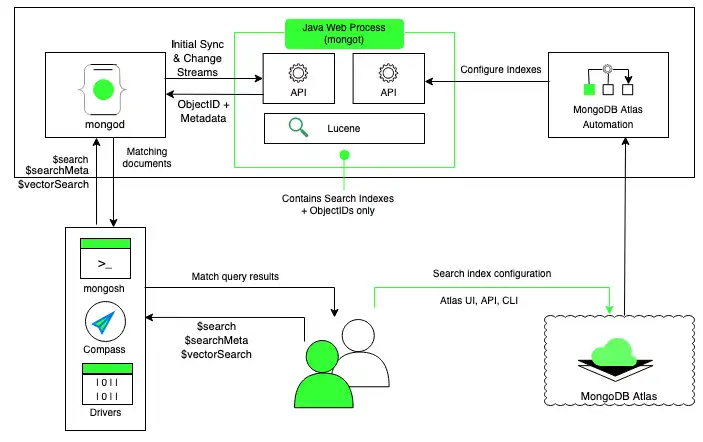
I want to read the fully replicated data using the atlas search aggregation pipeline. But, Atlas search is not allowing me to read with concern “majority”.
Command aggregate does not support { readConcern: { level: "majority", provenance: "clientSupplied" } } :: caused by :: Aggregation stage $search cannot run with a readConcern other than 'local'. Current readConcern: majority'.
So, How can we ensure the consistency in the search result?
I’ve read the documentation and understood that the $search stage is performed by the mongot service and it won’t work with non-local read concern. I don’t know why and how can MongoDB guarantee the consistency in search results.
My Cluster Architecture Details:
- Cluster tier : Dedicated M10
- Node Type : electable
- cluster : 3 node replicaSet
- Mongodb version : 7.0.14
- pymongo : 4.10.1
- writeConcern : majority
- readConcern : majority
- read preference : secondary
I have not enabled workload-isolation; So,mongot and mongod services are running in each nodes of the replicaSet cluster.