所有操作符都可以使用以下分数修改选项。有关详细信息和示例,请单击以下任一选项:
boost
boost 选项将结果的基本分数乘以给定的数字或文档中数值字段的值。例如,您可以使用 boost 提高某些匹配文档在结果中的重要性。
注意
不能同时使用
boost和constant选项。boost选项与path的乘法与使用function选项与路径表达式的乘法相同。
字段
boost 选项包含以下字段:
字段 | 类型 | 必要性 | 说明 |
|---|---|---|---|
| float | 可选的 | 与默认基本分数相乘的数字。值必须是正数。 |
| 字符串 | 可选的 | 数字字段的名称,其值要乘以默认基数分数。 |
| float | Optional | 用来替换 |
示例
以下示例使用 sample_mflix数据库中的 movies集合。如果集群上有示例数据集,则可以创建MongoDB Search default索引并在集群上运行示例查询。
复合查询示例展示了如何提高一种搜索条件相对于另一种搜索条件的重要性。查询包括一个 $project 阶段,以排除 title 和 score 以外的所有字段。
在以下示例中,复合操作符使用文本操作符在 plot 和 title 字段中搜索术语 Helsinki。对 title 字段的查询使用带有 boost 选项的 score,按照 value 字段的规定,将得分结果乘以 3。
1 db.movies.aggregate([ 2 { 3 "$search": { 4 "compound": { 5 "should": [{ 6 "text": { 7 "query": "Helsinki", 8 "path": "plot" 9 } 10 }, 11 { 12 "text": { 13 "query": "Helsinki", 14 "path": "title", 15 "score": { "boost": { "value": 3 } } 16 } 17 }] 18 } 19 } 20 }, 21 { 22 "$limit": 5 23 }, 24 { 25 "$project": { 26 "_id": 0, 27 "title": 1, 28 "plot": 1, 29 "score": { "$meta": "searchScore" } 30 } 31 } 32 ])
此查询返回以下结果,在该结果中,对于 title 与查询词匹配的文档,其分数为基值乘以 3:
[ { plot: 'Epic tale about two generations of men in a wealthy Finnish family, spanning from the 1960s all the way through the early 1990s. The father has achieved his position as director of the ...', title: 'Kites Over Helsinki', score: 12.2470121383667 }, { plot: 'Alex is Finlander married to an Italian who works as a taxi driver in Berlin. One night in his taxi come two men with a briefcase full of money. Unluckily for Alex, they are being chased by...', title: 'Helsinki-Naples All Night Long', score: 9.56808090209961 }, { plot: 'The recession hits a couple in Helsinki.', title: 'Drifting Clouds', score: 4.5660295486450195 }, { plot: 'Two teenagers from Helsinki are sent on a mission by their drug dealer.', title: 'Sairaan kaunis maailma', score: 4.041563034057617 }, { plot: 'A murderer tries to leave his criminal past in East Helsinki and make a new life for his family', title: 'Bad Luck Love', score: 3.6251673698425293 } ]
在以下示例中,复合操作符使用文本操作符在 plot 和 title 字段中搜索术语 Helsinki。针对 title 字段的查询使用带有 boost 选项的 score 将分数结果乘以 path 中的数值字段 imdb.rating。如果在指定的 path 中找不到数字字段,则操作符会将文档的分数乘以 3。
1 db.movies.aggregate([ 2 { 3 "$search": { 4 "compound": { 5 "should": [{ 6 "text": { 7 "query": "Helsinki", 8 "path": "plot" 9 } 10 }, 11 { 12 "text": { 13 "query": "Helsinki", 14 "path": "title", 15 "score": { 16 "boost": { 17 "path": "imdb.rating", 18 "undefined": 3 19 } 20 } 21 } 22 }] 23 } 24 } 25 }, 26 { 27 "$limit": 5 28 }, 29 { 30 "$project": { 31 "_id": 0, 32 "title": 1, 33 "plot": 1, 34 "score": { "$meta": "searchScore" } 35 } 36 } 37 ])
此查询返回以下结果,其中 title 字段与查询术语匹配的文档的分数由其基值乘以数字字段 imdb.rating 或 3 的值(如果文档中没有该字段):
[ { plot: 'Epic tale about two generations of men in a wealthy Finnish family, spanning from the 1960s all the way through the early 1990s. The father has achieved his position as director of the ...', title: 'Kites Over Helsinki', score: 24.902257919311523 }, { plot: 'Alex is Finlander married to an Italian who works as a taxi driver in Berlin. One night in his taxi come two men with a briefcase full of money. Unluckily for Alex, they are being chased by...', title: 'Helsinki-Naples All Night Long', score: 20.411907196044922 }, { plot: 'The recession hits a couple in Helsinki.', title: 'Drifting Clouds', score: 4.5660295486450195 }, { plot: 'Two teenagers from Helsinki are sent on a mission by their drug dealer.', title: 'Sairaan kaunis maailma', score: 4.041563034057617 }, { plot: 'A murderer tries to leave his criminal past in East Helsinki and make a new life for his family', title: 'Bad Luck Love', score: 3.6251673698425293 } ]
constant
constant 选项将基数分数替换为指定的数字。
注意
不得同时使用 constant 和 boost 选项。
示例
以下示例使用 sample_mflix.movies 集合上的默认索引以使用复合运算符查询 plot 和 title 字段。在查询中,文本运算符使用 score 和 constant 选项,将所有得分结果替换为 5,以获得仅与 title 字段的查询匹配的结果。
1 db.movies.aggregate([ 2 { 3 "$search": { 4 "compound": { 5 "should": [{ 6 "text": { 7 "query": "tower", 8 "path": "plot" 9 } 10 }, 11 { 12 "text": { 13 "query": "tower", 14 "path": "title", 15 "score": { "constant": { "value": 5 } } 16 } 17 }] 18 } 19 } 20 }, 21 { 22 "$limit": 5 23 }, 24 { 25 "$project": { 26 "_id": 0, 27 "title": 1, 28 "plot": 1, 29 "score": { "$meta": "searchScore" } 30 } 31 } 32 ])
上述查询返回以下结果,其中仅与 title 字段的查询匹配的文档的分数将替换为指定的 constant 值:
1 [ 2 { 3 plot: 'Several months after witnessing a murder, residents of Tower Block 31 find themselves being picked off by a sniper, pitting those lucky enough to be alive into a battle for survival.', 4 title: 'Tower Block', 5 score: 8.15460205078125 6 }, 7 { 8 plot: "When a group of hard-working guys find out they've fallen victim to their wealthy employer's Ponzi scheme, they conspire to rob his high-rise residence.", 9 title: 'Tower Heist', 10 score: 5 11 }, 12 { 13 plot: 'Toru Kojima and his friend Koji are young student boys with one thing in common - they both love to date older women. Koji is a playboy with several women, young and older, whereas Toru is a romantic with his heart set on on certain lady.', 14 title: 'Tokyo Tower', 15 score: 5 16 }, 17 { 18 plot: 'A middle-aged mental patient suffering from a split personality travels to Italy where his two personalities set off all kinds of confusing developments.', 19 title: 'The Leaning Tower', 20 score: 5 21 }, 22 { 23 plot: 'A documentary that questions the cost -- and value -- of higher education in the United States.', 24 title: 'Ivory Tower', 25 score: 5 26 } 27 ]
embedded
注意
该选项只能与嵌入式文档运算符一起使用。
embedded 选项允许您配置如何:
聚合多个匹配嵌入式文档的分数。
聚合匹配嵌入式文档的分数后,修改 embeddedDocument 操作符的分数。
注意
MongoDB Search embeddedDocuments 类型、 embeddedDocument 操作符和 embedded 评分选项均处于预览状态。
字段
embedded 选项包含以下字段:
字段 | 类型 | 必要性 | 说明 |
|---|---|---|---|
| 字符串 | Optional | 配置如何合并匹配嵌入式文档的分数。值必须是以下聚合策略之一:
如果省略,该字段默认值为 |
| Optional | 指定应用聚合策略后要应用的分数修改。 |
示例
以下示例将对 sample_analytics.transactions 集合使用名为 default 的索引。该索引为 transactions 数组中的文档配置 embeddedDocuments 类型,并为 transactions.symbol 和 transactions.transaction_code 字段配置 string 类型。
例子
{ "mappings": { "dynamic": true, "fields": { "transactions": { "dynamic": true, "fields": { "symbol": { "type": "string" }, "transaction_code": { "type": "string" } }, "type": "embeddedDocuments" } } } }
transactions 字段的示例查询包含一个文档数组,其中的 $limit 阶段将输出限制为 10 个结果,$project 阶段用于执行以下操作:
排除除
account_id和transaction_count之外的所有字段。添加名为
score的字段,该字段应用聚合策略并进一步修改分数。注意
您可以在 embeddedDocument 操作符
operator的score选项中使用function。但是,对于需要使用path选项的函数分数表达式,您为表达式指定的path数字字段必须位于 embeddedDocument 操作符的path内。例如,在以下示例查询中,第 24 行复合操作符的score选项所指定的字段transactions.amount位于第 4 行embeddedDocument操作符的路径transactions中。
该查询会搜索买入 AMD 的帐户,并将最大的单笔 AMD 买入(按股数计算)乘以该帐户在此期间进行的交易数量的 log1p 值。该操作根据以下内容对帐户进行排名:
单次交易中购买的
AMD数量上一周期的交易数
1 db.transactions.aggregate({ 2 "$search": { 3 "embeddedDocument": { 4 "path": "transactions", 5 "operator": { 6 "compound": { 7 "must": [ 8 { 9 "text": { 10 "path": "transactions.symbol", 11 "query": "amd" 12 } 13 }, 14 { 15 "text": { 16 "path": "transactions.transaction_code", 17 "query": "buy" 18 } 19 } 20 ], 21 "score": { 22 "function": { 23 "path": { 24 "value": "transactions.amount", 25 "undefined": 1.0 26 } 27 } 28 } 29 } 30 }, 31 "score": { 32 "embedded": { 33 "aggregate": "maximum", 34 "outerScore": { 35 "function": { 36 "multiply": [ 37 { 38 "log1p": { 39 "path": { 40 "value": "transaction_count" 41 } 42 } 43 }, 44 { 45 "score": "relevance" 46 } 47 ] 48 } 49 } 50 } 51 } 52 } 53 } 54 }, 55 { "$limit": 10 }, 56 { 57 "$project": { 58 "_id": 0, 59 "account_id": 1, 60 "transaction_count": 1, 61 "score": { $meta: "searchScore" } 62 } 63 })
MongoDB Search 对在上一时期进行多次交易并在单笔ACID 事务中购买大量 AMD 的帐户排名靠前。
1 [ 2 { account_id: 467651, transaction_count: 99, score: 19982 }, 3 { account_id: 271554, transaction_count: 96, score: 19851.822265625 }, 4 { account_id: 71148, transaction_count: 99, score: 19840 }, 5 { account_id: 408143, transaction_count: 100, score: 19836.76953125 }, 6 { account_id: 977774, transaction_count: 98, score: 19822.64453125 }, 7 { account_id: 187107, transaction_count: 96, score: 19754.470703125 }, 8 { account_id: 492843, transaction_count: 97, score: 19744.998046875 }, 9 { account_id: 373169, transaction_count: 93, score: 19553.697265625 }, 10 { account_id: 249078, transaction_count: 89, score: 19436.896484375 }, 11 { account_id: 77690, transaction_count: 90, score: 19418.017578125 } 12 ]
