您可以在图表中对数据进行分箱、排序和限制,以突出数据的关键方面。
分箱数据
Atlas Charts 支持对数据中的日期、数字和字符串字段进行分箱。分箱将连续数据拆分为称为箱 的离散组中,每个箱包含原始值的连续子集。例如,您可以按出生年代(十年)将用户划分到不同的箱,或者按开始日期月份对具有时间戳的日历事件进行分组。
例子
连续数据与离散数据
连续数据可以占用连续范围内的任何值。连续数据的一些示例包括某人的身高、体温或出生时间。
另外,离散数据是指只能取特定值、被分类的数据。离散数据的示例包括眼睛颜色和班级学生人数。
在处理日期时,该数据通常以连续形式出现。将该数据拆分为特定的时间窗口可能是非常有用的,这有助于发现更多的趋势和模式。Atlas Charts 支持以下日期分箱:
|
|
要对日期使用分箱:
将日期字段(在图表生成器的 Fields部分中以日历图标表示)拖动到category 编码渠道。
默认情况下,按 Binning On 切换指示启用分箱
使用下拉菜单选择日期的分箱大小。
根据需要切换 Periodic 设置。
如果启用,Atlas Charts 创建相对于下一个最高时间段的分箱,并重复每个分箱以涵盖数据字段所跨的时间范围。
如果禁用,则 Charts 创建的分箱不会重复。
例子
考虑一个包含 5 年数据的日期字段,分箱选择为 Month。如果禁用 Periodic,则 Charts 会将数据集中的 60 个月添加到可视化。
或者,如果启用 Periodic,则 Charts 将仅绘制 12 个日历月,并可视化每个日历月的总聚合结果。
