Overview
在本指南中,您可以学习如何使用GridFS在MongoDB中存储和检索大文件。GridFS是由C++驱动程序实现的规范,描述了如何在存储文件时将文件分割为数据块,以及在检索文件时如何重新组合这些文件。GridFS驱动程序的实现是一个抽象,用于管理文件存储的操作和组织。
如果文件大小超过 16 MB 的BSON文档大小限制,请使用GridFS 。有关GridFS是否适合您的使用案例的更多详细信息,请参阅MongoDB Server手册中的 GridFS 。
GridFS 的工作原理
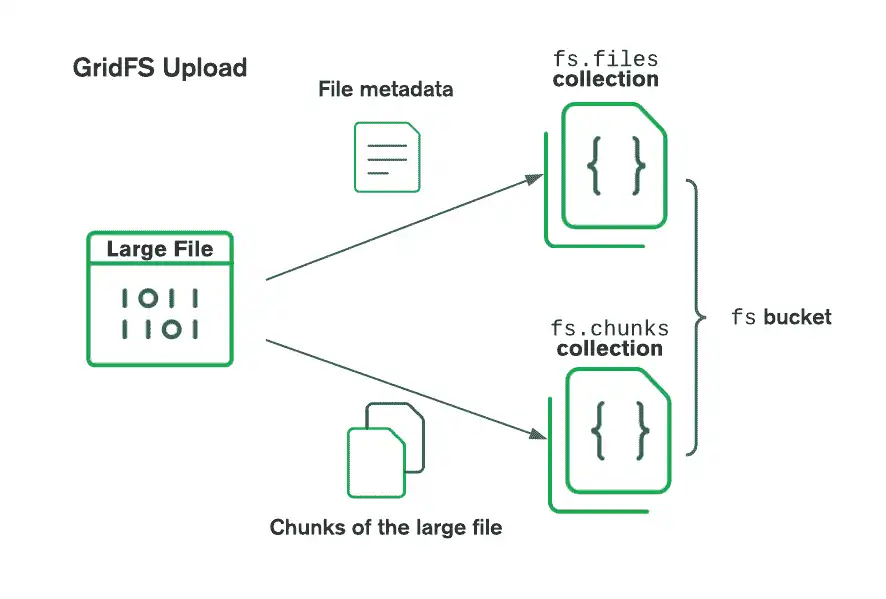
GridFS 在存储桶中组织文件,存储桶是一组包含文件数据段及其描述信息的MongoDB 集合。存储桶包含以下集合,使用 GridFS 规范中定义的约定命名:
chunks集合,存储二进制文件段files集合,存储文件元数据
如果GridFS存储桶不存在,则当您首次向其中写入数据时,驱动程序会创建该存储桶。存储桶包含前面以默认默认桶名称 fs 为前缀的集合,除非您指定了其他名称。为了确保有效检索文件和相关元数据,驱动程序会在每个集合上创建一个索引。在对GridFS存储桶执行读取和写入操作之前,驱动程序会确保这些索引存在。
有关GridFS索引的更多信息,请参阅MongoDB Server手册中的GridFS索引。MongoDB Server
使用GridFS存储文件时,驱动程序会将文件分割成较小的数据块,每个数据块由 chunks集合中的单独文档表示。它还在 files 集合中创建一个文档,其中包含文件 ID、文件名称和其他文件元数据。您可以通过将流递给C++驱动程序进行使用或创建新流并直接写入来上传文件。
下图展示了GridFS在上传到存储桶时如何分割文件:

检索文件时, GridFS从指定存储桶的 files集合中获取元数据,并使用该信息从 chunks集合中的文档重建文件。您可以通过将文件内容写入现有流或创建指向该文件的新流来读取该文件。
创建 GridFS 存储桶
要开始从GridFS存储或检索文件,请对数据库调用 gridfs_bucket() 方法。此方法访问现有存储桶,如果不存在,则创建新存储桶。
以下示例对db数据库调用gridfs_bucket()方法:
auto bucket = db.gridfs_bucket();
自定义存储桶
您可以通过将 mongocxx::options::gridfs::bucket 类的实例作为可选参数传递给 gridfs_bucket() 方法来自定义GridFS存储桶配置。下表描述了您可以在 mongocxx::options::gridfs::bucket实例中设立的字段:
字段 | 说明 |
|---|---|
| Specifies the bucket name to use as a prefix for the files and chunks collections.
