Thanks @Benjamin_Flast, for getting back. I have done some implementation over my collection. Let me explain
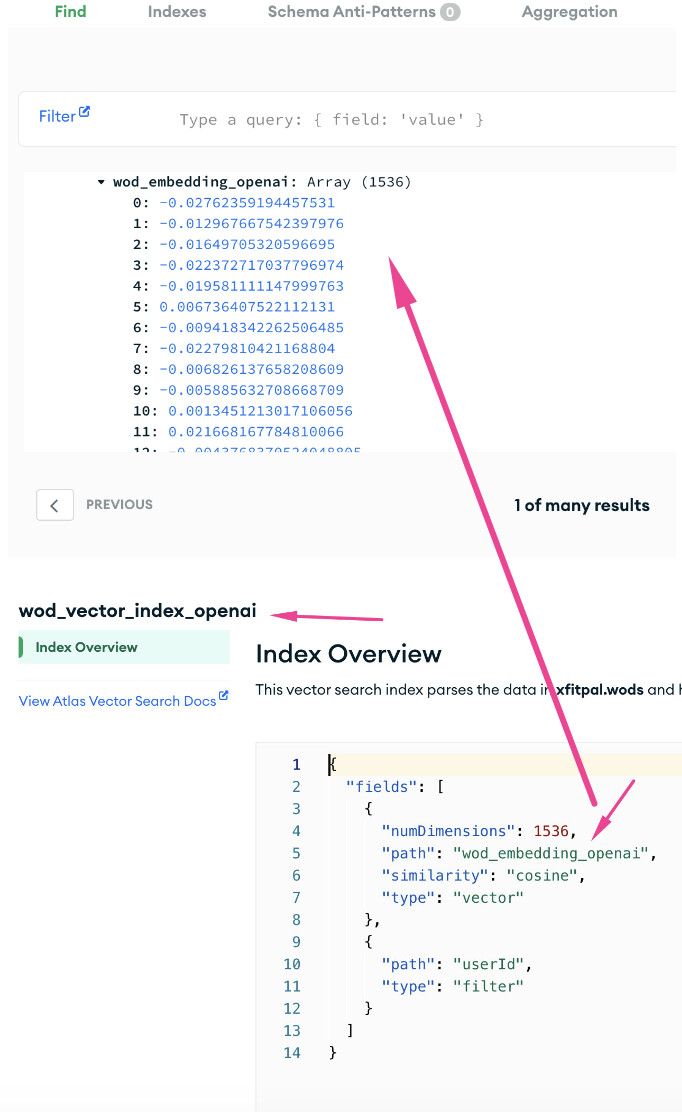
I am storing my embedding in my collection named businessembeddings. I did check the db and embeddings got created fine. the filed where embeddings are stored is named embeddings.
And I created an index:
{
"fields": [
{
"numDimensions": 1536,
"path": "embeddings",
"similarity": "euclidean",
"type": "vector"
},
{
"path": "businessAccount",
"type": "filter"
},
{
"path": "_id",
"type": "filter"
}
]
}
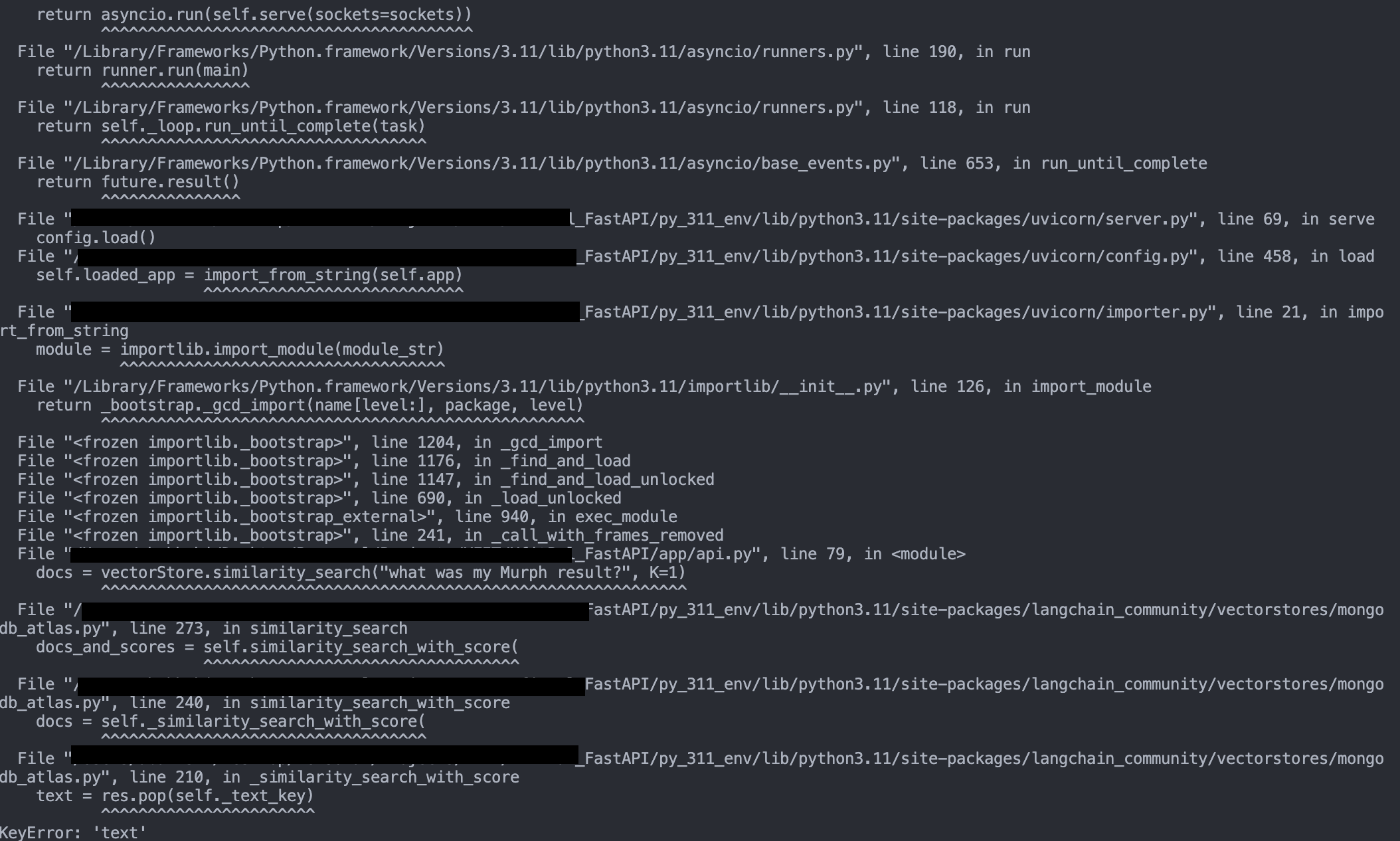
And now when I try to retrive using that index I get the error:
Code:
export const asRetriever = (apiKey: string, options: { indexName: string, collectionName: string }) => {
const mongoClient = connection.getClient()
const collection = mongoClient.db(dbName).collection(options.collectionName)
const embeddings = new OpenAIEmbeddings({ openAIApiKey: apiKey })
const vectorStore = new MongoDBAtlasVectorSearch(embeddings, { collection, indexName: options.indexName })
return vectorStore.asRetriever()
}
const retriever = asRetriever(RAGConfig.openApiKey, {
indexName: "product_index",
collectionName: "businessproducts"
})
const llm = new OpenAI({ openAIApiKey: RAGConfig.openApiKey, temperature: 0 })
const qa = RetrievalQAChain.fromLLM(llm, retriever)
return await qa.run(query)
MongoServerError: PlanExecutor error during aggregation :: caused by :: embedding is not indexed as knnVectorMongoServerError: PlanExecutor error during aggregation :: caused by :: embedding is not indexed as knnVector
I also tried the following index and got the same error
{
"mappings": {
"dynamic": false,
"fields": {
"embeddings": {
"dimensions": 1536,
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
FYI, not all documents in my collection has embeddings, as am yet to run a migration over old data. Could this be an issue ?
Can you help?