When inside an $expr, fields must have a $, so you should have $created_by.date rather than simply created_by.date. Because, created_by.date is simply a string rather an field path, I am not surprised that the index is not used. You are not querying a field. Here is some code that shows the differences:
What puzzle me however is when you write
It would be nice to see the exact pipeline you use and its explain plan in order to fully understand. One thing I could think is that since you do not call $substract you also removed the $expr and wrote the match as
Which will provide a valid result and be an IXSCAN.
Based on the observation that $$NOW is the culprit, here is a workaround that should leverage the creation_date index.
Rather than aggregating on the main collection you start with:
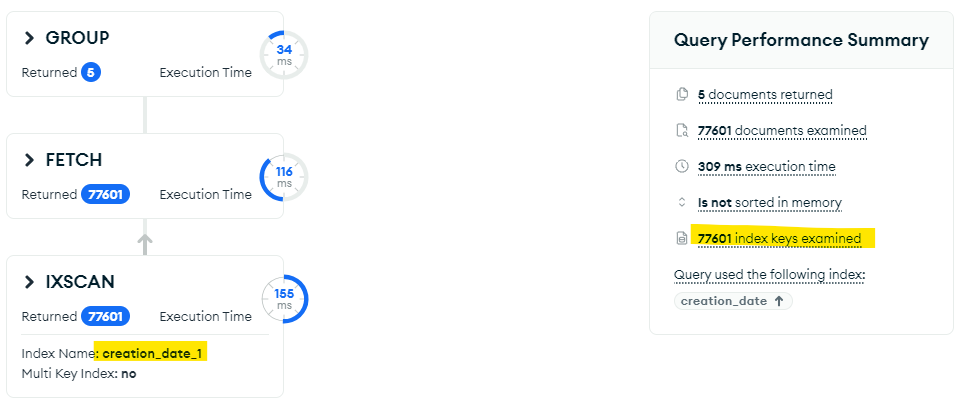
I could not verify that the $match uses the index, mostly because I get a the error Expected 'aggregate' to be string, but got int32 instead. when I do db.aggregate(…).explain. But by storing now_minus_delta in a temporary collection and aggregate on the temp. collection I got the following explain for the $lookup
I might be worth trying this workaround on your dataset until the jira is resolved.
Thanks @steevej , it works well, besides the explain does not show the use of the creation_date index. But the usage’s count of this index increases, and I got an instant result : so, clearly, this pipeline is a good trick!
rewrite your pipeline from the workaround collection, with this stages
** stage 1 : $match to target your duration (4d? 1h?)
** stage 2 : $project to calculate your threashold date from $subtract and $$NOW
** stage 3 : $lookup to build a _tmp array, from stage 2 and the main collection. Use your original pipeline as a sub-pipeline in this stage
** stage 4 : $unwind items in the _tmp array
** stage 5 : $project to print the attended result