function
function 选项允许您使用数值字段更改文档的最终分数。您可以通过表达式指定用于计算最终分数的数字字段。如果函数得分的最终结果小于 0, MongoDB Search 会将得分替换为 0。
注意
您可以在 embeddedDocument 运算符的 operator 的 score 选项中使用 function。但是,对于需要 path 选项的函数分数表达式,可为表达式指定为 path 的数值字段必须位于 embeddedDocument 运算符的 path 内。
表达式
使用以下带有 function 选项的表达式来更改文档的最终分数:
算术表达式,用于将一系列数字相加或相乘。
常量表达式,支持在函数分数中使用常数。
高斯衰减表达式,通过以指定速率相乘来衰减或减少分数。
路径表达式,将索引数字字段值合并到函数分数中。
分数表达式,返回MongoDB Search 分配的相关性分数。
一元表达式,即采用单个参数的表达式。在MongoDB Search 中,您可以计算指定数字的日志10(x) 或日志10(x+1)。
注意
MongoDB搜索函数分数始终为 float 值,对于非常大或小的数字,精度可能会丢失。
算术表达式将一系列数字相加或相乘。例如,您可以使用算术表达式,通过数据扩充管道中的数字字段修改相关性排名。它必须包含以下选项之一:
注意
不能将计算结果为 undefined 的算术表达式替换为常量值。
常量表达式允许在函数得分中使用常量。 例如,您可以使用constant通过来自数据扩充管道的数值修改相关性排名。 它必须包含以下选项:
选项 | 类型 | 说明 |
|---|---|---|
| float | 表示固定值的数字。MongoDB Search 支持负值。 |
例子
{ "function": { "constant": -23.78 } }
高斯衰减表达式允许您根据数值字段值与指定原点的距离,通过相乘来衰减或减少文档的最终分数。 decay的计算公式为:

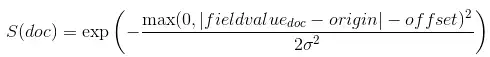
其中,计算 sigma 是为了确保分数在距离scale处取值decay origin±offset :

例如,您可以使用gauss根据文档新鲜度或影响较高排名的日期调整文档的相关分数。 gauss采用以下选项:
字段 | 类型 | 必要性 | 说明 |
|---|---|---|---|
| double | Optional | 您想要将分数相乘的比率。 值必须是介于 对于数字字段值(使用 |
| double | Optional | 用于确定距原点距离的数字。 仅对距离大于 |
| double | 必需 | 计算距离的原点。 |
| 必需 | 要使用其值来乘以基本分数的数字字段的名称。 | |
| double | 必需 | 与 |
例子
{ "function": { "gauss": { "path": { "value": "rating", "undefined": 50 }, "origin": 95, "scale": 5, "offset": 5, "decay": 0.5 } } }
假设最大评分为 100。MongoDB Search 使用文档中的 rating字段来衰减分数:
保留评分介于
90到100之间的文档的当前分数。对于评分低于 的文档,将当前分数乘以
0.590。对于评分低于
85的文档,将当前分数乘以0.25,依此类推。
路径表达式将索引数字字段值合并到函数分数中。它可以是 string 或 object。
如果 string,则该值是要搜索路径表达式的数值字段名称。
例子
{ "function": { "path": "rating" } }
MongoDB Search 将 rating字段的数值合并到文档的最终分数中。
如果 object,路径表达式将采用以下选项:
选项 | 类型 | 必要性 | 说明 |
|---|---|---|---|
| 字符串 | 必需 | 数值字段的名称。字段可以包含负数值。 |
| float | Optional | 如果文档中缺少使用 |
例子
{ "function": { "path": {"value": "quantity", "undefined": 2} } }
MongoDB Search 将 quantity字段或 2 的数值(如果文档中不存在 quantity字段)合并到文档的最终分数中。
分数表达式表示相关性分数,这是MongoDB Search 根据相关性为查询分配文档的分数。它与文档的当前分数相同。它必须包含以下选项:
选项 | 类型 | 说明 |
|---|---|---|
| 字符串 | 查询的相关性分数的值。值必须是 |
例子
{ "function": { "score": "relevance" } }
一元表达式是采用单个参数的表达式。在MongoDB Search 中,您可以使用一元表达式来计算指定数字的日志10(x) 或日志10(x+1)。示例,您可以使用 log1p 通过文档流行度分数影响相关性分数。它必须包含以下选项之一:
选项 | 类型 | 说明 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 计算一个数字以 10 为底的对数。例如: 一元表达式语法 在前面的示例中, MongoDB Search 计算算术表达式的日志10,该算术表达式使用 如果为 一元表达式语法 在前面的示例中, MongoDB Search 将常量表达式 | |||||||||||||||||||
| 将 一元表达式语法 在前面的示例中, MongoDB搜索将 |
示例
以下示例使用 sample_mflix.movies 集合上的默认索引来查询 title 字段。示例查询包括一个 $limit 阶段,用于将输出限制为 5 结果;以及一个 $project 阶段,用于排除除 title 和 score 之外的所有字段。
例子
在此示例中,文本操作符用 score 和 function 选项乘以下列值:
路径表达式的数值,即文档中
imdb.rating字段的值,如果imdb.rating字段不在文档中则为2相关性分数,或文档的当前分数
db.movies.aggregate([{ "$search": { "text": { "path": "title", "query": "men", "score": { "function":{ "multiply":[ { "path": { "value": "imdb.rating", "undefined": 2 } }, { "score": "relevance" } ] } } } } }, { $limit: 5 }, { $project: { "_id": 0, "title": 1, "score": { "$meta": "searchScore" } } }])
此查询返回以下结果,其中分数替换为指定的 function 值:
{ "title" : "Men...", "score" : 23.431293487548828 } { "title" : "12 Angry Men", "score" : 22.080968856811523 } { "title" : "X-Men", "score" : 21.34803581237793 } { "title" : "X-Men", "score" : 21.34803581237793 } { "title" : "Matchstick Men", "score" : 21.05954933166504 }
例子
在以下示例中,文本操作符使用带有function选项的score ,将文档的当前分数替换为常量数值3 。
db.movies.aggregate([ { "$search": { "text": { "path": "title", "query": "men", "score": { "function":{ "constant": 3 } } } } }, { $limit: 5 }, { $project: { "_id": 0, "title": 1, "score": { "$meta": "searchScore" } } } ])
此查询返回以下结果,其中分数替换为指定的 function 值:
{ "title" : "Men Without Women", "score" : 3 } { "title" : "One Hundred Men and a Girl", "score" : 3 } { "title" : "Of Mice and Men", "score" : 3 } { "title" : "All the King's Men", "score" : 3 } { "title" : "The Men", "score" : 3 }
例子
在以下示例中, 文本 操作符使用带有score function选项的 来衰减结果中文档的相关性分数。
该查询指定,对于 imdb.rating字段值或 4.6 的文档,如果文档中不存在 imdb.rating字段,则与 origin 的距离为 scale,即 5,即9.5,加上或减去 offset,即 0, MongoDB Search 必须使用 decay 乘以分数,该分数从 0.5 开始。此查询包括一个$limit 阶段,用于将输出限制为最多10 个结果;以及一个$project 阶段,用于在结果中添加imdb.rating 字段。
db.movies.aggregate([ { "$search": { "text": { "path": "title", "query": "shop", "score": { "function":{ "gauss": { "path": { "value": "imdb.rating", "undefined": 4.6 }, "origin": 9.5, "scale": 5, "offset": 0, "decay": 0.5 } } } } } }, { "$limit": 10 }, { "$project": { "_id": 0, "title": 1, "imdb.rating": 1, "score": { "$meta": "searchScore" } } } ])
此查询将返回以下结果:
[ { title: 'The Shop Around the Corner', imdb: { rating: 8.1 }, score: 0.9471074342727661 }, { title: 'Exit Through the Gift Shop', imdb: { rating: 8.1 }, score: 0.9471074342727661 }, { title: 'The Shop on Main Street', imdb: { rating: 8 }, score: 0.9395227432250977 }, { imdb: { rating: 7.4 }, title: 'Chop Shop', score: 0.8849083781242371 }, { title: 'Little Shop of Horrors', imdb: { rating: 6.9 }, score: 0.8290896415710449 }, { title: 'The Suicide Shop', imdb: { rating: 6.1 }, score: 0.7257778644561768 }, { imdb: { rating: 5.6 }, title: 'A Woman, a Gun and a Noodle Shop', score: 0.6559237241744995 }, { title: 'Beauty Shop', imdb: { rating: 5.4 }, score: 0.6274620294570923 } ]
要将上一个查询中使用的高斯表达式的结果与MongoDB Search 结果中返回的相关性分数进行比较,运行以下查询:
db.movies.aggregate([ { "$search": { "text": { "path": "title", "query": "shop" } } }, { "$limit": 10 }, { "$project": { "_id": 0, "title": 1, "imdb.rating": 1, "score": { "$meta": "searchScore" } } } ])
此查询将返回以下结果:
[ { title: 'Beauty Shop', imdb: { rating: 5.4 }, score: 4.111973762512207 }, { imdb: { rating: 7.4 }, title: 'Chop Shop', score: 4.111973762512207 }, { title: 'The Suicide Shop', imdb: { rating: 6.1 }, score: 3.5363259315490723 }, { title: 'Little Shop of Horrors', imdb: { rating: 6.9 }, score: 3.1020588874816895 }, { title: 'The Shop Around the Corner', imdb: { rating: 8.1 }, score: 2.762784481048584 }, { title: 'The Shop on Main Street', imdb: { rating: 8 }, score: 2.762784481048584 }, { title: 'Exit Through the Gift Shop', imdb: { rating: 8.1 }, score: 2.762784481048584 }, { imdb: { rating: 5.6 }, title: 'A Woman, a Gun and a Noodle Shop', score: 2.0802340507507324 } ]
例子
在下面的示例中,text 操作符使用 score和 function 选项,将查询的相关性得分替换为数字字段 imdb.rating, 如果文档中没有 imdb.rating 字段的话,则替换 4.6 的值。
db.movies.aggregate([{ "$search": { "text": { "path": "title", "query": "men", "score": { "function":{ "path": { "value": "imdb.rating", "undefined": 4.6 } } } } } }, { $limit: 5 }, { $project: { "_id": 0, "title": 1, "score": { "$meta": "searchScore" } } }])
此查询返回以下结果,其中分数替换为指定的 function 值:
{ "title" : "12 Angry Men", "score" : 8.899999618530273 } { "title" : "The Men Who Built America", "score" : 8.600000381469727 } { "title" : "No Country for Old Men", "score" : 8.100000381469727 } { "title" : "X-Men: Days of Future Past", "score" : 8.100000381469727 } { "title" : "The Best of Men", "score" : 8.100000381469727 }
例子
在以下示例中,文本操作符使用 score 和 function选项来返回文档的相关性分数,该分数与当前分数相同)。
db.movies.aggregate([{ "$search": { "text": { "path": "title", "query": "men", "score": { "function":{ "score": "relevance" } } } } }, { "$limit": 5 }, { "$project": { "_id": 0, "title": 1, "score": { "$meta": "searchScore" } } }])
此查询返回以下结果,其中分数替换为指定的 function 值:
{ "title" : "Men...", "score" : 3.4457783699035645 } { "title" : "The Men", "score" : 2.8848698139190674 } { "title" : "Simple Men", "score" : 2.8848698139190674 } { "title" : "X-Men", "score" : 2.8848698139190674 } { "title" : "Mystery Men", "score" : 2.8848698139190674 }
例子
在以下示例中,text 操作符使用 score 和 function 选项来计算 imdb.rating 字段的对数10;如果文档中不存在 imdb.rating 字段,则计算 10 的对数。
db.movies.aggregate([{ "$search": { "text": { "path": "title", "query": "men", "score": { "function": { "log": { "path": { "value": "imdb.rating", "undefined": 10 } } } } } } }, { "$limit": 5 }, { "$project": { "_id": 0, "title": 1, "score": { "$meta": "searchScore" } } }])
此查询返回以下结果,其中分数替换为指定的 function 值:
{ "title" : "12 Angry Men", "score" : 0.9493899941444397 } { "title" : "The Men Who Built America", "score" : 0.9344984292984009 } { "title" : "No Country for Old Men", "score" : 0.9084849953651428 } { "title" : "X-Men: Days of Future Past", "score" : 0.9084849953651428 } { "title" : "The Best of Men", "score" : 0.9084849953651428 }