Building With Patterns: The Computed Pattern
We've looked at various ways of optimally storing data in the Building with Patterns series. Now, we're going to look at a different aspect of schema design. Just storing data and having it available isn't, typically, all that useful. The usefulness of data becomes much more apparent when we can compute values from it. What's the total sales revenue of the latest Amazon Alexa? How many viewers watched the latest blockbuster movie? These types of questions can be answered from data stored in a database but must be computed.
Running these computations every time they're requested though becomes a highly resource-intensive process, especially on huge datasets. CPU cycles, disk access, memory all can be involved.
Think of a movie information web application. Every time we visit the application to look up a movie, the page provides information about the number of cinemas the movie has played in, the total number of people who've watched the movie, and the overall revenue. If the application has to constantly compute those values for each page visit, it could use a lot of processing resources on popular movies
Most of the time, however, we don't need to know those exact numbers. We could do the calculations in the background and update the main movie information document once in a while. These computations then allow us to show a valid representation of the data without having to put extra effort on the CPU.
The Computed Pattern
The Computed Pattern is utilized when we have data that needs to be computed repeatedly in our application. The Computed Pattern is also utilized when the data access pattern is read intensive; for example, if you have 1,000,000 reads per hour but only 1,000 writes per hour, doing the computation at the time of a write would divide the number of calculations by a factor 1000.
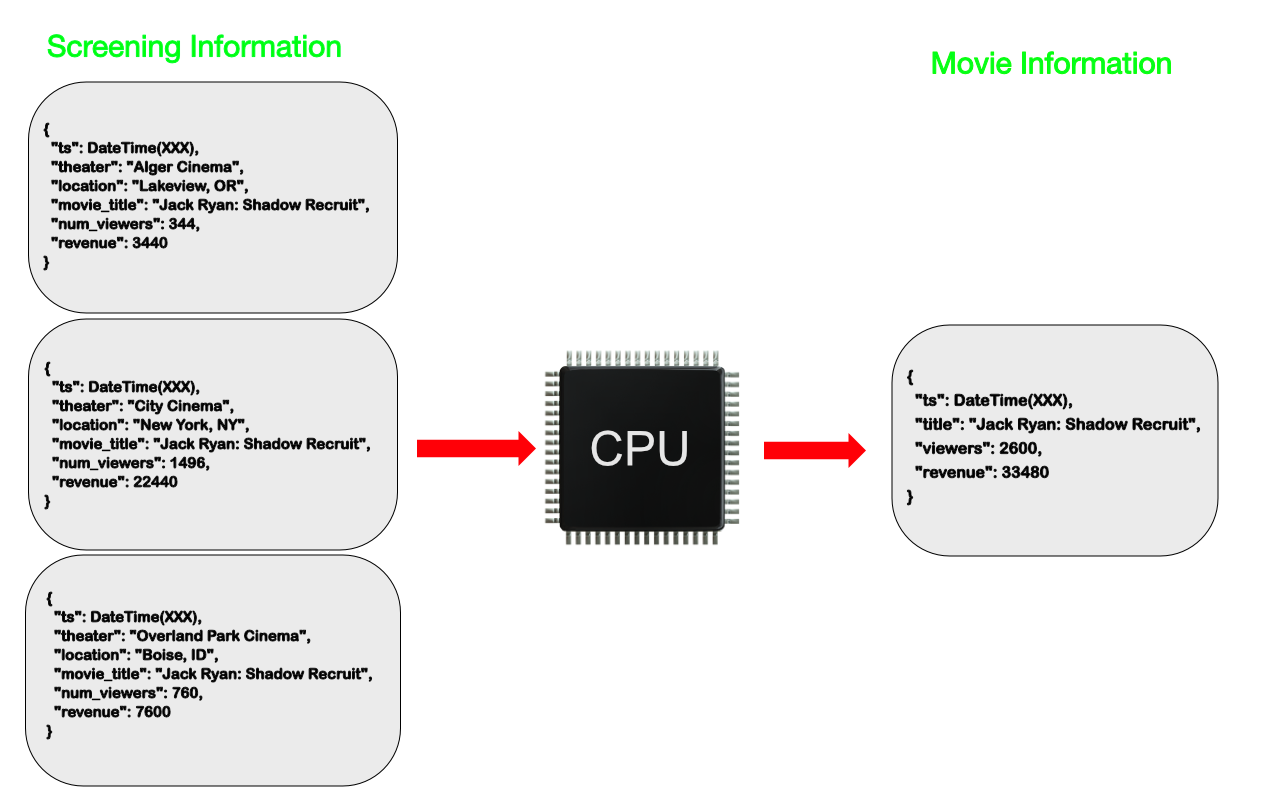
In our movie database example, we can do the computations based on all of the screening information we have on a particular movie, compute the result(s), and store them with the information about the movie itself. In a low write environment, the computation could be done in conjunction with any update of the source data. Where there are more regular writes, the computations could be done at defined intervals - every hour for example. Since we aren't interfering with the source data in the screening information, we can continue to rerun existing calculations or run new calculations at any point in time and know we will get correct results.
Other strategies for performing the computation could involve, for example, adding a timestamp to the document to indicate when it was last updated. The application can then determine when the computation needs to occur. Another option might be to have a queue of computations that need to be done. Selecting the update strategy is best left to the application developer.
Sample Use Case
The Computed Pattern can be utilized wherever calculations need to be run against data. Datasets that need sums, such as revenue or viewers, are a good example, but time series data, product catalogs, single view applications, and event sourcing are prime candidates for this pattern too.
This is a pattern that many customers have implemented. For example, a customer does massive aggregation queries on vehicle data and store the results for the server to show the info for the next few hours.
A publishing company compiles all kind of data to create ordered lists like the "100 Best ...". Those lists only need to be regenerated once in a while, while the underlying data may be updated at other times.
Conclusion
This powerful design pattern allows for a reduction in CPU workload and increased application performance. It can be utilized to apply a computation or operation on data in a collection and store the result in a document. This allows for the avoidance of the same computation being done repeatedly. Whenever your system is performing the same calculations repeatedly and you have a high read to write ratio, consider the Computed Pattern.
We're over a third of the way through this Building with Patterns series. Next time we'll look at the features and benefits of the Subset Pattern and how it can help with memory shortage issues. If you have questions, please leave comments below.
Previous Parts of Building with Patterns:
- The Polymorphic pattern
- The Attribute pattern
- The Bucket pattern
- The Outlier pattern