注意
选择 Day of the Week 的分箱大小时,Periodic 设置始终处于启用状态。
选择大小为 Year 的分箱时,Periodic 设置始终处于禁用状态,因为“年”是 Charts 中可选的最大时间段。
要禁用分箱,请将 Binning 设置切换为关闭。在这种情况下,字段中的每个日期都会添加到可视化,而不执行分组。
例子
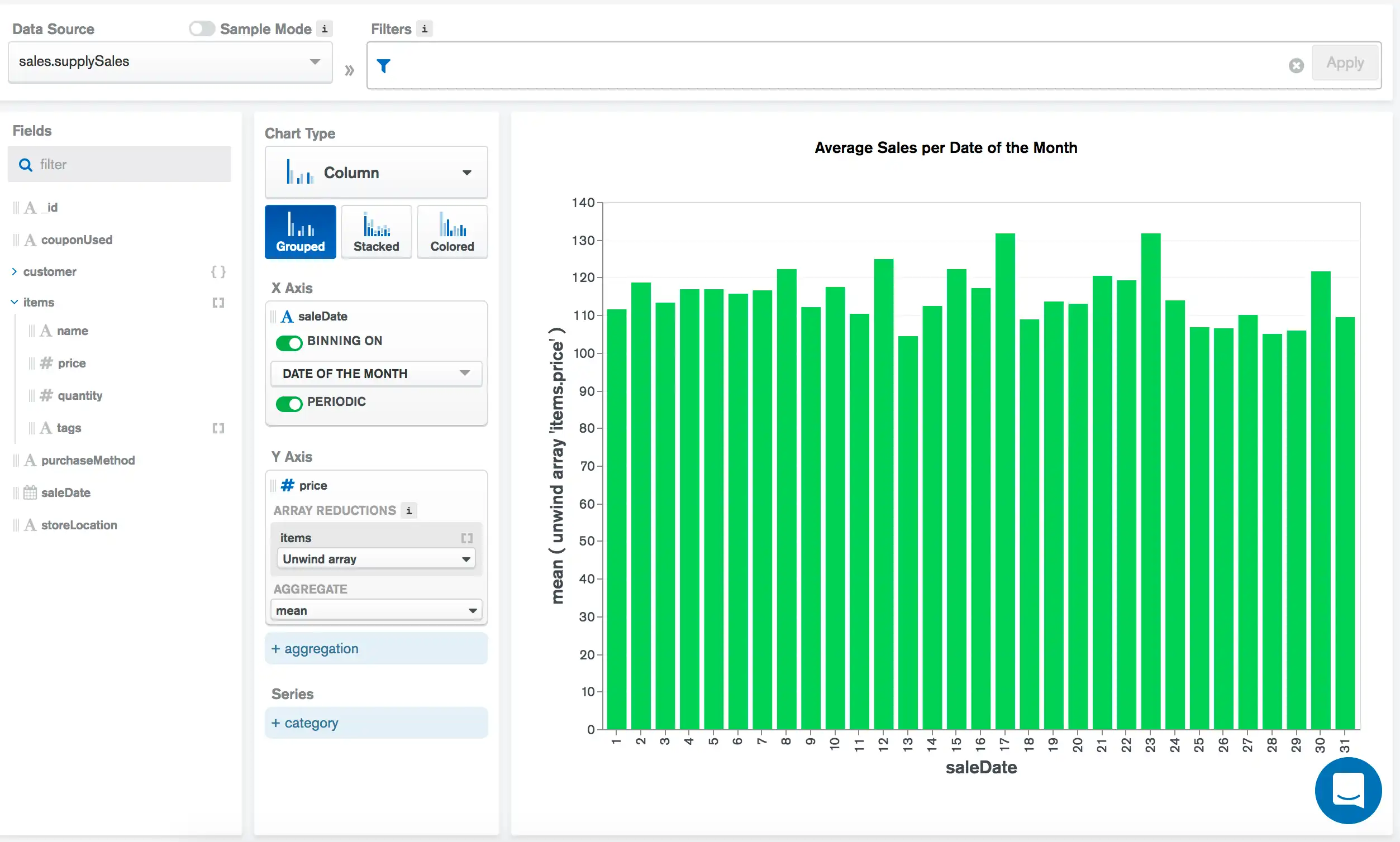
下图表是对一家办公用品存储历史销售数据的可视化呈现。 每笔销售都由 supplySales集合中的一份文档表示。 集合中的每个文档都包含以salesDate形式记录的销售日期以及以items大量形式记录的销售商品列表。
saleDate字段包含连续时间戳数据。 该字段按启用了Periodic设置的Date of the Month进行分箱。 这意味着,在数据跨越的几年内, Atlas Charts绘制了每月每个单独日期的mean销售值:

比较时段
使用分箱日期数据时,您可以选择比较不同时间段的数据。您可以显示累计总数或数值变化。
要使用比较周期功能,图表必须具备:
如果满足条件,聚合卡上会出现标有 Compare Periods 的开关按钮。开启后,会出现一个包含 Cumulative Total 和 Change in Value 选项的下拉菜单。
在 Cumulative Total 图表上,每个连续数据点的计算方法均是将自己的值与前一个按时间顺序排列的数据点相加。您还可以指定基线值作为累计总数的初始值。默认基线值为 0。
在 Change in Value 图表上,每个连续的数据点显示其与前一个按时间顺序出现的数据点之间的差异。图表中的第一个数据点将始终为空,因为没有可以比较的上一个周期。
以下类型的图表可以使用时间段比较功能:
注意
累计数据选项不适用于多序列图表。
例子
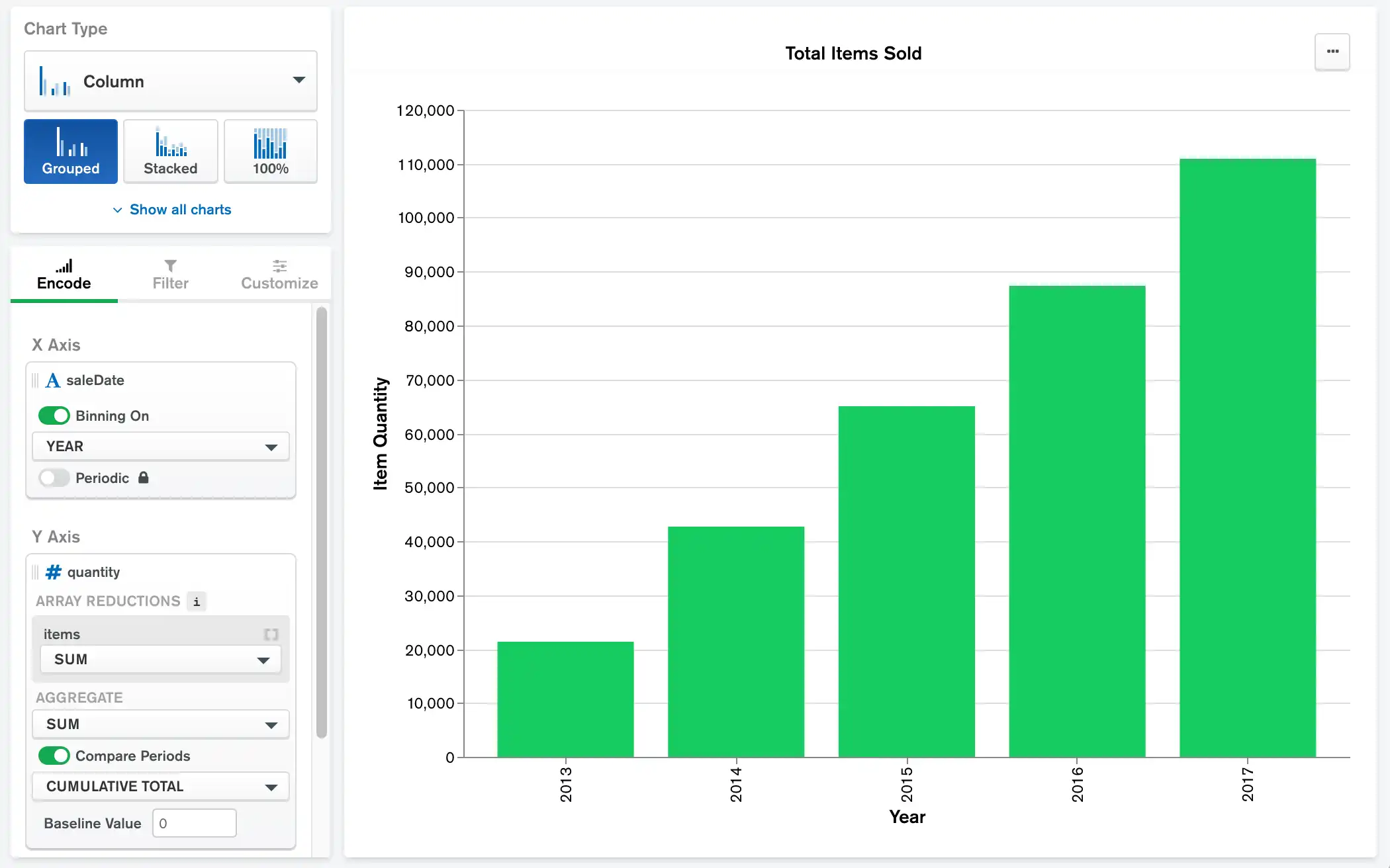
以下柱形图显示某办公用品商店五年来的累计年销售额。集合中的每份文档都包含销售日期 salesDate 以及包含销售商品数量的 quantity 字段。
saleDate 字段按年进行分箱。items 字段是一个数组,其中每个项目都有一个 quantity 字段,该字段通过 SUM 聚合操作添加到累积总数。

空分箱
启用分箱后,Charts 将显示图表显示的最小和最大数据范围内的空分箱条目。
注意
例外
如果涵盖空分箱会导致图表中的唯一分箱超过 5000 个,则 Charts 不会显示空分箱。
Charts 用于空分箱的值取决于您选择的聚合函数:
聚合功能 | 推断值 |
|---|---|
|
|
所有其他功能 |
|
Charts 根据图表类型以不同方式显示带有 null 值的分箱:
Atlas Charts可以将连续设立的数字字段分箱为指定大小的组。
要对数值字段使用分箱,请执行以下操作:
将数字字段(由图表生成器的Fields部分中的数字符号图标表示)拖动到category编码渠道。
默认,分箱功能处于启用状态,如切换Binning On所示。
在Bin Size输入框中输入所需的分箱大小。
要禁用分箱,请将Binning设置切换为关闭。 在这种情况下,字段中的每个单独值都会添加到可视化效果中,而不是分组到 bin 中。
例子
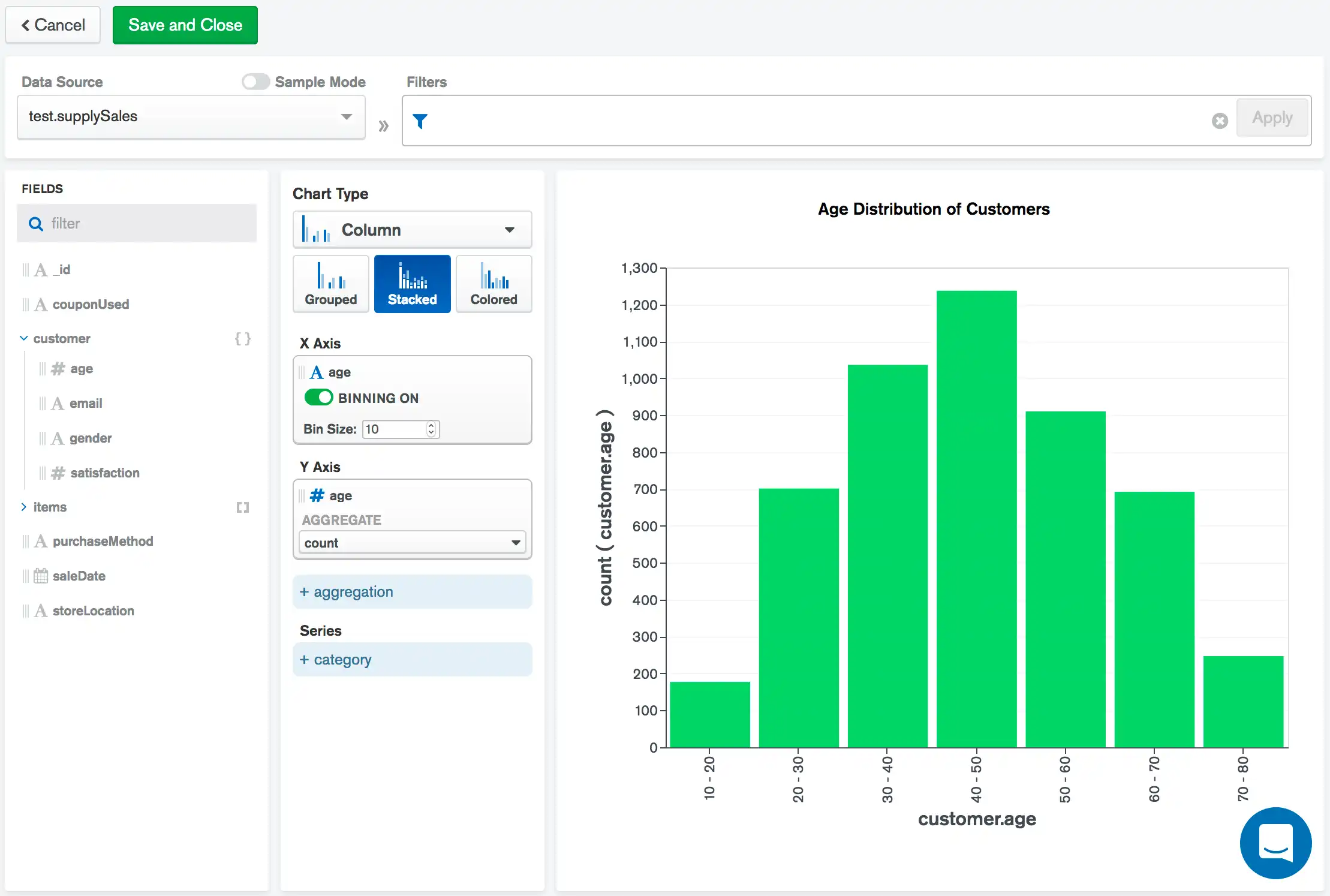
下图表是对一家办公用品存储历史销售数据的可视化呈现。 每笔销售都由supplySales集合中的一份文档表示。 每个销售文档都包含一个customer对象,其中包含有关购买商品的客户的信息。
下图表将分箱应用于customer.age字段。 age字段包含连续数值数据,并按十进制进行分箱。 每个age值都被放入相应的分箱中, Charts会计算每个分箱中的年龄数量,从而提供存储客户年龄分布的高级概览。

空分箱
启用分箱后,Charts 将显示图表显示的最小和最大数据范围内的空分箱条目。
注意
例外
如果涵盖空分箱会导致图表中的唯一分箱超过 5000 个,则 Charts 不会显示空分箱。
Charts 用于空分箱的值取决于您选择的聚合函数:
聚合功能 | 推断值 |
|---|---|
|
|
所有其他功能 |
|
Charts 根据图表类型以不同方式显示带有 null 值的分箱:
您可以选择string类别并对其进行分箱,以便更加灵活地对图表中的数据进行分组。 向分箱添加类别时, Atlas Charts会聚合每个选定类别的数据以呈现该分箱的数据。
用例
