Our goal is to push rows from our Databricks cluster into Mongo Atlas so we can use mongo as a serving layer. We just want to take one table and upsert any changes into a mongo collection. Fyi: We do use a lot of structs and array.
We’ve tried all of the examples from the mongo documentation (https://www.mongodb.com/docs/spark-connector/current/ ) and none of it has worked due to version compatibility issues. I could post all of the code that we’ve tried but it all came verbatim from the mongo docs.
We are running Databricks 14.1 because we need some of the preview features that they have released in the past year. Our Databricks cluster is setup as Databricks 14.1 (includes Apache Spark 3.5.0, Scala 2.12) . There isn’t any way for us to use an earlier version of Spark.
We have it setup to install this connector library on startup: org.mongodb.spark:mongo-spark-connector_2.12:10.2.1
We have all of the firewall and authentication issues solved. We can successfully connect to mongo from a databricks notebook but we can’t do anything with data. The only call that we’ve been able to get working is df.printSchema(). And that does successfully talk to spark and bring back the document schema.
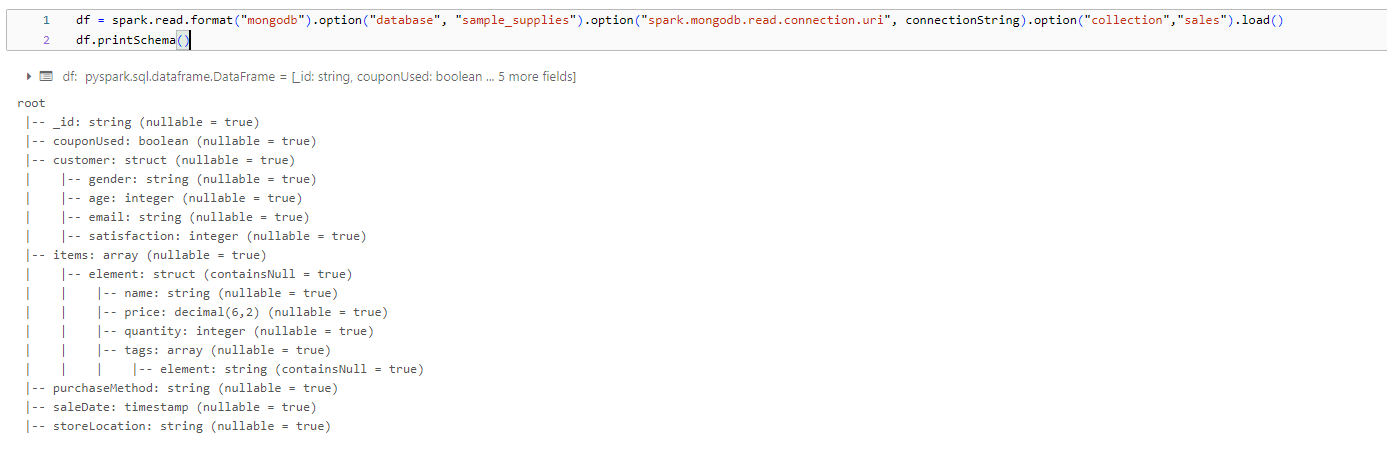
Any attempt to read or write document content fails.
Read attempt:
df = spark.read.format("mongodb").option("database", "sample_supplies").option("spark.mongodb.read.connection.uri", connectionString).option("collection","sales").load()
display(df)
java.lang.NoClassDefFoundError: Could not initialize class com.mongodb.spark.sql.connector.read.MongoScanBuilder
Write attempt:
dataFrame = spark.createDataFrame([("Bilbo Baggins", 50), ("Gandalf", 1000), ("Thorin", 195), ("Balin", 178), ("Kili", 77),
("Dwalin", 169), ("Oin", 167), ("Gloin", 158), ("Fili", 82), ("Bombur", None)], ["name", "age"])
dataFrame.write.format("mongodb").mode("append").option("spark.mongodb.write.connection.uri", connectionString).option("database", "people").option("collection", "contacts").save()
org.apache.spark.SparkException: Writing job failed.
Job aborted due to stage failure: Task 1 in stage 9.0 failed 4 times, most recent failure: Lost task 1.3 in stage 9.0 (TID 90) (10.139.64.11 executor 0): java.lang.NoSuchMethodError: org.apache.spark.sql.catalyst.encoders.RowEncoder$.apply(Lorg/apache/spark/sql/types/StructType;)Lorg/apache/spark/sql/catalyst/encoders/ExpressionEncoder;
at com.mongodb.spark.sql.connector.schema.InternalRowToRowFunction.<init>(InternalRowToRowFunction.java:44)
at com.mongodb.spark.sql.connector.schema.RowToBsonDocumentConverter.<init>(RowToBsonDocumentConverter.java:84)
at com.mongodb.spark.sql.connector.write.MongoDataWriter.<init>(MongoDataWriter.java:74)
at com.mongodb.spark.sql.connector.write.MongoDataWriterFactory.createWriter(MongoDataWriterFactory.java:53)
I saw a jira ticket (SPARK-413) and a PR for the issues with InternalRowToRowFunction but it wasn’t clear if that was a very specific point fix or if all read and write operations will be working after the next connector update.
Is there any ETA on when the Spark Connector will be working with Spark 3.5?
I also found this post on Medium where someone forked the connector and fixed some of the issues. I wasn’t sure if this would be helpful to the devs. Enhanced MongoDB Connector for Spark 3.5 | by Kürşat Kurt | xWorks Technology Blog
I would include more screenshots and links but as a new user the forum is only allowing one link and one image.