高可用性是指您的应用程序在基础设施服务中断、系统维护和其他干扰期间,确保持续操作并最大限度地减少停机时间的能力。MongoDB 的默认部署架构专为高可用性而设计,具有内置的数据冗余和自动故障转移功能。本页描述了您可以选择的其他配置选项和部署架构增强,以防止服务中断并支持针对可用区、区域和云提供商服务中断的强大故障转移机制。
Atlas 高可用性功能
数据库复制
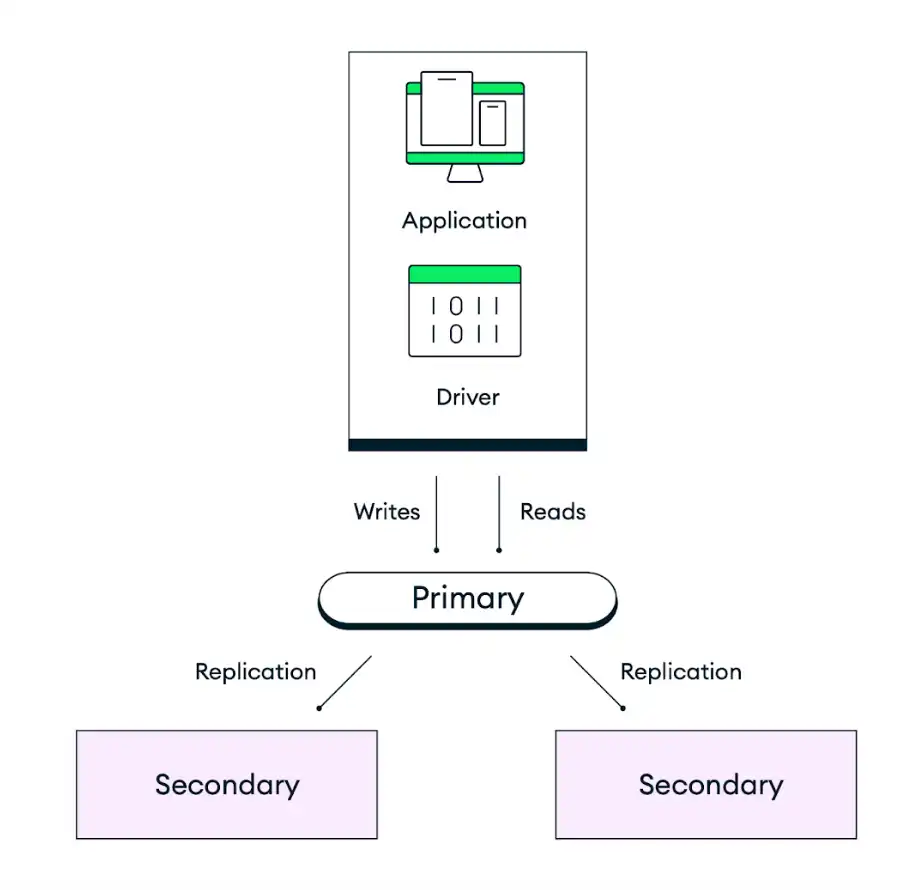
MongoDB 的默认部署架构专为冗余而设计。Atlas 将每个集群部署为副本集,其中至少包含三个数据库实例(也称为节点或副本集成员),分布在所选云提供商区域内的不同可用区中。应用程序将数据写入副本集的主节点,然后 Atlas 在集群中的所有节点上复制并存储这些数据。要控制数据存储的耐久性,您可以调整应用程序代码的写关注,只有在一定数量的从节点提交写入后,才完成写入。默认行为是数据在确认操作之前会持久化到大多数可选举节点上。
下图表示默认三节点副本集的复制工作原理:

自动故障转移
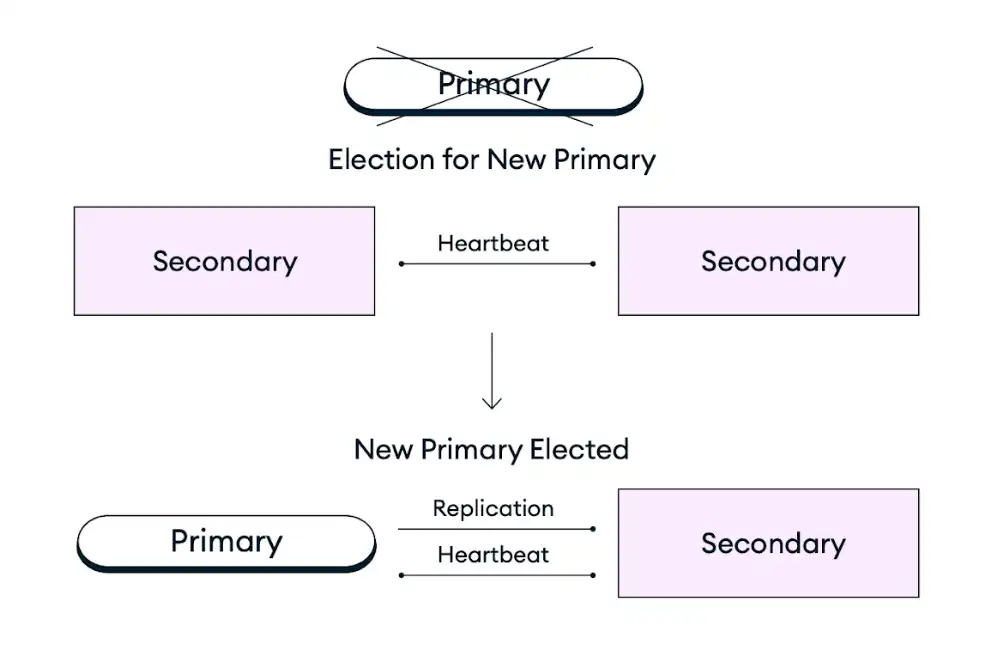
如果副本集中的主节点因基础设施服务中断、计划维护或其他任何干扰而不可用,Atlas 集群会通过在副本集选举中将现有的从节点提升为主节点来实现自我修复。故障转移过程是全自动的,并在几秒钟内完成,不会丢失任何数据,包括故障发生时正在进行的操作。如果启用了可重试写入,这些操作将在故障发生后重试。在副本集选举后,Atlas 会恢复或替换故障节点,以确保集群尽快恢复到目标配置。MongoDB 客户端驱动程序还会在故障期间和之后自动切换所有客户端连接。
下图表示副本集选举过程:

为了提高最关键应用程序的可用性,您可以通过添加节点、区域或云提供商来扩展部署,以分别抵御区、区域或提供商的服务中断。要了解更多信息,请参阅下面的扩展您的部署范式以实现容错建议。
关于 Atlas 高可用性的建议
以下建议描述了您可以使用的其他配置选项和部署架构增强,以提高部署的可用性。
选择适合您部署目标的集群层
创建新集群时,您可以在专用、Flex 或免费部署类型下的一系列集群层中进行选择。MongoDB Atlas 中的集群层指定了集群中每个节点的可用资源(内存、存储、vCPU 和 IOPS)。扩展到更高的层级可以增强集群处理流量高峰的能力,并通过更快地响应高工作负载来提高系统的可靠性。要确定适合您应用程序大小的推荐集群层,请参阅 Atlas 集群大小指南。
Atlas还支持自动伸缩,允许集群自动调整以适应需求高峰。自动化此操作可降低因资源限制而导致服务中断的风险。要了解更多信息,请参阅 Atlas 自动化基础设施预配指导。
扩展您的部署范式以实现容错
Atlas 部署的容错性可以通过在部署仍保持运行时可能变为不可用的副本集成员数量来衡量。在可用区、区域或云提供商发生服务中断时,Atlas 集群会通过在副本集选举中将现有的从节点提升为主节点来实现自我修复。副本集中的大多数投票节点必须处于正常运行状态,以便在主节点发生服务中断时运行副本集选举。
为确保副本集在部分区域服务中断时能够选举出主节点,您应将集群部署到至少有三个可用区的区域。可用区是单个云提供商区域内独立的数据中心组,每个数据中心都有自己的电力、冷却和网络基础设施。当您选择的云提供商区域支持可用区时,Atlas 会自动将您的集群分布在这些可用区中,以便在某个可用区发生服务中断时,集群中的其他节点仍然支持区域服务。大多数 Atlas 支持的云提供商区域至少有三个可用区。这些区域在 Atlas 用户界面中标记有星形图标。如需了解推荐区域的更多信息,请参阅云提供商和区域。
为了进一步提高您最关键的应用程序的容错能力,您可以通过添加节点、区域或云提供商来扩展部署,以分别应对可用区、区域或提供商的服务中断。您可以将节点数增加到任意奇数,可选举节点数最多为 7 个,节点总数最多为 50 个。您还可以将集群部署到多个区域,以增强更大地理区域的可用性,并在发生全区域服务中断导致主区域内所有可用区禁用的情况下启用自动故障转移。同样的模式也适用于将您的集群部署到多个云提供商,以应对整个云提供商的服务中断。
有关如何选择能够平衡高可用性、低延迟、合规性和费用需求的部署的指导,请参阅我们的 Atlas 部署范式文档。
防止意外删除集群
您可以启用终止保护,以确保集群不会被意外终止,并且不需要停机即可从备份恢复。要删除已启用终止保护的集群,必须先禁用终止保护。默认情况下,Atlas 会禁用所有集群的终止保护。
启用终止保护在使用 Terraform 等 IaC 工具时尤为重要,以确保重新部署不会预配新的基础设施。
测试自动故障转移
在将应用程序部署到生产环境之前,我们强烈建议您模拟各种需要自动节点故障转移的场景,以评估您对这些事件的准备情况。使用 Atlas,您可以针对副本集测试主节点故障转移,并模拟多区域部署的区域性服务中断。
使用majority写关注