通过将选定的类别字符串分箱在一起,您可以将具有共同主题的项目群组,而无需更改根本的数据。 您可以将大量设立值合并为更小、更易于管理的值设立。
考虑:
一个数据集,其中包含与世界各地国家/地区有关的信息,并且您希望按大洲对国家/地区进行群组。
历史上各种艺术家的数据集,您想按艺术时期(示例,文艺复兴时期、浪漫主义、现代)对这些艺术家进行群组。
包含细粒度版本号的数据集(例如
2.3.0、2.3.1、2.3.2-rc1、2.4.0),您想要在较粗粒度的群组中进行分析(例如2.3、2.4)。
从string值创建分箱
将string字段拖动到 Category 编码渠道。
将字段的Binning切换为On 。
单击 Add Bin(连接)。
在Add Bin窗口中,为 bin 命名。
点,您可以从类别字符串列表中创建分箱,也可以定义正则表达式来匹配string值。 如果要为每个分箱选择精确的值,可以使用类别字符串列表。 如果要对更大范围的潜在值进行模式匹配,则正则表达式是更好的选择。
要从选定的类别字符串创建分箱,请执行以下操作:
单击Select单选按钮。
选择要包含在分箱中的类别。
单击Save 。 Bins窗口显示您创建的分箱以及每个分箱属于多少个类别。
注意
每个值只能添加到一个分箱中。 任何已添加到其他分箱的值都会显示为已禁用,并附加其已添加到的分箱的名称。
复选框和值列表来自数据示例,可能不包括数据中存在的每个值。 您可以手动将其他值添加到列表中。
要从正则表达式创建分箱:
单击Regex单选按钮。
