Hi All,
I am new to Atlas MongoDB and I have recently created an account with a cluster and some data on it in collections. I am kind of developing a llamaIndex question-retrieval sample app and I plan to query the data directly from MongoDB. Since I am new to MongoDB I am finding some hard time to complete the required info for the host and port. Is there a way to provide some screenshots from an existing account where I could see where to take these values? The llamaIndex mongo loader as follows:
from llama_index import download_loader
import os
SimpleMongoReader = download_loader('SimpleMongoReader')
host = "<host>"
port = "<port>"
db_name = "<db_name>"
collection_name = "<collection_name>"
# query_dict is passed into db.collection.find()
query_dict = {}
reader = SimpleMongoReader(host, port)
documents = reader.load_data(db_name, collection_name, query_dict=query_dict)
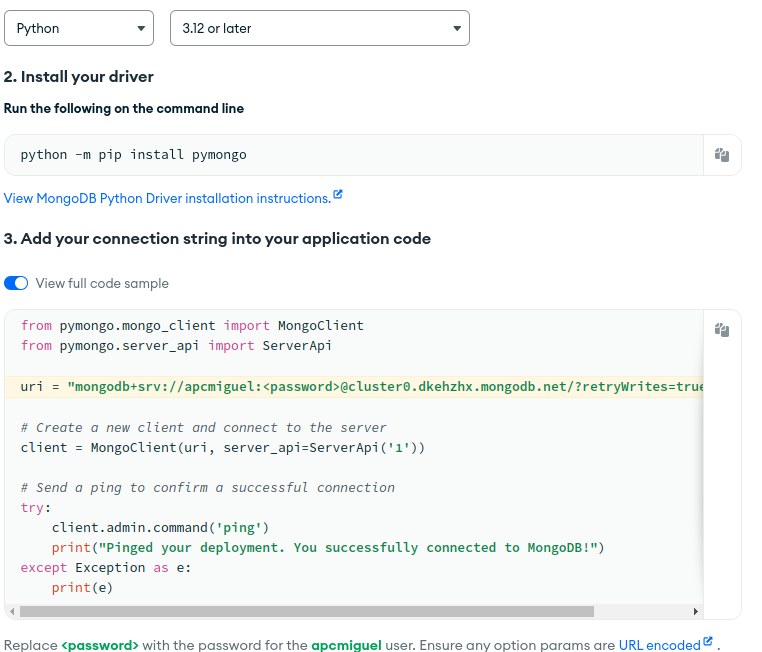
All the connection info you need is available in your database deployment.
Click at the “connect” button, then in the next screen you select “Drivers” in “Connect to your application”, next you select “python” in the driver box and you should see how your connection string has to look like.
Many thanks for your response. I followed your instructions and accessed. Could you please indicate from the connection string where to find the Host and the Port? I am still blind and unable to grasp it.
There are 2 options to use mongo loader - 1) Use rhe ‘host’ & ‘port’ (more relevant for self-hosted mongoDB) , or 2) specify the uri field directly (more relevant for atlas)
In your case please use the URI as it shows up on Atlas
Would love to know more about what you are building
Thanks for the reply, very useful here for the time being. Just to provide some background on the work I am kind of building here, it uses under the hood the paper that You and Liu published on medium along with the notebook. Essentially, what I am trying to come around here is the deployment phase on streamlit of the vector_response based on the query/question. I’ve planned a dedicated section where we solely upload each/multiple files directly to MongoDB without any execution, after that, we can route our queries at each specific dedicated MONGODB_DATABASE on the persisted documents stored at each database within the cluster. I think of in that way (I am not familiar with the gears under the speed process of the index) we could direct each query to the specific database and take less effort and more speed response to the client. Two calls here, 1. to upload files related to the nature of each database and 2. route the query to the specific database and force the vector_response to be bounded in indexing only on the docs stored under that specific database (not sure if it is possible though).
The problem I am facing is talking with the database directly from MongoDB using host, port, collections, and like. Appreciate if you could indicate the best way to share the line code to get further support from your side whenever possible. I am really stuck here.