We are facing an issue with MongoDB sharding setup(5.0.8 and community edition) and two shards are in place with PSA architecture(Primary on one server, Secondary+Arbiter point to another one) and config servers too in the same model. Weekly Collections are generated automatically based on a pipleline execution of extracting data from external sources and later shard key will be imposed on top of the collection and thereafter subsequent extractions will make the data distribute across two shards. Below is the output of two big collections.
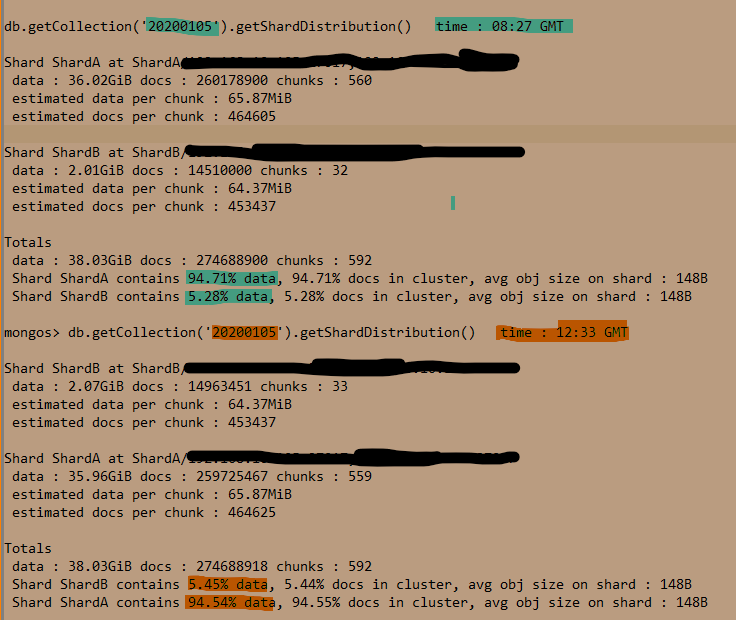
mongos> db.getCollection('20230209').getShardDistribution() ----
Shard ShardA at ShardA/1xx.1xx.xx.77x:27017,1xx.1xx.xx.78x:27017
data : 49.51GiB docs : 330654921 chunks : 395
estimated data per chunk : 128.35MiB
estimated docs per chunk : 837101
Shard ShardB at ShardB/1xx.1xx.xx.1xx:27017,1xx.1xx.xx.1xx:27017
data : 24.76GiB docs : 165255242 chunks : 394
estimated data per chunk : 64.36MiB
estimated docs per chunk : 419429
Totals
data : 74.27GiB docs : 495910163 chunks : 789
Shard ShardA contains 66.65% data, 66.67% docs in cluster, avg obj size on shard : 160B
Shard ShardB contains 33.34% data, 33.32% docs in cluster, avg obj size on shard : 160B
Collection Metrics:
Name of the collection is 20230209
Count of documents : 495910163 ( overall )
Shard A count : 330654921
Shard B count : 165255242
Database name : “INDIA_SPIRIT”, “primary” : “ShardA”
Can someone help us on this…? Also, Initial data extracted before shard key is imposed will remain under Primary Shard or will also gets distributed, post sharding the collection…?
I did not understand the question clearly, are you asking:
what happens when you shard an existing collection (will it spread across the cluster by the balancer)?
In case you want to shard an existing collection data, it can only be sharded if its size does not exceed specific limits. These limits can be estimated based on the average size of all shard key values, and the configured chunk size. For more details please check Sharding Existing Collection Data Size. In case it lies within the limit then the data of sharded collection will be divided into chunks and moved to different shards until the collection is balanced.
what happens to data that is not in the collection that is sharded (will non-sharded collection stay on the primary shard)?
A database can have a mixture of sharded and unsharded collections. Sharded collections are partitioned and distributed across the shards in the cluster. Unsharded collections are stored on a primary shard. Each database has its own primary shard. Here, collection 1 represents sharded collection and collection 2 represents unsharded collection.
Additionaly, how evenly the data distribution happens is mainly determined by the shard key (and the number of shards).
In your case, It looks like both the shards have similar number of chunks (ShardA: 395 & ShardB: 394) but estimated data per chunk in ShardA is double in comparison to ShardB. So to check the un-even data distribution across your shards we need to make sure of some details, such as:
Note: Starting in MongoDB 6.0.3, data in sharded clusters is distributed based on data size rather than number of chunks, so if balancing based on data size is your ultimate goal, I recommend you to check out MongoDB 6.0.3 or newer. For details, see Balancing Policy Changes.
Many thanks for the reply, dear Tarun. Attached is the db.printShardingStatus output for your reference and suggesting any…? Also as your mentioned “estimated data per chunk in ShardA is double in comparison to ShardB” - Any remedies like resharding the key or moving the shard from one to another works any…?
Most databases have primary as ShardB for unsharded collections, and sharded databases have a even distribution in terms of number of chunks.
Since in this version sharding rule is based on number of chunks, from mongo’s view point, this is being “evenly” sharded.
So i’m guessing your shard key doesn’t provide an even distribution. (e.g. it has 2/3 chance to sit in shardA and 1/3 for shardB). As a result, though # of chunks are same, data size is different.
hello, is my understanding like “does shardA default chunk size is 128 MB and ShardB default chunk size is 64MB” and due to this mismatch, estimated data per chunk varies and hence the uneven distribution any…? Also, read somewhere like due to high number of deletions across the collections ( within the bound ranges) will generate empty chunks …? True any… can someone clarify on this…?
Do we have any query/command that can be run inside mongos or on a Shard node for getting the list of unsharded collections against a database…? I’d used coll.stats, but it is showing at the collection level and inside the database, we have multiple collections… Can somebody provide some pointers…? Thanks in Advance… Kesav
We have nearly 150 collections ( average sized at 25 to 30 GB) residing on ShardA and due to this disk space consumption is more, when compared with Shard B. We have a collection(s) created as a part of application pipeline flow, where data will be loaded initially into the ShardA ( without shard key) and then shard key ( range based shard key) will be created, which will make the data distribute across shard A and B.
Attached is the output of sharding distribution, where upon sharding the unsharded collections, chunk migration is happening, but going very slow. Any specific reasons for this…? Target : Get all the newlyy sharded collections distribute data equally and release the disk space at the ShardA servers side.