The default value is "fs".Type: std::string |
| Specifies the chunk size that GridFS splits files into. The default value is 261120.Type: std::int32_t |
| Specifies the read concern to use for bucket operations. The default value is the
database's read concern. Type: mongocxx::read_concern |
| Specifies the read preference to use for bucket operations. The default value is the
database's read preference. Type: mongocxx::read_preference |
| Specifies the write concern to use for bucket operations. The default value is the
database's write concern. Type: mongocxx::write_concern |
以下示例通过设置 mongocxx::options::gridfs::bucket实例的 bucket_name字段来创建名为 "myCustomBucket" 的存储桶:
mongocxx::options::gridfs::bucket opts; opts.bucket_name("myCustomBucket"); auto bucket = db.gridfs_bucket(opts);
上传文件
您可以使用以下方法将文件上传到GridFS存储桶:
open_upload_stream() :打开一个新的上传流,您可以在其中写入文件内容
upload_from_stream() :将现有流的内容上传到GridFS文件
写入上传流
使用 open_upload_stream() 方法为给定文件名创建上传流。open_upload_stream() 方法允许您在 options::gridfs::upload实例中指定配置信息,您可以将其作为参数传递。
此示例使用上传流来执行以下操作:
设置选项实例的
chunk_size_bytes字段打开名为
"my_file"的新GridFS文件的可写流并应用chunk_size_bytes选项调用
write()方法以写入my_file,流指向调用
close()方法关闭指向my_file的流
mongocxx::options::gridfs::upload opts; opts.chunk_size_bytes(1048576); auto uploader = bucket.open_upload_stream("my_file", opts); // ASCII for "HelloWorld" std::uint8_t bytes[10] = {72, 101, 108, 108, 111, 87, 111, 114, 108, 100}; for (auto i = 0; i < 5; ++i) { uploader.write(bytes, 10); } uploader.close();
上传现有流
使用 upload_from_stream() 方法将流的内容上传到新的GridFS文件。upload_from_stream() 方法允许您在 options::gridfs::upload实例中指定配置信息,您可以将其作为参数传递。
此示例将执行以下动作:
以二进制读取模式将位于
/path/to/input_file的文件作为流打开调用
upload_from_stream()方法将流的内容上传到名为"new_file"的GridFS文件
std::ifstream file("/path/to/input_file", std::ios::binary); bucket.upload_from_stream("new_file", &file);
检索文件信息
在本部分中,您可以了解如何检索存储在 GridFS 存储桶的 files 集合的文件元数据。元数据包含所引用文件的相关信息,包括:
文件的
_id文件的名称
文件的长度/大小
上传日期和时间
可以在其中存储其他信息的
metadata文档
要从GridFS存储桶检索文件,请在您的存储桶上调用 mongocxx::gridfs::bucket::find() 方法。该方法会返回一个 mongocxx::cursor实例,您可以从该实例访问权限结果。要学习;了解有关游标的更多信息,请参阅 《从游标访问数据》指南。
例子
以下代码示例演示如何从GridFS存储桶中的文件检索和打印文件元数据。 它使用for 循环遍历返回的游标,并显示上传文件示例中上传的文件的内容:
auto cursor = bucket.find({}); for (auto&& doc : cursor) { std::cout << bsoncxx::to_json(doc) << std::endl; }
{ "_id" : { "$oid" : "..." }, "length" : 13, "chunkSize" : 261120, "uploadDate" : { "$date" : ... }, "filename" : "new_file" } { "_id" : { "$oid" : "..." }, "length" : 50, "chunkSize" : 1048576, "uploadDate" : { "$date" : ... }, "filename" : "my_file" }
find() 方法接受各种查询规范。您可以使用其 mongocxx::options::find 参数指定排序顺序、要返回的最大文档数以及在返回之前要跳过的文档数。要查看可用选项列表,请参阅API文档。
下载文件
您可以使用以下方法从GridFS存储桶下载文件:
open_download_stream() :打开新的下载流,您可以从中读取文件内容
download_to_stream() :将整个文件写入现有下载流
从下载流中读取
您可以使用open_download_stream()方法创建下载流,从MongoDB 数据库下载文件。
此示例使用下载流来执行以下操作:
检索名为
"new_file"的GridFS文件的_id值将
_id值传递给open_download_stream()方法,以将文件作为可读流打开创建一个
buffer向量来存储文件内容调用
read()方法将文件内容从downloader流读入向量
auto doc = db["fs.files"].find_one(make_document(kvp("filename", "new_file"))); auto id = doc->view()["_id"].get_value(); auto downloader = bucket.open_download_stream(id); std::vector<uint8_t> buffer(downloader.file_length()); downloader.read(buffer.data(), buffer.size());
下载到现有流
您可以通过在存储桶上调用download_to_stream()方法,将GridFS文件的内容下载到现有流。
此示例将执行以下动作:
以二进制写入模式将位于
/path/to/output_file的文件作为流打开检索名为
"new_file"的GridFS文件的_id值将
_id值传递给download_to_stream()以将文件下载到流
std::ofstream output_file("/path/to/output_file", std::ios::binary); auto doc = db["fs.files"].find_one(make_document(kvp("filename", "new_file"))); auto id = doc->view()["_id"].get_value(); bucket.download_to_stream(id, &output_file);
删除文件
使用delete_file()方法从存储桶中删除文件的集合文档和关联的数据段。 这实际上删除了该文件。 您必须用文件的_id字段而不是文件名来指定文件。
以下示例展示了如何通过将名为 "my_file" 的文件的 _id 值传递给 delete_file() 来删除该文件:
auto doc = db["fs.files"].find_one(make_document(kvp("filename", "my_file"))); auto id = doc->view()["_id"].get_value(); bucket.delete_file(id);
注意
文件修订
delete_file() 方法一次仅支持删除一个文件。如果要删除每个文件修订版本,或上传时间不同但股票相同文件名的文件,请收集每个修订版本的 _id 值。然后,将每个 _id 值分别传递给 delete_file() 方法。
API 文档
要学习更多有关使用C++驱动程序存储和检索大文件的信息,请参阅以下API文档: