本节包含以下页面,其中提供了有关MongoDB Vector Search 性能基准测试以及如何使用它来测试、评估和改进自己的向量搜索性能的信息:
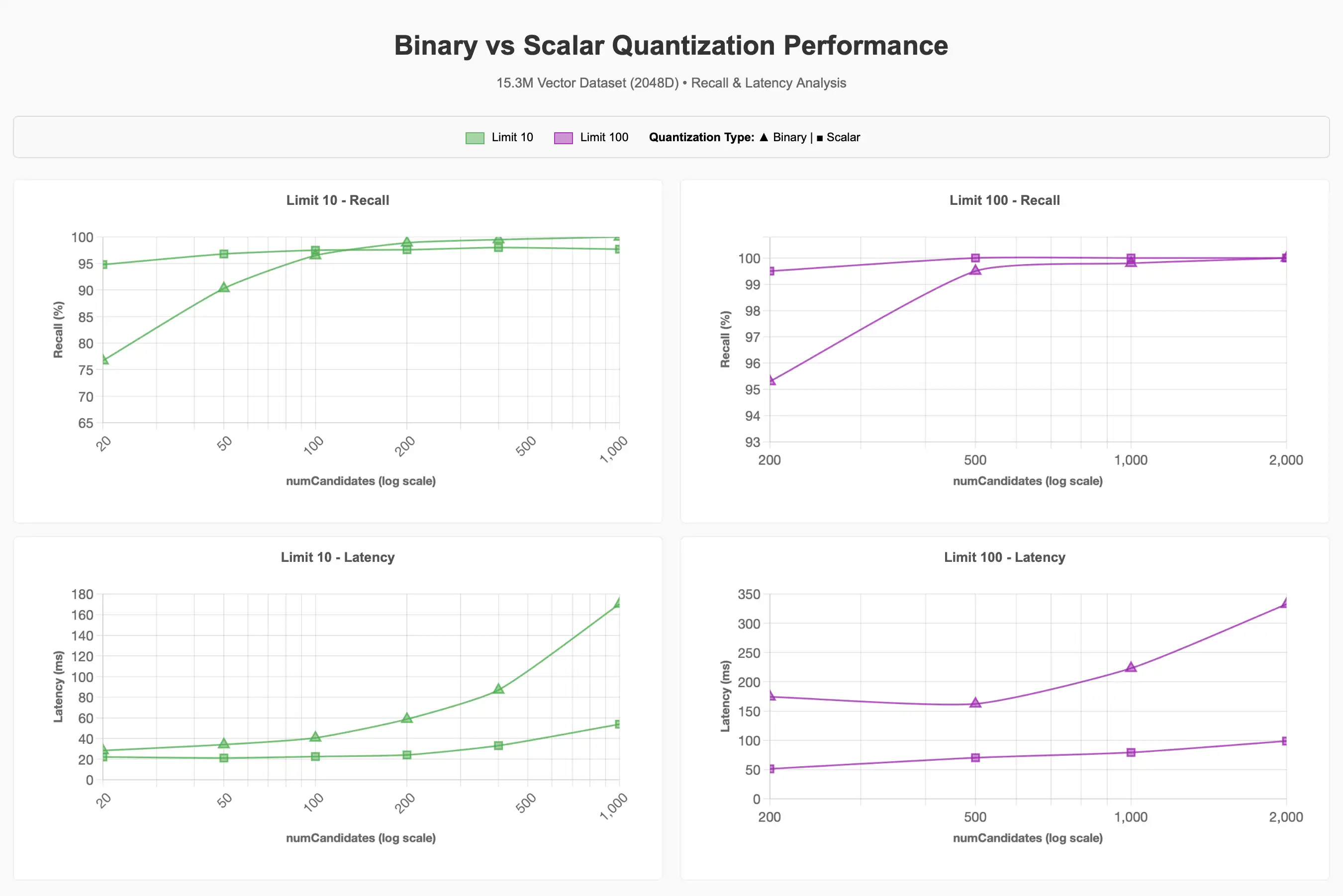
要查看完整图表,请参阅 Claude artifact。
如何使用此基准
这些页面的主节点 (primary node in the replica set)目标是在评估MongoDB Vector Search 的性能时,显着减少首次扩展向量测试(> 10 M 个向量)的摩擦。
这些页面提供了一组初始配置(嵌入模型维度、量化制度、numCandidates选择、过滤器条件、搜索节点配置),您可以使用它们自信地运行测试。您可能需要根据与使用案例相关的数据集和查询模式修改配置,因为这只是一个起点。
阅读建议
在阅读这些页面时,我们建议您重点关注与使用案例最相关的主要问题。我们提供以下主要关注点的指导:召回率、费用和延迟/吞吐量。
使用最适合使用案例的指导:
变更日志
Date | 说明 |
|---|---|
2025-07-21 | 发布基准测试指南和结果,展示MongoDB Vector Search 如何在 5.5M 上扩展在各种条件下使用 Voyage AI 的 |