Overview
在本指南中,您可以了解如何使用GridFS在 MongoDB 中存储和检索大文件。 GridFS 规范描述了如何在存储过程中将文件分割为数据块,并在检索过程中重新组合这些数据块。GridFS 的 Rust 驱动程序实现托管文件存储的操作和组织。
如果文件大小超过16 MB 的 BSON 文档大小限制,请使用 GridFS。 GridFS 还可以帮助您访问文件,而无需将整个文件加载到内存中。 有关 GridFS 是否适合您的使用案例的更多详细信息,请参阅 MongoDB Server手册中的 GridFS 页面。
要了解有关 GridFS 的更多信息,请导航至本指南中的以下部分:
GridFS 的工作原理
GridFS 在bucket中组织文件,而bucket是一组包含文件数据块和描述性信息的 MongoDB collection。存储桶包含以下collection,根据 GridFS 规范中定义的约定命名:
chunks,存储二进制文件数据块files,存储文件元数据
当创建新的 GridFS 存储桶时,Rust 驱动程序会执行以下操作:
创建
chunks和files集合,以默认存储桶名称fs作为前缀,除非您指定其他名称在每个collection上创建索引,确保高效检索文件和相关元数据
您可以按照本页引用 GridFS 存储桶部分中的步骤创建对 GridFS 存储桶的引用。 但是,在执行第一个写入操作之前,驱动程序不会创建新的 GridFS 存储桶及其索引。 有关 GridFS 索引的更多信息,请参阅 MongoDB Server手册中的 GridFS 索引 页面。
在 GridFS 存储桶中存储文件时,Rust 驱动程序会创建以下文档:
files集合中的一个文档,存储唯一文件 ID、文件名和其他文件元数据chunkscollection中存储文件内容的一个或多个文档,驱动程序会将其分割成较小的部分
下图描述了 GridFS 在上传到存储桶时如何分割文件:

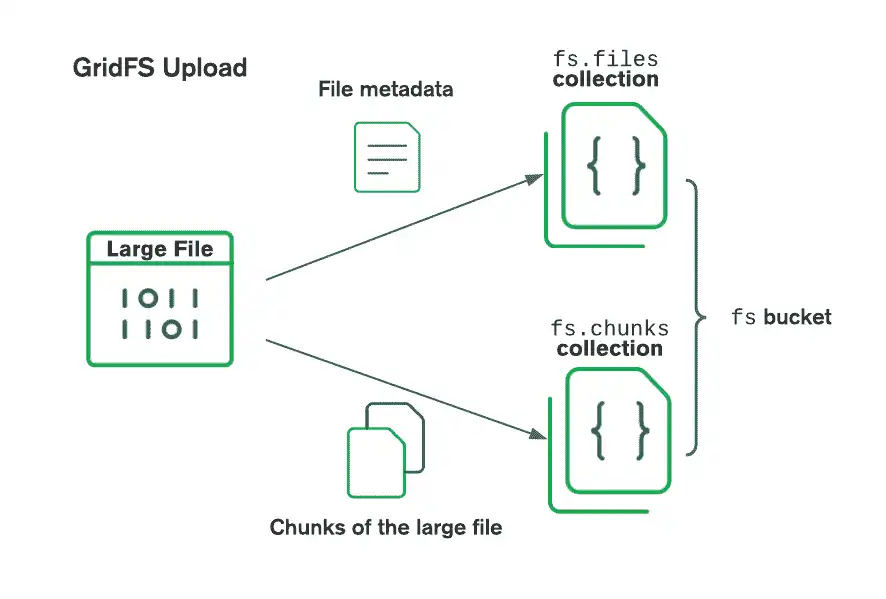
在检索文件时,GridFS 从指定存储桶上的 files 集合中获取元数据,并使用该信息通过 chunks 集合中的文档重建文件。您可以将文件读取到内存中,或者将其输出到流。
引用 GridFS 存储桶
在 GridFS 存储桶中存储文件之前,请创建存储桶引用或获取对现有存储桶的引用。
以下示例对数据库实例调用gridfs_bucket()方法,该方法创建对新的或现有 GridFS 存储桶的引用:
let bucket = my_db.gridfs_bucket(None);
您可以通过设置GridFsBucketOptions结构的bucket_name字段来指定自定义存储桶名称。
注意
实例化结构
Rust驱动程序实现了用于创建某些结构体类型(包括 GridFsBucketOptions)的 Builder 设计模式。您可以使用 builder() 方法通过链接选项构建者方法来构造每种类型的实例。
下表描述了可用于设立GridFsBucketOptions字段的方法:
方法 | Possible Values | 说明 |
|---|---|---|
bucket_name() | Any String value | Specifies a bucket name, which is set to fs by default |
| 任何 | 指定用于将文件拆分为多个数据块的数据块大小,默认为 255 KB |
write_concern() | WriteConcern::w(),WriteConcern::w_timeout(),WriteConcern::journal(),WriteConcern::majority() | Specifies the bucket's write concern, which is set to the database's write concern by default |
|
| 指定存储桶的读关注,默认设置为数据库的读关注 |
selection_criteria() | SelectionCriteria::ReadPreference,SelectionCriteria::Predicate | Specifies which servers are suitable for a bucket operation, which is set to the database's selection criteria by default |
以下示例在GridFsBucketOptions实例中指定选项,为写入操作配置自定义存储桶名称和五秒时间限制:
let wc = WriteConcern::builder().w_timeout(Duration::new(5, 0)).build(); let opts = GridFsBucketOptions::builder() .bucket_name("my_bucket".to_string()) .write_concern(wc) .build(); let bucket_with_opts = my_db.gridfs_bucket(opts);
上传文件
您可以通过打开上传流并将文件写入该流来将文件上传到 GridFS 存储桶。 在存储桶实例上调用open_upload_stream()方法以打开流。 此方法返回一个实例的GridFsUploadStream,您可以向其中写入文件的内容。要将文件内容上传到GridFsUploadStream ,请调用write_all()方法并将文件字节作为参数传递。
提示
导入所需模块
GridFsUploadStream 结构体实现 futures_io::AsyncWrite 特征。要使用 AsyncWrite 写入方法,例如 write_all(),请使用以下 use 声明将 AsyncWriteExt 模块导入到应用程序文件中:
use futures_util::io::AsyncWriteExt;
以下示例使用上传流将名为"example.txt"的文件上传到 GridFS 存储桶:
let bucket = my_db.gridfs_bucket(None); let file_bytes = fs::read("example.txt").await?; let mut upload_stream = bucket.open_upload_stream("example").await?; upload_stream.write_all(&file_bytes[..]).await?; println!("Document uploaded with ID: {}", upload_stream.id()); upload_stream.close().await?;
下载文件
您可以通过打开下载流并从流中读取文件来从 GridFS 存储桶下载文件。 对存储桶实例调用open_download_stream()方法,指定所需文件的_id值作为参数。 此方法返回一个实例GridFsDownloadStream ,您可以从中访问该文件。 要从GridFsDownloadStream读取文件,请调用read_to_end()方法并将向量作为参数传递。
提示
导入所需模块
GridFsDownloadStream结构实现了futures_io::AsyncRead特征。 要使用AsyncRead读取方法,例如read_to_end() ,请使用以下使用声明将AsyncReadExt模块导入到您的应用程序文件中:
use futures_util::io::AsyncReadExt;
以下示例使用下载流从 GridFS 存储桶下载_id值为3289的文件:
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let mut buf = Vec::new(); let mut download_stream = bucket.open_download_stream(Bson::ObjectId(id)).await?; let result = download_stream.read_to_end(&mut buf).await?; println!("{:?}", result);
注意
GridFS 流媒体 API 无法加载部分数据块。当下载流需要从 MongoDB 拉取一个数据块时,它会将整个数据块拉取到内存中。255 KB 默认数据块大小通常足够,但您可以减小数据块大小以减少内存开销。
检索文件信息
您可以检索有关 GridFS 存储桶的 files 集合中存储的文件的信息。每个文件都作为 FilesCollectionDocument 类型的实例存储,其中包括以下表示文件信息的字段:
_id:文件 IDlength:文件大小chunk_size_bytes:文件的数据块大小upload_date:文件的上传日期和时间filename:文件的名称metadata:存储用户指定元数据的文档
在 GridFS 存储桶实例上调用find()方法,从存储桶中检索文件。 该方法返回一个游标实例,您可以从该实例访问结果。
以下示例检索并打印 GridFS 存储桶中每个文件的长度:
let bucket = my_db.gridfs_bucket(None); let filter = doc! {}; let mut cursor = bucket.find(filter).await?; while let Some(result) = cursor.try_next().await? { println!("File length: {}\n", result.length); };
重命名文件
您可以通过在存储桶实例上调用rename()方法来更新存储桶中 GridFS 文件的名称。 将目标文件的_id值和新文件名作为参数传递给rename()方法。
注意
rename() 方法每次仅支持更新一个文件的名称。要重命名多个文件,请从存储桶中检索与文件名匹配的文件列表,从要重命名的文件中提取 _id 字段(Field),然后将每个值分别传递到 rename() 方法。
以下示例将包含_id值为3289的文件的filename字段更新为"new_file_name" :
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let new_name = "new_file_name"; bucket.rename(Bson::ObjectId(id), new_name).await?;
删除文件
您可以使用delete()方法从存储桶中删除文件。 要删除文件,请在存储桶实例上调用delete()并将文件的_id值作为参数传递。
注意
delete()方法一次只支持删除一个文件。 要删除多个文件,请从存储桶中检索文件,提取要删除的文件中的字段,然后将每个_id _id值分别调用给delete() 方法。
以下示例删除_id字段的值为3289的文件:
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); bucket.delete(Bson::ObjectId(id)).await?;
删除 GridFS 存储桶
您可以使用drop()方法删除存储桶,这会删除存储桶的files和chunkscollection。要删除存储桶,请对存储桶实例调用drop() 。
以下示例删除了一个 GridFS 存储桶:
let bucket = my_db.gridfs_bucket(None); bucket.drop().await?;
更多信息
API 文档
要进一步了解本指南所提及的任何方法或类型,请参阅以下 API 文档: