定义
$densify5.1 版本中的新功能。
在文档序列中创建新文档,其中缺少字段中的某些值。
您可以使用
$densify执行以下操作:填补时间序列数据的空白
在数据群组之间添加缺失值。
用指定的数值范围填充数据。
语法
$densify 阶段采用以下语法:
{ $densify: { field: <fieldName>, partitionByFields: [ <field 1>, <field 2> ... <field n> ], range: { step: <number>, unit: <time unit>, bounds: < "full" || "partition" > || [ < lower bound >, < upper bound > ] } } }
$densify 阶段采用包含以下字段的文档:
字段 | 必要性 | 说明 |
|---|---|---|
必需 | ||
Optional | 充当对文档进行群组的复合键的字段设立。 在 如果省略此字段, 有关示例,请参阅使用分区进行密集化。 有关限制,请参阅 | |
必需 | 指定如何密集化数据的对象。 | |
必需 | 您可以将
如果
如果
如果
| |
必需 | 每个文档中字段值的递增量。 | |
您可以将
|
行为和限制
field 限制
对于包含指定字段的文档,如果 $densify 出现错误,则表示:
集合中的任何文档都有日期类型的
field值,且未指定单位字段。集合中的任何文档都有数值类型的
field值,并指定了单位字段。field名称以$开头。如果要密集化字段,必须重新命名。如需重命名字段,请使用$project。8.1 版本新增:
field与partitionByFields大量中的任何字段共享其前缀。示例,以下field和partitionByFields的组合会导致错误:field: "timestamp",partitionByFields: ["timestamp"]field: "timestamp",partitionByFields: ["timestamp.hours"]field: "timestamp.hours",partitionByFields: ["timestamp"]
partitionByFields 限制
$densify 会出错,如果 partitionByFields 数组中的任何字段名称:
求值为非字符串值。
以
$开头。
range.bounds 行为
如果 range.bounds 是一个数组:
注意
从MongoDB8.0 开始,$densify 将具有相等下限和上限的边界视为空设立,并且不会生成将该边界作为字段值的文档。
在以前的版本中,$densify 将具有相等下限和上限的边界视为闭区间,并在集合尚未包含具有边界值的文档时生成具有边界值的文档作为字段值。
示例, 的范围.bounds [10, 10]10在 之前的版本中生成字段值为 的额外的文档,但在8.08.0 及更高版本中不会生成此类文档。
输出顺序
$densify 不保证其输出的文档的排序顺序。
如需保证排序顺序,请在要排序的字段上使用 $sort。
示例
使时间序列数据密集化
创建 weather 集合,其中包含每隔四小时的温度读数。
db.weather.insertMany( [ { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T00:00:00.000Z"), "temp": 12 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T04:00:00.000Z"), "temp": 11 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T08:00:00.000Z"), "temp": 11 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T12:00:00.000Z"), "temp": 12 } ] )
本示例使用 $densify 阶段来填充四小时间隔之间的空白,以实现数据点的每小时粒度:
db.weather.aggregate( [ { $densify: { field: "timestamp", range: { step: 1, unit: "hour", bounds:[ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ] } } } ] )
在示例中:
$densify阶段填充了记录温度之间的时间空白。field: "timestamp"密集化timestamp字段。
range:step: 1将timestamp字段增加 1 个单位。unit: hour按小时密集化timestamp字段。bounds: [ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ]设置密集化的时间范围。
在以下输出中,$densify 阶段填补了 00:00:00 和 08:00:00 小时之间的时间间隔。
[ { _id: ObjectId("618c207c63056cfad0ca4309"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T00:00:00.000Z"), temp: 12 }, { timestamp: ISODate("2021-05-18T01:00:00.000Z") }, { timestamp: ISODate("2021-05-18T02:00:00.000Z") }, { timestamp: ISODate("2021-05-18T03:00:00.000Z") }, { _id: ObjectId("618c207c63056cfad0ca430a"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T04:00:00.000Z"), temp: 11 }, { timestamp: ISODate("2021-05-18T05:00:00.000Z") }, { timestamp: ISODate("2021-05-18T06:00:00.000Z") }, { timestamp: ISODate("2021-05-18T07:00:00.000Z") }, { _id: ObjectId("618c207c63056cfad0ca430b"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T08:00:00.000Z"), temp: 11 } { _id: ObjectId("618c207c63056cfad0ca430c"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T12:00:00.000Z"), temp: 12 } ]
通过分区实现密集化
创建 coffee 集合,其中包含两种咖啡豆的数据:
db.coffee.insertMany( [ { "altitude": 600, "variety": "Arabica Typica", "score": 68.3 }, { "altitude": 750, "variety": "Arabica Typica", "score": 69.5 }, { "altitude": 950, "variety": "Arabica Typica", "score": 70.5 }, { "altitude": 1250, "variety": "Gesha", "score": 88.15 }, { "altitude": 1700, "variety": "Gesha", "score": 95.5, "price": 1029 } ] )
密集化各种数值
此示例使用 $densify 来加密每种咖啡 variety 的 altitude 字段:
db.coffee.aggregate( [ { $densify: { field: "altitude", partitionByFields: [ "variety" ], range: { bounds: "full", step: 200 } } } ] )
聚合示例:
按
variety对文档分区,为Arabica Typica和Gesha咖啡分别创建一个分组。指定
full范围,这意味着数据在每个分区的整个现有文档范围内进行密集化。指定
step为200,意味着以200的altitude间隔创建新文档。
该聚合输出以下文档:
[ { _id: ObjectId("618c031814fbe03334480475"), altitude: 600, variety: 'Arabica Typica', score: 68.3 }, { _id: ObjectId("618c031814fbe03334480476"), altitude: 750, variety: 'Arabica Typica', score: 69.5 }, { variety: 'Arabica Typica', altitude: 800 }, { _id: ObjectId("618c031814fbe03334480477"), altitude: 950, variety: 'Arabica Typica', score: 70.5 }, { variety: 'Gesha', altitude: 600 }, { variety: 'Gesha', altitude: 800 }, { variety: 'Gesha', altitude: 1000 }, { variety: 'Gesha', altitude: 1200 }, { _id: ObjectId("618c031814fbe03334480478"), altitude: 1250, variety: 'Gesha', score: 88.15 }, { variety: 'Gesha', altitude: 1400 }, { variety: 'Gesha', altitude: 1600 }, { _id: ObjectId("618c031814fbe03334480479"), altitude: 1700, variety: 'Gesha', score: 95.5, price: 1029 }, { variety: 'Arabica Typica', altitude: 1000 }, { variety: 'Arabica Typica', altitude: 1200 }, { variety: 'Arabica Typica', altitude: 1400 }, { variety: 'Arabica Typica', altitude: 1600 } ]
该图片直观展示了使用 $densify 创建的文档:

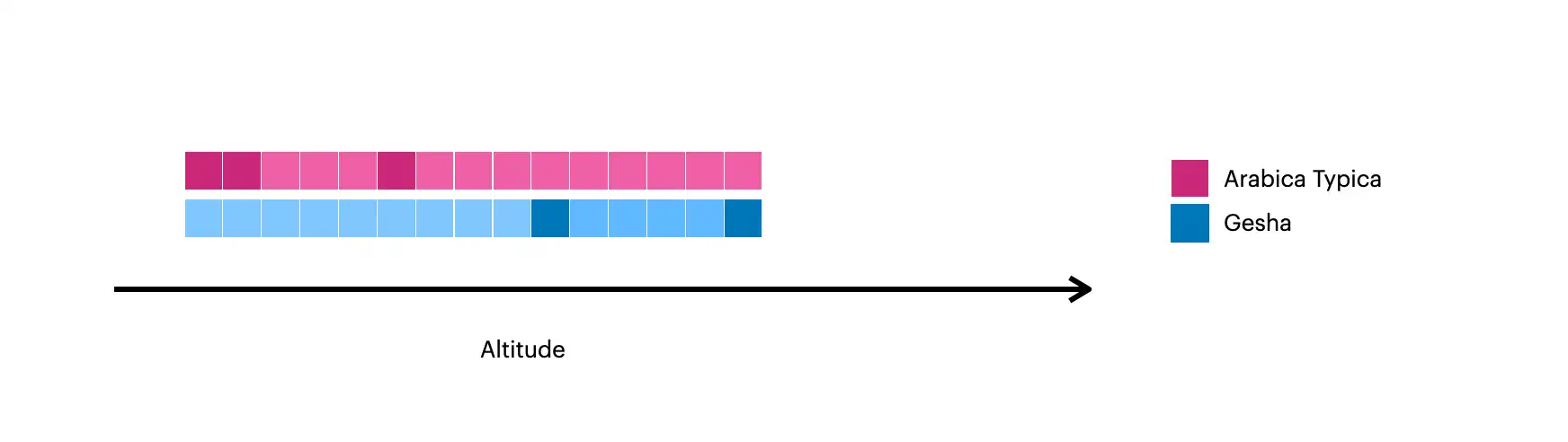
较深的方块表示集合中的原始文档。
较浅的方块表示使用
$densify创建的文档。
密集化每个分区中的值
此示例使用 $densify 仅加密每个 variety 内的 altitude 字段的间隙:
db.coffee.aggregate( [ { $densify: { field: "altitude", partitionByFields: [ "variety" ], range: { bounds: "partition", step: 200 } } } ] )
聚合示例:
按
variety对文档分区,为Arabica Typica和Gesha咖啡分别创建一个分组。指定
partition范围,这意味着数据在每个分区内均已加密。对于
Arabica Typica分区,范围是600-950。对于
Gesha分区,范围是1250-1700。
指定
step为200,意味着以200的altitude间隔创建新文档。
该聚合输出以下文档:
[ { _id: ObjectId("618c031814fbe03334480475"), altitude: 600, variety: 'Arabica Typica', score: 68.3 }, { _id: ObjectId("618c031814fbe03334480476"), altitude: 750, variety: 'Arabica Typica', score: 69.5 }, { variety: 'Arabica Typica', altitude: 800 }, { _id: ObjectId("618c031814fbe03334480477"), altitude: 950, variety: 'Arabica Typica', score: 70.5 }, { _id: ObjectId("618c031814fbe03334480478"), altitude: 1250, variety: 'Gesha', score: 88.15 }, { variety: 'Gesha', altitude: 1450 }, { variety: 'Gesha', altitude: 1650 }, { _id: ObjectId("618c031814fbe03334480479"), altitude: 1700, variety: 'Gesha', score: 95.5, price: 1029 } ]
该图片直观展示了使用 $densify 创建的文档:

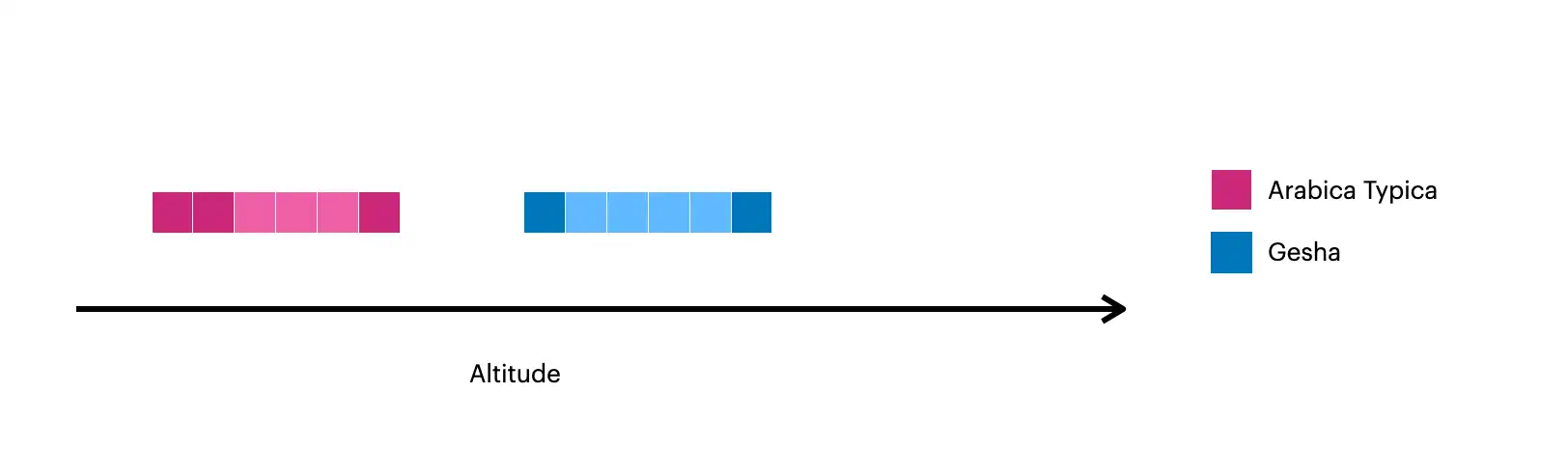
较深的方块表示集合中的原始文档。
较浅的方块表示使用
$densify创建的文档。
本页上的C#示例使用Atlas示例数据集中的 sample_weatherdata.data集合。要学习;了解如何创建免费的MongoDB Atlas 群集并加载示例数据集,请参阅MongoDB .NET/ C#驱动程序文档中的入门。
以下 Weather 和 Point 类对 sample_weatherdata.data集合中的文档进行建模:
public class Weather { public Guid Id { get; set; } public Point Position { get; set; } [] public DateTime Timestamp { get; set; } } public class Point { public float[] Coordinates { get; set; } }
sample_weatherdata.data集合包含以下文档,这些文档包含同一 position字段的测量值,间隔一小时:
Document{{ _id=5553a..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:00:00 EST 1984, ... }} Document{{ _id=5553b..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 09:00:00 EST 1984, ... }}
要使用MongoDB .NET/ C#驱动程序将 $densify 阶段添加到聚合管道,请对 PipelineDefinition对象调用 Densify() 方法。
以下示例创建了一个管道阶段,该阶段在前两个文档之间每隔 15 分钟添加一个文档。然后,代码根据这些文档的 Position.Coordinates字段的值对这些文档进行分组。
var densifyTimeRange = new DensifyDateTimeRange( new DensifyLowerUpperDateTimeBounds( lowerBound: new DateTime(1984, 3, 5, 8, 0, 0), upperBound: new DateTime(1984, 3, 5, 9, 0, 0) ), step: 15, unit: DensifyDateTimeUnit.Minutes ); var pipeline = new EmptyPipelineDefinition<Weather>() .Densify( field: w => w.Timestamp, range: densifyTimeRange, partitionByFields: [w => w.Position.Coordinates]);
上一个聚合阶段会在集合中生成以下突出显示的文档:
Document{{ _id=5553a..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:00:00 EST 1984, ... }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:15:00 EST 1984 }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:30:00 EST 1984 }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:45:00 EST 1984 }} Document{{ _id=5553b..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 09:00:00 EST 1984, ... }}
本页中的 Node.js 示例使用来自 Atlas 示例数据集的 sample_weatherdata.data 集合。要学习如何创建免费的 MongoDB Atlas 集群并加载示例数据集,请参阅 MongoDB Node.js 驱动程序文档中的入门指南。
sample_weatherdata.data集合包含以下文档,这些文档包含同一 position字段的测量值,间隔一小时:
{_id: new ObjectId(...), ts: 1984-03-05T13:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }, {_id: new ObjectId(...), ts: 1984-03-05T14:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }
要使用MongoDB Node.js驱动程序将 $densify 阶段添加到聚合管道,请在管道对象中使用 $densify操作符。
以下示例创建了一个管道阶段,该阶段在前两个文档之间每隔 15 分钟添加一个文档。然后,代码根据这些文档的 position.coordinates字段的值对这些文档进行分组。然后,该示例运行聚合管道:
const pipeline = [ { $densify: { field: "ts", partitionByFields: ["position.coordinates"], range: { step: 15, unit: "minute", bounds: [new Date(1984, 3, 5, 8, 0, 0), new Date(1984, 3, 5, 9, 0, 0)] } } } ]; const cursor = collection.aggregate(pipeline); return cursor;
上一个聚合阶段会在集合中生成以下突出显示的文档:
{ _id: new ObjectId(...), ts: 1984-03-05T13:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:15:00.000Z }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:30:00.000Z }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:45:00.000Z }, { _id: new ObjectId(...), ts: 1984-03-05T14:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }