When you design your schema, consider how your application needs to query and return related data. How you map relationships between data entities affects your application's performance and scalability.
The recommended way to handle related data is to embed it in a sub-document.
Embedding related data lets your application query the data it needs with a
single read operation and avoid slow $lookup operations.
For some use cases, you can use a reference to point to related data in a separate collection.
About this Task
To determine if you should embed related data or use references, consider the relative importance of the following goals for your application:
- Improve queries on related data
- If your application frequently queries one entity to return data about
another entity, embed the data to avoid the need for frequent
$lookupoperations. - Improve data returned from different entities
- If your application returns data from related entities together, embed the data in a single collection.
- Improve update performance
- If your application frequently updates related data, consider storing the data in its own collection and using a reference to access it. When you use a reference, you reduce your application's write workload by only needing to update the data in a single place.
To learn more about the benefits of embedded data and references, see Link Related Data.
Before you Begin
Mapping relationships is the second step of the schema design process. Before you map relationships, identify your application's workload to determine the data it needs.
Steps
Identify related data in your schema
Identify the data that your application queries and how entities relate to each other.
Consider the operations you identified from your application's workload in the first step of the schema design process. Note the information these operations write and return, and what information overlaps between multiple operations.
Create a schema map for your related data
Your schema map should show related data fields and the type of relationship between those fields (one-to-one, one-to-many, many-to-many).
Your schema map can resemble an entity-relationship model.
Choose whether to embed related data or use references
The decision to embed data or use references depends on your application's common queries. Review the queries you identified in the Identify Application Workload step and use the guidelines mentioned earlier on this page to design your schema to support frequent and critical queries.
Configure your databases, collections, and application logic to match the approach you choose.
Examples
Consider the following schema map for a blog application:

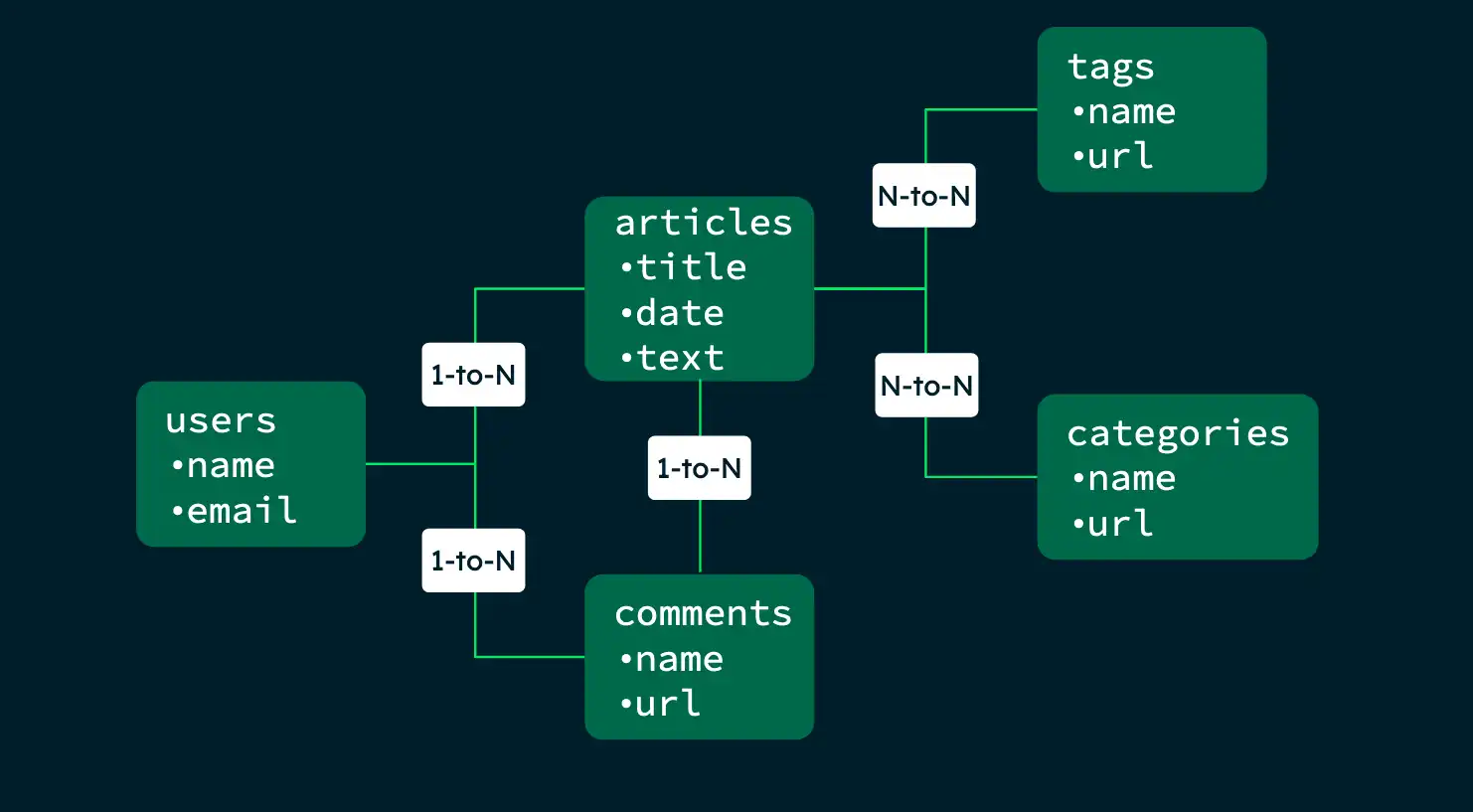
The following examples show how to optimize your schema for different queries depending on the needs of your application.
Optimize Queries for Articles
If your application primarily queries articles for information such as title,
embed related information in the articles collection to return all data
needed by the application in a single operation.
The following document is optimized for queries on articles:
db.articles.insertOne( { title: "My Favorite Vacation", date: ISODate("2023-06-02"), text: "We spent seven days in Italy...", tags: [ { name: "travel", url: "<blog-site>/tags/travel" }, { name: "adventure", url: "<blog-site>/tags/adventure" } ], comments: [ { name: "pedro123", text: "Great article!" } ], author: { name: "alice123", email: "alice@mycompany.com", avatar: "photo1.jpg" } } )
Optimize Queries for Articles and Authors
If your application returns article information and author information separately, consider storing articles and authors in separate collections. This schema design reduces the work required to return author information, and lets you return only author information without including unneeded fields.
In the following schema, the articles collection contains an
authorId field, which is a reference to the authors collection.
Articles Collection
db.articles.insertOne( { title: "My Favorite Vacation", date: ISODate("2023-06-02"), text: "We spent seven days in Italy...", authorId: 987, tags: [ { name: "travel", url: "<blog-site>/tags/travel" }, { name: "adventure", url: "<blog-site>/tags/adventure" } ], comments: [ { name: "pedro345", text: "Great article!" } ] } )
Authors Collection
db.authors.insertOne( { _id: 987, name: "alice123", email: "alice@mycompany.com", avatar: "photo1.jpg" } )
Next Steps
After you map relationships for your application's data, the next step in the schema design process is to apply design patterns to optimize your schema. See Apply Design Patterns.