Overview
在本指南中,您可以学习如何使用GridFS在MongoDB中存储和检索大文件。GridFS是由Java驱动程序实现的规范,描述了如何在存储文件时将文件分割为数据块,并在检索文件时重新组合文件。GridFS 的驱动程序实现是一个抽象,用于管理 Java 应用程序中文件存储的操作和组织。
如果文件大小超过 16MB 的BSON文档大小限制,请使用GridFS 。要详细学习;了解GridFS是否适合您的使用案例,请参阅MongoDB Server手册中的 GridFS参考。
以下部分描述了GridFS操作并演示了如何使用驱动程序执行这些操作:
提示
超时设置
您可以使用客户端操作超时 (CSOT) 设置来限制服务器完成GridFS操作的时间。要学习;了解有关将此设置与GridFS结合使用的更多信息,请参阅《限制服务器执行时间》指南中的 GridFS部分。
GridFS 的工作原理
GridFS 在存储桶中组织文件,存储桶是一组包含文件数据段及其描述信息的MongoDB 集合。存储桶包含以下集合,使用 GridFS 规范中定义的约定命名:
chunks集合存储二进制文件数据段。files集合存储文件元数据。
当您创建新的GridFS存储桶时,驱动程序会创建前面的集合,并以默认桶名称 fs 作为前缀,除非您指定其他名称。该驱动程序还会在每个集合上创建一个索引,以确保有效检索文件和相关元数据。如果GridFS存储桶尚不存在,则驱动程序仅在第一次写入操作时创建该存储桶。仅当索引不存在且存储桶为空时,驱动程序才会创建索引。有关GridFS索引的更多信息,请参阅有关GridFS索引的服务器手册页面。
使用 GridFS 存储文件时,驱动程序会将文件拆分成较小的数据段,每个数据段由 chunks 集合中的单独文档表示。它还在 files 集合中创建文档,其中包含文件 ID、文件名和其他文件元数据。您可以从内存或数据流上传文件。请参阅下图,了解 GridFS 在上传到存储桶时如何拆分文件。

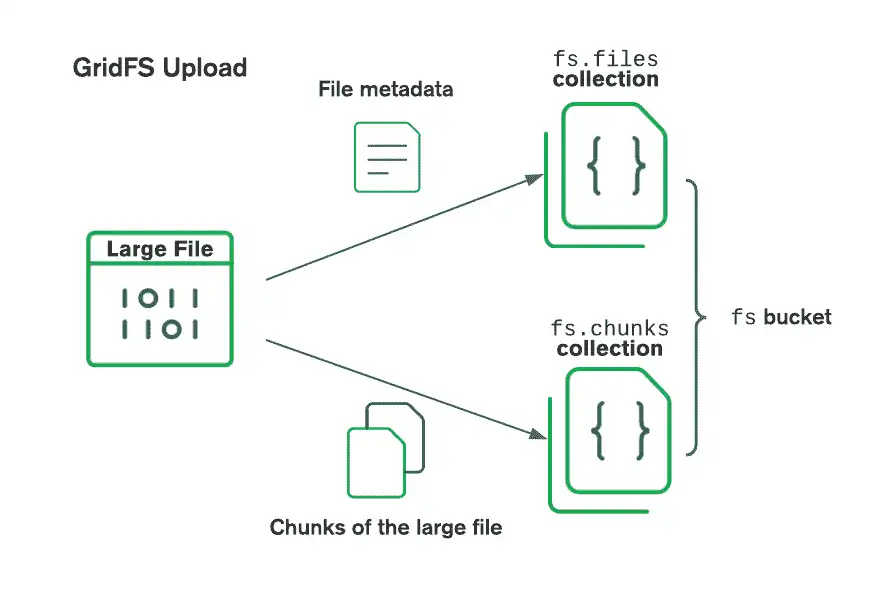
在检索文件时,GridFS 从指定存储桶上的 files 集合中获取元数据,并使用该信息通过 chunks 集合中的文档重建文件。您可以将文件读取到内存中,或者将其输出到流。
创建 GridFS 存储桶
若要从 GridFS 存储或检索文件,请创建存储桶或获取对 MongoDB 数据库上现有存储桶的引用。将 MongoDatabase 实例作为参数来调用 GridFSBuckets.create() 辅助方法来实例化 GridFSBucket。您可以使用 GridFSBucket 实例对存储桶中的文件调用读取和写入操作。
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database);
要使用默认名称 fs 之外的自定义名称来创建或引用存储桶,请将存储桶名称作为第二个参数传递给 create() 方法,如下所示:
GridFSBucket gridFSBucket = GridFSBuckets.create(database, "myCustomBucket");
注意
调用 create() 时,如果不存在存储桶,MongoDB 也不会创建。但在您上传第一个文件时,MongoDB 会根据需要创建存储桶。
有关本节中提到的类和方法的更多信息,请参阅以下 API 文档:
存储文件
要将文件存储在 GridFS 存储桶中,您可以从 InputStream 的实例上传该文件,也可以将其数据写入 GridFSUploadStream。
对于任意上传进程,您都可以指定配置信息,如文件数据段大小和其他作为元数据存储的字段/值对。如以下代码片段所示,在 GridFSUploadOptions 的实例中设置此信息:
GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) // 1MB chunk size .metadata(new Document("myField", "myValue"));
有关详情,请参阅 GridFSUploadOptions API 文档。
重要
使用 MAJORITY 写关注
使用输入流上传文件
本部分向您展示了如何使用输入流将文件上传到 GridFS 存储桶。以下代码示例显示了如何使用 FileInputStream 从文件系统中的文件读取数据并通过执行以下操作将其上传到 GridFS:
使用
FileInputStream从文件系统中读取。使用
GridFSUploadOptions设置数据段大小。将名为
type的自定义元数据字段设置为值“zip archive”。上传名为
project.zip的文件,指定 GridFS 文件名为“myProject.zip”。
String filePath = "/path/to/project.zip"; try (InputStream streamToUploadFrom = new FileInputStream(filePath) ) { // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); // Uploads a file from an input stream to the GridFS bucket ObjectId fileId = gridFSBucket.uploadFromStream("myProject.zip", streamToUploadFrom, options); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + fileId.toHexString()); }
此代码示例将在上传文件成功保存到 GridFS 后,打印该文件的 ID。
有关更多信息,请参阅有关uploadFromStream()的API文档。
使用输出流上传文件
本部分向您展示如何通过写入输出流的方式将文件上传到 GridFS 存储桶。以下代码示例展示如何通过执行以下操作写入 GridFSUploadStream, 将数据发送到 GridFS:
将文件系统中名为“project.zip”的文件读取到字节数组中。
使用
GridFSUploadOptions设置数据段大小。将名为
type的自定义元数据字段设置为值“zip archive”。将字节写入
GridFSUploadStream,指定文件名为“myProject.zip”。数据流将数据读入缓冲区,直到达到chunkSize设置所指定的限制,然后将数据作为新的数据段插入chunks集合。
Path filePath = Paths.get("/path/to/project.zip"); byte[] data = Files.readAllBytes(filePath); // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); try (GridFSUploadStream uploadStream = gridFSBucket.openUploadStream("myProject.zip", options)) { // Writes file data to the GridFS upload stream uploadStream.write(data); uploadStream.flush(); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + uploadStream.getObjectId().toHexString()); // Prints a message if any exceptions occur during the upload process } catch (Exception e) { System.err.println("The file upload failed: " + e); }
此代码示例将在上传文件成功保存到 GridFS 后,打印该文件的 ID。
注意
如果文件上传不成功,则操作会抛出异常,任何上传的数据段都会成为孤立的数据段。孤立的数据段是 GridFS chunks 集合的文档,不引用 GridFS files 集合的任何文件 ID。当上传或删除操作中断时,文件数据段可能成为孤立的数据段。要删除孤立的数据段,您必须通过读操作识别并通过写操作删除该数据段。
有关更多信息,请参阅有关GridFSUploadStream的API文档。
检索文件信息
在本部分中,您可以了解如何检索存储在 GridFS 存储桶的 files 集合的文件元数据。元数据包含所引用文件的相关信息,包括:
此文件的 ID
文件的名称
文件的长度/大小
上传日期和时间
您可以在其中存储任何其他信息的
metadata文档
要从 GridFS 存储桶检索文件,请对 GridFSBucket 实例调用 find() 方法。该方法会返回一个 GridFSFindIterable,而您可通过它来访问结果。
以下代码示例向你展示如何从 GridFS 存储桶中的所有文件中检索和打印文件元数据。您可以通过多种方式遍历从 GridFSFindIterable 检索到的结果,该示例使用 Consumer 函数接口来打印以下结果:
gridFSBucket.find().forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
下一个代码示例向您展示如何检索和打印与查询筛选器所指定字段匹配的所有文件的文件名。示例还对返回的 GridFSFindIterable 调用 sort() 和 limit(),以指定结果的顺序和最大数量:
Bson query = Filters.eq("metadata.type", "zip archive"); Bson sort = Sorts.ascending("filename"); // Retrieves 5 documents in the bucket that match the filter and prints metadata gridFSBucket.find(query) .sort(sort) .limit(5) .forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
由于 metadata 是嵌入式文档,查询筛选条件使用点表示法指定文档中的 type 字段。有关详情,请参阅服务器手册指南,了解如何查询嵌入/嵌套文档。
有关本节中提到的类和方法的更多信息,请参阅以下资源:
GridFSFindIterable API 文档
GridFSBucket.find() API 文档
下载文件
您可以直接从 GridFS 下载文件到数据流,也可以从数据流将文件保存到内存。您可以通过文件 ID 或文件名指定要检索的文件。
文件修订
当存储桶包含多个共享相同文件名的文件时,GridFS 默认选择最新上传文件的版本。为了区分共享相同名称的文件,GridFS 为这些共享相同文件名的文件分配修订版本号,按上传时间排序。
原始文件修订号为“0”,下一个最新的文件修订号为“1”。您还可以指定与修订的新近度相对应的负值。修订值“-1”引用最新修订版,“-2”引用下一个最新修订版。
以下代码段展示了如何在 GridFSDownloadOptions 的实例中指定某一文件的第二项修订:
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(1);
有关枚举修订的更多信息,请参阅GridFSDownloadOptions的API文档。
将文件下载到输出流
您可以将 GridFS 存储桶中的文件下载到输出流。以下代码示例向您展示如何调用 downloadToStream() 方法,将名为“myProject.zip”的文件的第一个修订版本下载到 OutputStream。
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(0); // Downloads a file to an output stream try (FileOutputStream streamToDownloadTo = new FileOutputStream("/tmp/myProject.zip")) { gridFSBucket.downloadToStream("myProject.zip", streamToDownloadTo, downloadOptions); streamToDownloadTo.flush(); }
有关此方法的更多信息,请参阅 downloadToStream() API文档。
将文件下载到输入流
您可以使用输入流将 GridFS 存储桶中的文件下载到内存。您可以在 GridFS 存储桶上调用 openDownloadStream() 方法来打开 GridFSDownloadStream,这是一个输入流,您可以从中读取文件。
以下示例代码向您展示如何将 fileId 变量引用的文件下载到内存,并将其内容作为字符串打印:
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Opens an input stream to read a file containing a specified "_id" value and downloads the file try (GridFSDownloadStream downloadStream = gridFSBucket.openDownloadStream(fileId)) { int fileLength = (int) downloadStream.getGridFSFile().getLength(); byte[] bytesToWriteTo = new byte[fileLength]; downloadStream.read(bytesToWriteTo); // Prints the downloaded file's contents as a string System.out.println(new String(bytesToWriteTo, StandardCharsets.UTF_8)); }
有关此方法的更多信息,请参阅 openDownloadStream()。 API文档。
重命名文件
您可以通过调用 rename() 方法来更新存储桶中 GridFS 文件的名称。您必须用文件 ID 而不是文件名来指定要重命名的文件。
注意
rename() 方法每次仅支持更新一个文件的名称。要重命名多个文件,请从存储桶中检索与文件名称匹配的文件列表,从要重命名的文件中提取文件 ID 值,然后在单独的调用中将每个文件 ID 分别传递到 rename() 方法。
以下代码示例向您展示如何将 fileId 变量引用的文件的名称更新为“mongodbTutorial.zip”:
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Renames the file that has a specified "_id" value to "mongodbTutorial.zip" gridFSBucket.rename(fileId, "mongodbTutorial.zip");
有关此方法的更多信息,请参阅 rename() API文档。
删除文件
您可以通过调用 delete() 方法从 GridFS 存储桶中删除文件。您必须用文件 ID 而不是文件名来指定该文件。
注意
delete() 方法一次只支持删除一个文件。要删除多个文件,请从存储桶中检索文件,提取要删除的文件中的字段 ID 值,将每个文件 ID 分别调用给 delete() 方法。
以下代码示例向您展示了如何删除 fileId 变量引用的文件:
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Deletes the file that has a specified "_id" value from the GridFS bucket gridFSBucket.delete(fileId);
有关此方法的更多信息,请参阅删除() API文档。
删除 GridFS 存储桶
以下代码示例向您展示如何删除名为“mydb”的数据库上的默认GridFS存储桶。 要引用自定义命名的存储桶,请参阅本指南中有关如何创建自定义存储桶的部分。
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database); gridFSBucket.drop();
有关此方法的更多信息,请参阅 drop() API文档。
更多信息
可运行文件 GridFSTour.java 来自驱动程序源存储库