在Insert regex文本框中输入正则表达式。
从文本框右侧的下拉菜单中选择任何所需的标志。 您可以使用四个可用标志的任意组合:
标记说明i不区分大小写的搜索
m多行模式
x扩展模式
s单行模式
此时将显示匹配文档的示例。 如果没有匹配的文档,您仍然可以保存 bin。
单击Save 。 Bins窗口会显示您创建的分箱。 从正则表达式创建的分箱用.*图标表示。
您可以通过单击Add Bin 链接添加另一个垃圾箱,也可以通过单击右上角的Bins 关闭X 窗口。
编辑和删除现有分箱
要编辑现有类别箱,请单击Binning切换开关旁边的Edit按钮。 出现Bins窗口。 每个分箱旁边的标记显示该分箱属于多少个类别。

要编辑分箱,请单击Pencil Icon 。 您可以重命名该分箱并更改属于该分箱的类别。
要删除分箱,请单击Trash图标。
示例
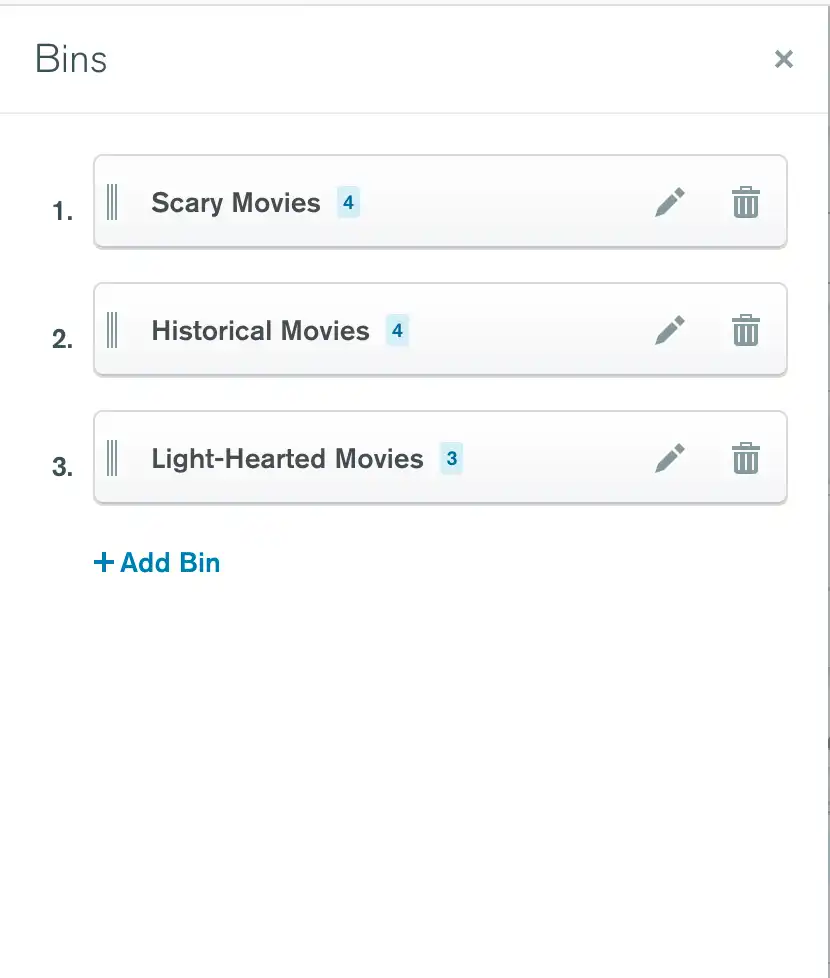
下图表将电影样本数据中的类型分组到更广泛的分箱中:
Historical Movies,其中包括纪录片、传记、历史和战争类型。
Light-Hearted Movies,其中包括喜剧、爱情和家庭等类型。
Scary Movies,其中包括剧情片、惊悚片、恐怖片和悬疑片等类型。
未包含在这些分箱中的类型的电影将分组到Other Values分箱中。
该图表显示了属于每个分箱的电影的平均值imdb.rating评分。 该图表按类别名称的字母顺序排序。

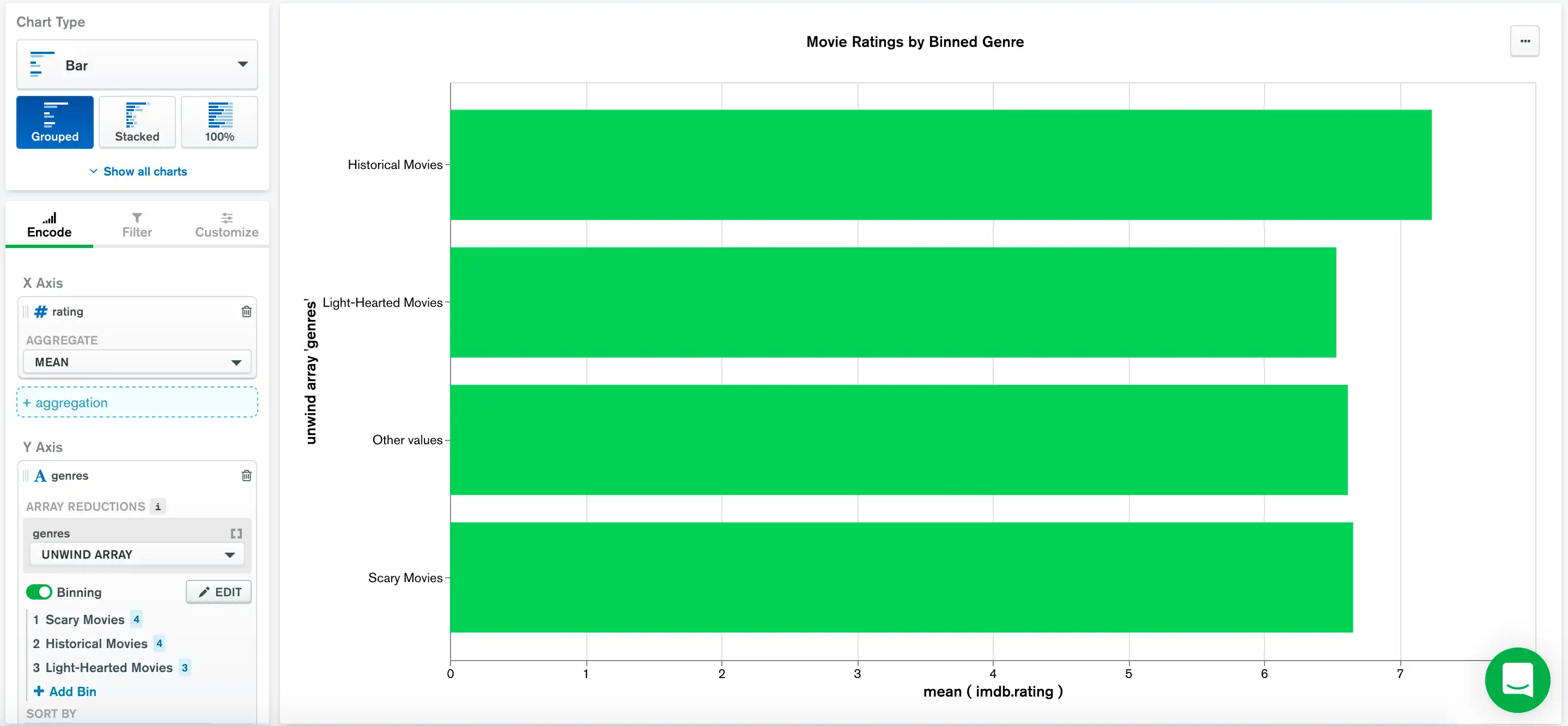
下图表是在sample_airbnb.listingsAndReviews集合的description字段中查找某些词语,并比较平均值价格。 它根据 description字段是否包含与正则表达式指定的模式匹配的string ,使用 bin 对文档进行群组。

行为
值只能属于一个类别 bin,但可以属于任意数量的 regex bin。
图表上显示的任何尚未添加到任何分箱的值都会自动添加到名为Other Values的默认分箱中。
bin 在Bins窗口中出现的顺序很重要。 每个值都作为其出现的最高排名分箱的一部分呈现在图表中。
注意
您可以通过将分箱拖放到Bins窗口中来对分箱重新排序。
Sort Data
使用图表构建器中的 Sort By 下拉菜单,按以下任一方式对图表数据进行排序:
category
值
系列字段(用于多系列图表)
如果按 Value(值)对多序列图表进行一般排序而不是按特定序列排序,Atlas Charts 根据序列中的所有值的总和对数据排序。
要在升序或降序排序顺序之间切换,请单击 Sort By 下拉列表右侧的 a-z 按钮。
默认情况下,Charts 根据 Value 以降序排列数据。
按系列值对多系列图表排序
如果使用每个系列的不同字段创建多系列图表,则可以按特定系列字段对图表进行排序。
例子
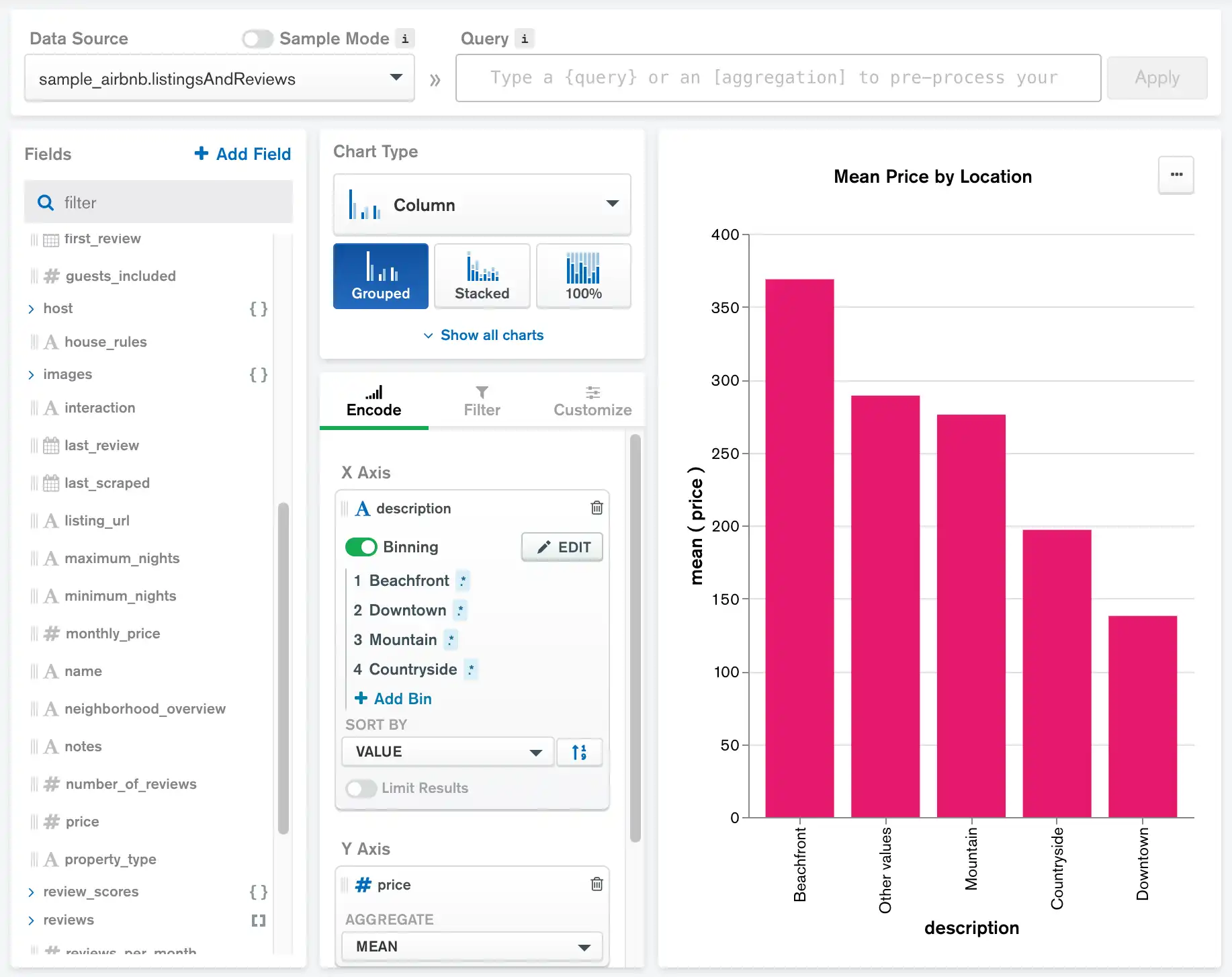
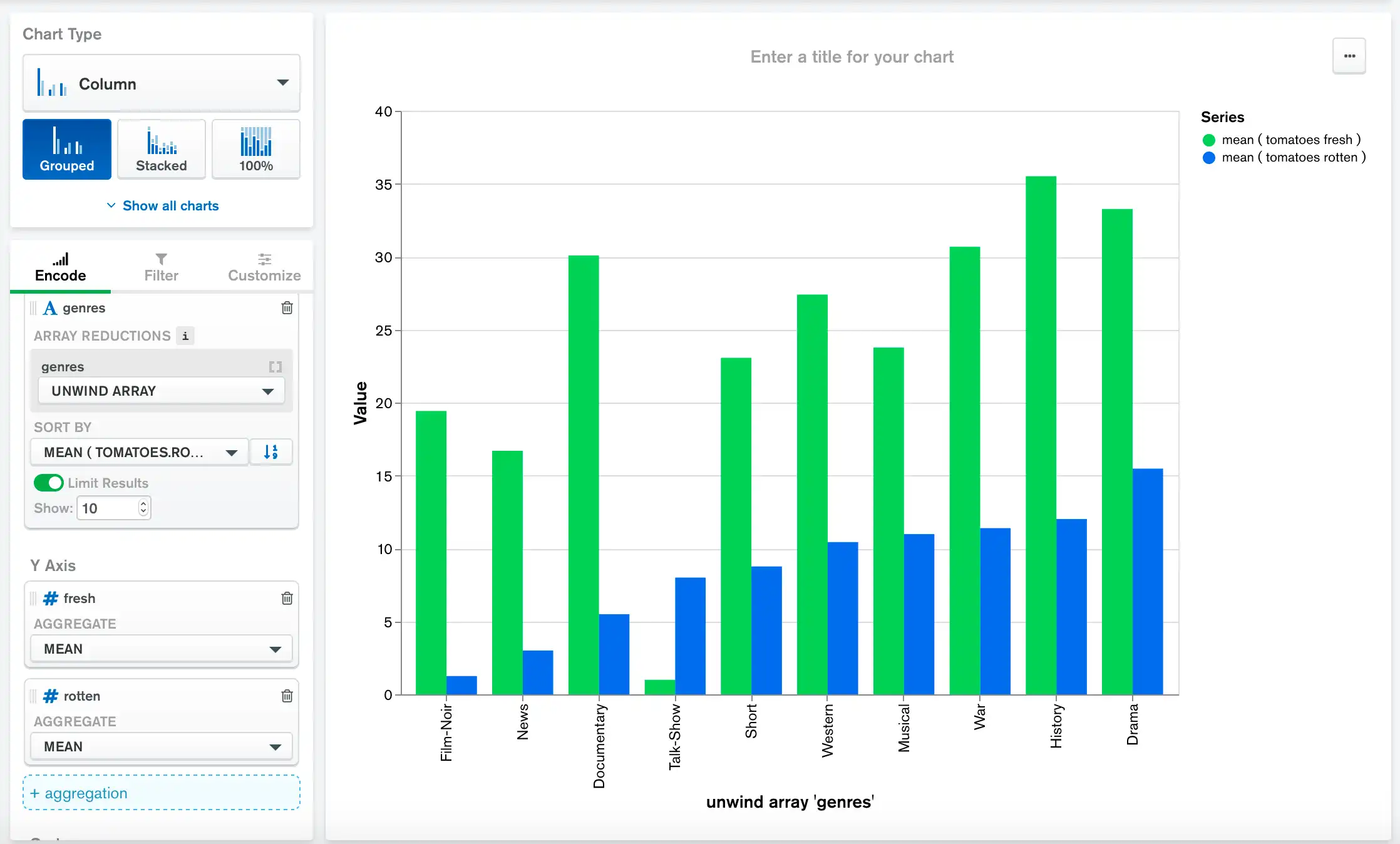
以下图表使用示例数据:电影数据源来比较每种类型电影的 fresh 和 rotten 烂番茄评分的平均值。
此图表按平均 fresh 值按降序排序:

此图表按平均 rotten(烂番茄)评分的升序顺序排序:

Limit Data
您可以对 Category 编码通道应用一个限值,以便只在可视化中包含指定数量的类别。包含的类别是第一批与指定排序顺序相匹配的类别。限制数据在待可视化数据类别多到难以创建有意义的图表时非常有用。
当您限制数据时,还可以额外启用 Show "All Others"(显示所有其他),创建名为“All others”(所有其他)的新类别,该类别可以将您的限制所忽略的类别值合并起来。
例子
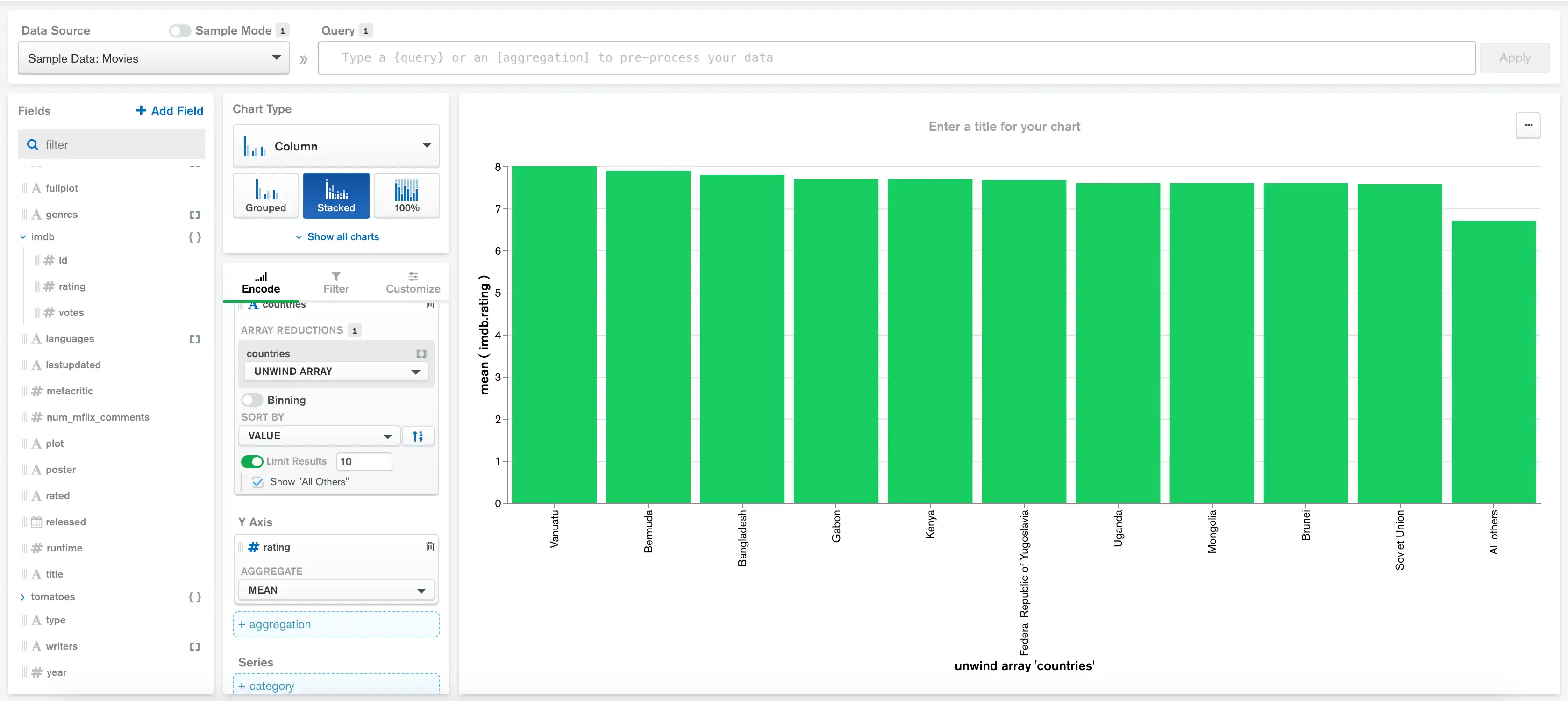
下图表显示了特定国家/地区电影的平均 IMDb 评分:

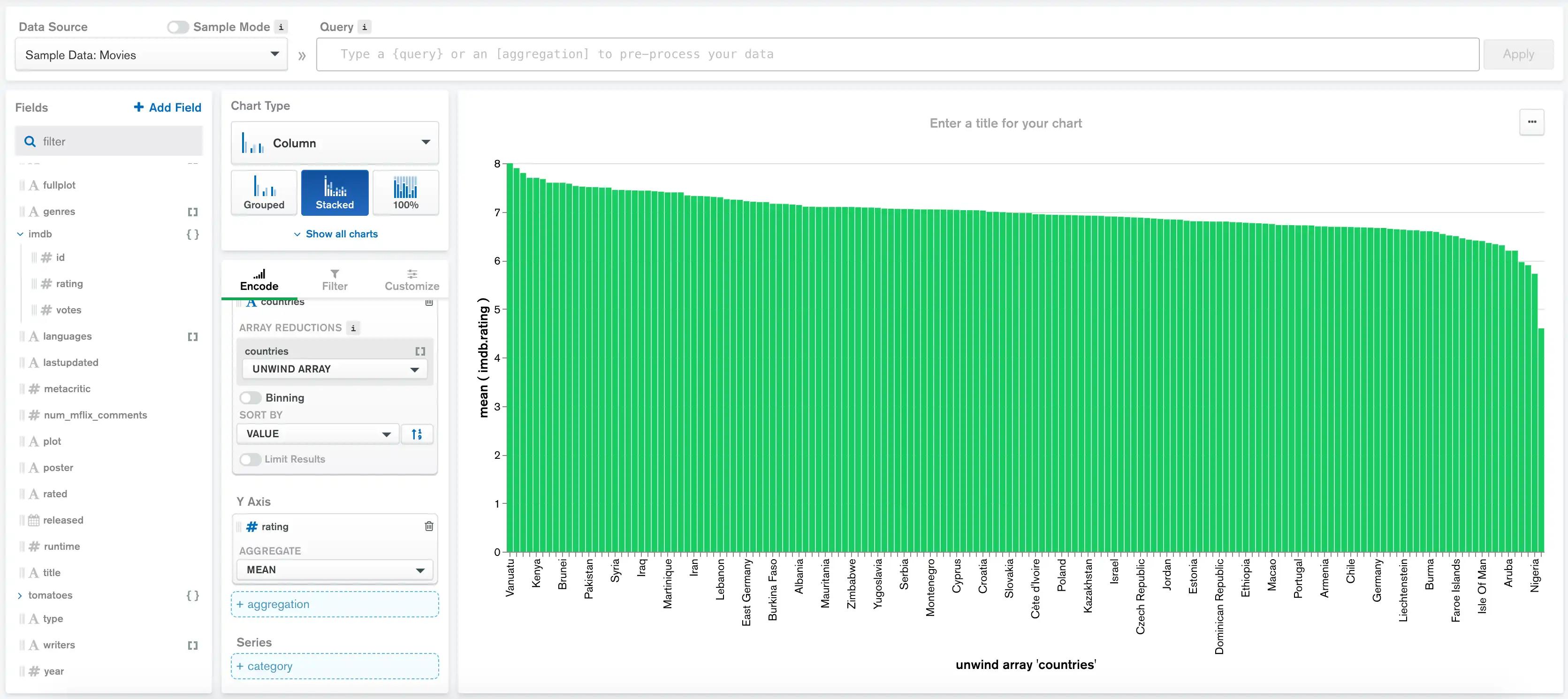
数据集包含许多不同国家/地区的电影,但最有意思的是了解哪些国家/地区制作的电影收视率最高。我们可以限制只显示电影平均收视率最高的 10 个国家/地区来实现这一目标。
将 Limit Results 切换至 On,Show 输入保持默认值 10。
勾选 Show "All Others"(显示所有其他)以创建第 11 列,表示未进入前 10 名的国家/地区的电影平均评分。
这个图表现在更容易理解了,我们可以清楚地看到电影收视率最高的国家/地区: