Overview
在本指南中,您可以了解如何使用 GridFS 在 MongoDB 中存储和检索大文件。GridFS 规范描述如何在存储过程中将文件分割为数据段并在检索过程中重新组合数据段。GridFS 的驱动程序实现管理文件存储的操作和组织。
如果文件大小超过 16 MB 的 BSON 文档大小限制,请使用 GridFS。有关 GridFS 是否适合您的使用案例的详细信息,请参阅 GridFS 服务器手册页面。
浏览以下部分,了解有关 GridFS 操作和实施的更多信息:
GridFS 的工作原理
GridFS 在存储桶中组织文件,存储桶是一组包含文件数据段和描述性信息的 MongoDB 集合。存储桶包含以下集合,使用 GridFS 规范中定义的约定命名:
chunks集合存储二进制文件数据段。files集合存储文件元数据。
创建新的 GridFS 桶时,驱动程序会创建 chunks 和 files 集合,并以默认桶名称 fs 作为前缀,除非您指定其他名称。该驱动程序还会在每个集合上创建索引,以确保有效检索文件和相关元数据。如果 GridFS 桶尚不存在,驱动程序仅在第一次写入操作时创建该桶。仅当索引不存在且桶为空时,驱动程序才会创建索引。有关 GridFS 索引的更多信息,请参阅 Server 手册的 GridFS 索引页面。
使用 GridFS 存储文件时,驱动程序会将文件拆分成小块,每个部分由 chunks 集合中的单独文档表示。它还在 files 集合中创建一个文档,其中包含唯一的文件 ID、文件名和其他文件元数据。您可以从内存或数据流上传文件。下图描述了 GridFS 在将文件上传到存储桶时如何分割文件:

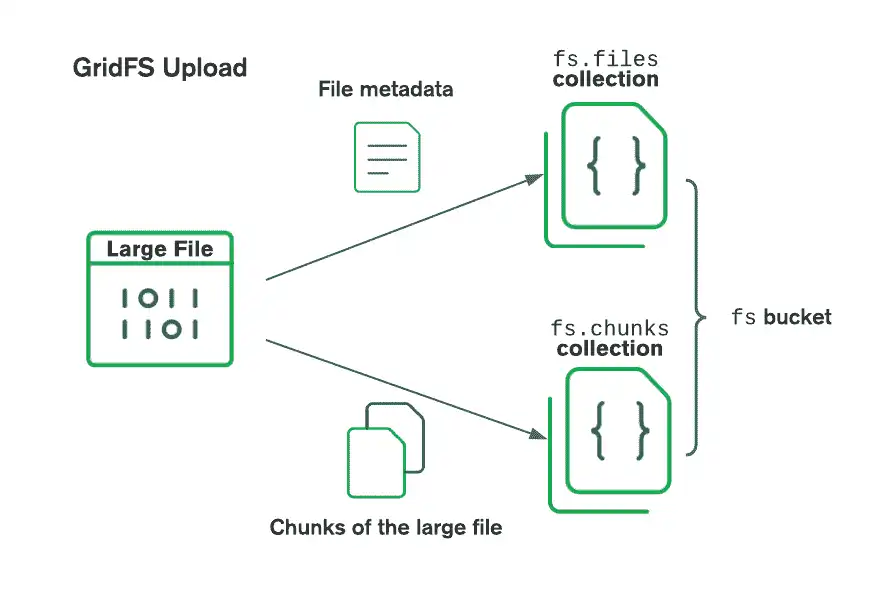
在检索文件时,GridFS 从指定存储桶上的 files 集合中获取元数据,并使用该信息通过 chunks 集合中的文档重建文件。您可以将文件读取到内存中,或者将其输出到流。
创建 GridFS 存储桶
创建一个存储桶或获取对现有存储桶的引用,以开始从 GridFS 存储或检索文件。创建一个 GridFSBucket 实例,并将数据库作为参数传递。然后,您可以使用 GridFSBucket 实例对存储桶中的文件调用读取和写入操作:
const db = client.db(dbName); const bucket = new mongodb.GridFSBucket(db);
将存储桶名称作为第二个参数传递给 create() 方法,以创建或引用具有默认名称 fs 之外的自定义名称的存储桶,如以下示例所示:
const bucket = new mongodb.GridFSBucket(db, { bucketName: 'myCustomBucket' });
有关更多信息,请参阅 GridFSBucket API 文档。
上传文件
使用 GridFSBucket 中的 openUploadStream() 方法为指定文件名创建上传流。您可以使用 pipe() 方法将 Node.js 读取流连接到上传流。使用 openUploadStream() 方法可以指定配置信息,如文件数据块大小和其他作为元数据存储的字段/值对。
以下示例展示了如何将由变量 fs 表示的 Node.js 读取流通过管道传递给 GridFSBucket 实例的 openUploadStream() 方法:
fs.createReadStream('./myFile'). pipe(bucket.openUploadStream('myFile', { chunkSizeBytes: 1048576, metadata: { field: 'myField', value: 'myValue' } }));
请参阅 openUploadStream() API 文档了解更多信息。
检索文件信息
在本部分中,您可以了解如何检索存储在 GridFS 存储桶的 files 集合的文件元数据。元数据包含所引用文件的相关信息,包括:
文件的
_id文件的名称
文件的长度/大小
上传日期和时间
您可以在其中存储任何其他信息的
metadata文档
在 GridFSBucket 实例上调用 find() 方法,以便从 GridFS 存储桶中检索文件。该方法会返回一个 FindCursor 实例,您可以从该实列访问结果。
以下代码示例向你展示如何从 GridFS 存储桶中的所有文件中检索和打印文件元数据。在从 FindCursor 可迭代表中遍历检索结果的各种方法中,以下示例使用 for await...of 事务语法来显示结果:
const cursor = bucket.find({}); for await (const doc of cursor) { console.log(doc); }
find() 方法可接受各种查询规范,可与 sort()、limit() 和 project() 等其他方法结合使用。
有关本节中提到的类和方法的更多信息,请参阅以下资源:
下载文件
您可以使用 GridFSBucket 中的 openDownloadStreamByName() 方法创建下载流,从 MongoDB 数据库下载文件。
下面的示例展示了如何将存储在 filename 字段中的文件名引用的文件下载到工作目录中:
bucket.openDownloadStreamByName('myFile'). pipe(fs.createWriteStream('./outputFile'));
注意
如果存在多个具有相同 filename 值的文档,GridFS 将流式传输具有给定名称(由 uploadDate 字段决定)的最新文件。
或者可以使用 openDownloadStream() 方法将文件的 _id 字段作为参数:
bucket.openDownloadStream(ObjectId("60edece5e06275bf0463aaf3")). pipe(fs.createWriteStream('./outputFile'));
注意
GridFS 流媒体 API 无法加载部分数据段。当下载流需要从 MongoDB 拉取一个数据段时,它会将整个数据段拉入内存。255 KB 默认数据段大小通常足够,但您可以数据段大小,以减少内存开销。
有关 openDownloadStreamByName() 方法的更多信息,请参该方法的 API 文档。
重命名文件
使用 rename() 方法更新存储桶中 GridFS 文件的名称。您必须用文件的 _id 字段而不是文件名来指定要重命名的文件。
注意
rename() 方法每次仅支持更新一个文件的名称。要重命名多个文件,请从存储桶中检索与文件名匹配的文件列表,从要重命名的文件中提取 _id 字段(Field),然后将每个值分别传递到 rename() 方法。
以下示例显示如何通过引用文档的 _id 字段(Field)将 filename 字段(Field)更新为“newFileName”:
bucket.rename(ObjectId("60edece5e06275bf0463aaf3"), "newFileName");
有关此方法的更多信息,请参阅重命名() API 文档。
删除文件
使用 delete() 方法以从存储桶中删除文件。您必须用文件的 _id 字段而不是文件名来指定该文件。
注意
delete() 方法一次只支持删除一个文件。要删除多个文件,请从存储桶中检索文件,提取要删除的文件中的 _id 字段,将每个值分别调用给 delete() 方法。
下面的示例展示了如何通过引用文件的 _id 字段来删除文件:
bucket.delete(ObjectId("60edece5e06275bf0463aaf3"));
请参阅 delete() API 文档,了解此方法的更多信息。
删除 GridFS 存储桶
使用 drop() 方法删除存储桶的 files 和 chunks 集合,从而有效删除存储桶。以下代码示例展示了如何删除 GridFS 存储桶:
bucket.drop();
有关此方法的更多信息,请参阅 drop() API 文档。