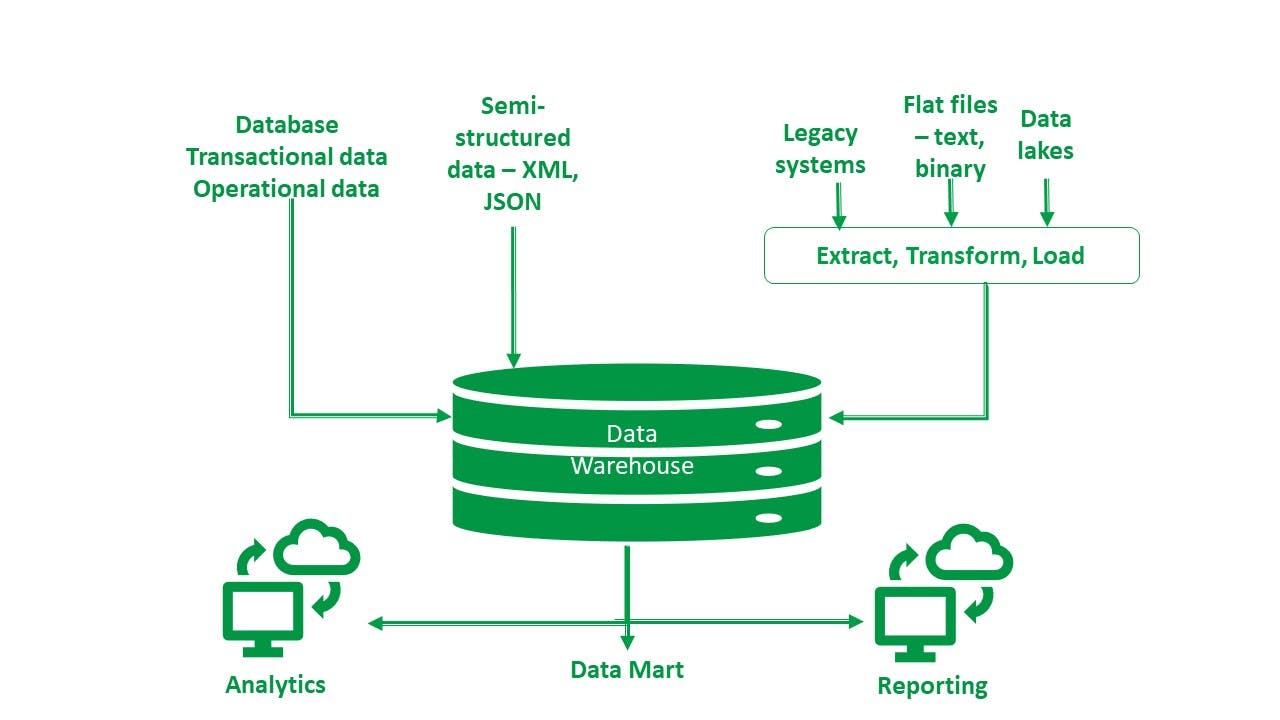
Data warehouses can be on-premise and cloud-based. Cloud data warehouses reduce the cost, deployment process, and infrastructure needs, and can automatically scale based on application needs.
A data mart is a subset of a data warehouse that stores operational data of a particular niche or line of business.
Summary
Unstructured data storage is complex and challenging because of the varied formats and high volume of data. Databases are the simplest way to store data and NoSQL databases have been widely accepted because of their flexible format and ease of data retrieval. MongoDB Atlas makes an excellent choice for a NoSQL database-as-a-service.
Data warehouses accept data from multiple sources and process data to make it ready for analysis. These are ideal for business analysts who want to get insights from data. Data lakes store all the data in its native format—it’s a mix of all types of data, both raw and processed. Data lakes are a perfect place to offload data for future use or compliance.
As a next step, you can learn more by comparing the three best unstructured data options.
FAQs
What is unstructured data storage?
What are the requirements for storing unstructured data?
Unstructured data can be stored on-premise or in the cloud in databases, data lakes, and data warehouses. An unstructured data storage system should:
- Scale out or scale up as required.
- Be cost-effective without extensive infrastructure requirements.
- Cater to varied use cases as opposed to a single particular line of business.
- Have flexible schemas that can support various data types.
- Provide powerful yet simple query capabilities to filter required data.
Which storage solution should you lead with for unstructured data?
Some popular storage options for unstructured data are NoSQL databases, data lakes, and data warehouses. These provide scalability, flexible schema, and efficient data management. MongoDB Atlas is an excellent cloud database that can satisfy all the unstructured data storage requirements.
Where is unstructured data stored?
How does unstructured data look?
Can NoSQL handle unstructured data?
How do you store unstructured data in a data lake?
Data lakes store unstructured data in its native format. Unstructured data can be ingested in its raw format, along with other structured data. The main considerations while storing unstructured data in a data lake are:
- Simplify the data ingestion process, especially for volumes as large as terra- and peta-bytes.
- Ensure that the data can be repurposed for business use within the data lake.
What is a data lake storage?
Data lakes are typically based on storage and compute units that allow several different storage systems like S3 or HTTP-based storage. The compute units are optimized to interact with the storage layer and provide a good query and processing language to the clients.