MongoDB 允许您通过使用写关注来指定写入操作所需的确认级别。Atlas 的默认写关注为 majority,这意味着数据必须复制到集群中超过一半的节点后,Atlas 才会报告成功。使用 majority 而不是像 2 这样的确定数字值,可以让 Atlas 在遇到临时节点服务中断时自动调整为在更少的节点上进行复制,从而在自动故障转移后继续允许写入。这也为所有环境提供了一致的设置,因此无论您在测试环境中有三个节点还是在生产环境中有更多节点,您的连接字符串都保持不变。
配置可重试的数据库读写操作
Atlas 支持可重试读取和可重试写入操作。启用后,Atlas 会重试读写操作一次,以防止因间歇性网络中断或副本集选举而导致应用程序暂时无法找到健康主节点。可重试写入需要已确认的写关注,这意味着您的写关注不能是 {w:
0}。
监控和规划您的资源使用情况
为避免资源容量问题,我们建议您监控资源利用率,并定期开展容量规划会话。MongoDB Professional Services 提供这些会话。请参阅我们的资源容量灾难恢复计划,以获取我们关于如何从资源容量问题中恢复的建议。
要了解资源利用警报和监控的最佳实践,请参阅 Atlas 监控和警报指导。
规划您的 MongoDB 版本更改
: 我们建议您运行最新的 MongoDB 版本,以便利用新功能并获得更强的安全保证。您应始终确保在当前版本结束生命周期之前升级到最新的 MongoDB 主版本。
您无法使用 Atlas 用户界面降级 MongoDB 版本。因此,我们建议您在计划和执行主要版本升级时直接与 MongoDB 的Professional Services或技术服务合作,以帮助您避免在升级过程中可能出现的任何问题。
配置维护窗口
在计划维护期间,Atlas 通过滚动更新的方式逐一对节点进行更新,以保持正常运行时间。在此过程中,每当当前主节点因维护而离线时,Atlas 会通过自动副本集选举选出一个新的主节点。此过程与自动故障转移时的处理方式相同,用于应对主节点的非计划性中断。
我们建议您为您的项目配置自定义维护窗口,以避免在关键业务时段进行与维护相关的副本集选举。您还可以在维护窗口设置中设置受保护时段,以定义一个标准更新无法开始的每日时间窗口。标准更新不涉及集群重启或重新同步。
自动化示例:Atlas 高可用性
以下示例使用Atlas 工具配置单区域 3 节点副本集/分片部署拓扑结构以实现自动化。
这些示例还应用其他推荐的配置,包括:
注意
在使用 Atlas CLI 创建资源之前,您必须:
创建您的付款组织并为该付款组织创建一个 API 密钥。
通过使用 Programmatic Use 的步骤从 Atlas CLI 连接。
为每个项目创建一个部署
在您的开发和测试环境中,为每个项目运行以下命令。在以下示例中,更改 ID 和名称以使用您的值。
注意
以下示例未启用自动伸缩功能,以帮助控制开发和测试环境中的费用。对于分阶段和生产环境,应启用自动伸缩功能。请参阅“分阶段环境和生产环境”标签页,以获取启用自动伸缩的示例。
atlas clusters create CustomerPortalDev \ --projectId 56fd11f25f23b33ef4c2a331 \ --region EASTERN_US \ --members 3 \ --tier M10 \ --provider GCP \ --mdbVersion 8.0 \ --diskSizeGB 30 \ --tag bu=ConsumerProducts \ --tag teamName=TeamA \ --tag appName=ProductManagementApp \ --tag env=dev \ --tag version=8.0 \ --tag email=marissa@example.com \ --watch
对于您的暂存环境和生产环境,请为每个项目创建以下 cluster.json 文件。更改 ID 和名称以使用您自己的值:
{ "clusterType": "REPLICASET", "links": [], "name": "CustomerPortalProd", "mongoDBMajorVersion": "8.0", "replicationSpecs": [ { "numShards": 1, "regionConfigs": [ { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 7, "providerName": "GCP", "regionName": "EASTERN_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } } ], "zoneName": "Zone 1" } ], "tag" : [{ "bu": "ConsumerProducts", "teamName": "TeamA", "appName": "ProductManagementApp", "env": "Production", "version": "8.0", "email": "marissa@example.com" }] }
在您创建 cluster.json 文件后,请为每个项目运行以下命令。该命令使用 cluster.json 文件来创建一个集群。
atlas cluster create --projectId 5e2211c17a3e5a48f5497de3 --file cluster.json
有关此示例的更多配置选项和信息,请参阅 atlas clusters create 命令。
注意
在使用 Terraform 创建资源之前,您必须:
创建您的付款组织并为该付款组织创建一个 API 密钥。请在终端中运行以下命令,将您的 API 密钥存储为环境变量:
export MONGODB_ATLAS_PUBLIC_KEY="<insert your public key here>" export MONGODB_ATLAS_PRIVATE_KEY="<insert your private key here>"
重要
以下示例使用 MongoDB Atlas Terraform 提供商版本 2.x(~> 2.2)。如果您正在从提供商版本 1.x 升级,请参阅 2.0.0 升级指南 了解破坏性变更和迁移步骤。这些示例使用带 v2.x 语法的mongodbatlas_advanced_cluster 资源。
创建项目和部署
对于您的开发和测试环境,请为每个应用程序和环境对创建以下文件。将每个应用程序和环境对的文件放在各自的目录中。更改 ID 和名称以使用您的值:
main.tf
# Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalDev" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Test" Version = "8.0" Email = "marissa@example.com" } # MongoDB recommends enabling auto-scaling # When auto-scaling is enabled, Atlas may change the instance size, and this lifecycle # block prevents Terraform from reverting Atlas auto-scaling changes # that modify instance size back to the original configured value lifecycle { ignore_changes = [ replication_specs[0].region_configs[0].electable_specs.instance_size ] } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.0.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
注意
要创建多区域集群,请在各自的 region_configs 对象中指定每个区域,并将它们嵌套在 replication_specs 对象中。priority 字段必须按降序排列,并且必须包含介于 7 和 1 之间的值,如下例所示:
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ] # MongoDB recommends enabling auto-scaling # When auto-scaling is enabled, Atlas may change the instance size, and this lifecycle # block prevents Terraform from reverting Atlas auto-scaling changes # that modify instance size back to the original configured value lifecycle { ignore_changes = [ replication_specs[0].region_configs[0].electable_specs.instance_size, replication_specs[0].region_configs[1].electable_specs.instance_size ] }
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Dev" environment = "dev" cluster_instance_size_name = "M10" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
在您创建文件后,导航到每个应用程序和环境对的目录,并运行以下命令以初始化 Terraform:
terraform init
运行以下命令以查看 Terraform 计划:
terraform plan
运行以下命令,为应用程序和环境对创建一个项目和一个部署。该命令使用文件和 MongoDB & HashiCorp Terraform 来创建项目和集群:
terraform apply
当出现提示时,输入 yes,然后按 Enter 以应用配置。
对于您的暂存环境和生产环境,请为每个应用程序和环境对创建以下文件。将每个应用程序和环境对的文件放在各自的目录中。更改 ID 和名称以使用您自己的值:
main.tf
# Create a Group to Assign to Project resource "mongodbatlas_team" "project_group" { org_id = var.atlas_org_id name = var.atlas_group_name usernames = [ "user1@example.com", "user2@example.com" ] } # Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Assign the team to project with specific roles resource "mongodbatlas_team_project_assignment" "project_team" { project_id = mongodbatlas_project.atlas-project.id team_id = mongodbatlas_team.project_group.team_id role_names = ["GROUP_READ_ONLY", "GROUP_CLUSTER_MANAGER"] } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalProd" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 disk_size_gb = var.disk_size_gb } auto_scaling = { disk_gb_enabled = var.auto_scaling_disk_gb_enabled compute_enabled = var.auto_scaling_compute_enabled compute_max_instance_size = var.compute_max_instance_size } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] # Prevent Terraform from reverting auto-scaling changes lifecycle { ignore_changes = [ replication_specs[0].region_configs[0].electable_specs.instance_size, replication_specs[0].region_configs[0].electable_specs.disk_size_gb ] } tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Production" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
注意
要创建多区域集群,请在各自的 region_configs 对象中指定每个区域,并将它们嵌套在 replication_specs 对象中,如下例所示:
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" environment = "prod" cluster_instance_size_name = "M30" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0" atlas_group_name = "Atlas Group"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
在您创建文件后,导航到每个应用程序和环境对的目录,并运行以下命令以初始化 Terraform:
terraform init
运行以下命令以查看 Terraform 计划:
terraform plan
运行以下命令,为应用程序和环境对创建一个项目和一个部署。该命令使用文件和 MongoDB & HashiCorp Terraform 来创建项目和集群:
terraform apply
当出现提示时,输入 yes 然后按 Enter 以应用配置。
有关此示例的更多配置选项和信息,请参阅 MongoDB & HashiCorp Terraform 和 MongoDB Terraform 博客文章。