I am using mongodb locally and standalone. There is only one collection in my database which contains around 32 millions documents. In my use case, almost half of these documents would be updated several times.
I have a aggregate pipeline that will count the documents.
db.collection.aggregate([ { $match: { column1: "...", column1: "..." }},{ $count: "count" }],{hint:"column1_1_column2_1"})
and do have an index built according those two column.
And then I have another collection which I use mongodump and mongorestore to duplicate the original collection.
As my expectation, this aggregate pipeline works evenly efficiently to these two collection.
However, when I change my aggregation pipeline to
db.collections.aggregate([ { $match: { column1: "...", column1: "...", "column3: "..." }},{ $count: "count" }],{hint:"column1_1_column2_1"})
The pipeline of original collection becomes very slow.
When I use explain , it seems that the seek stage between these two collections differ a lot.
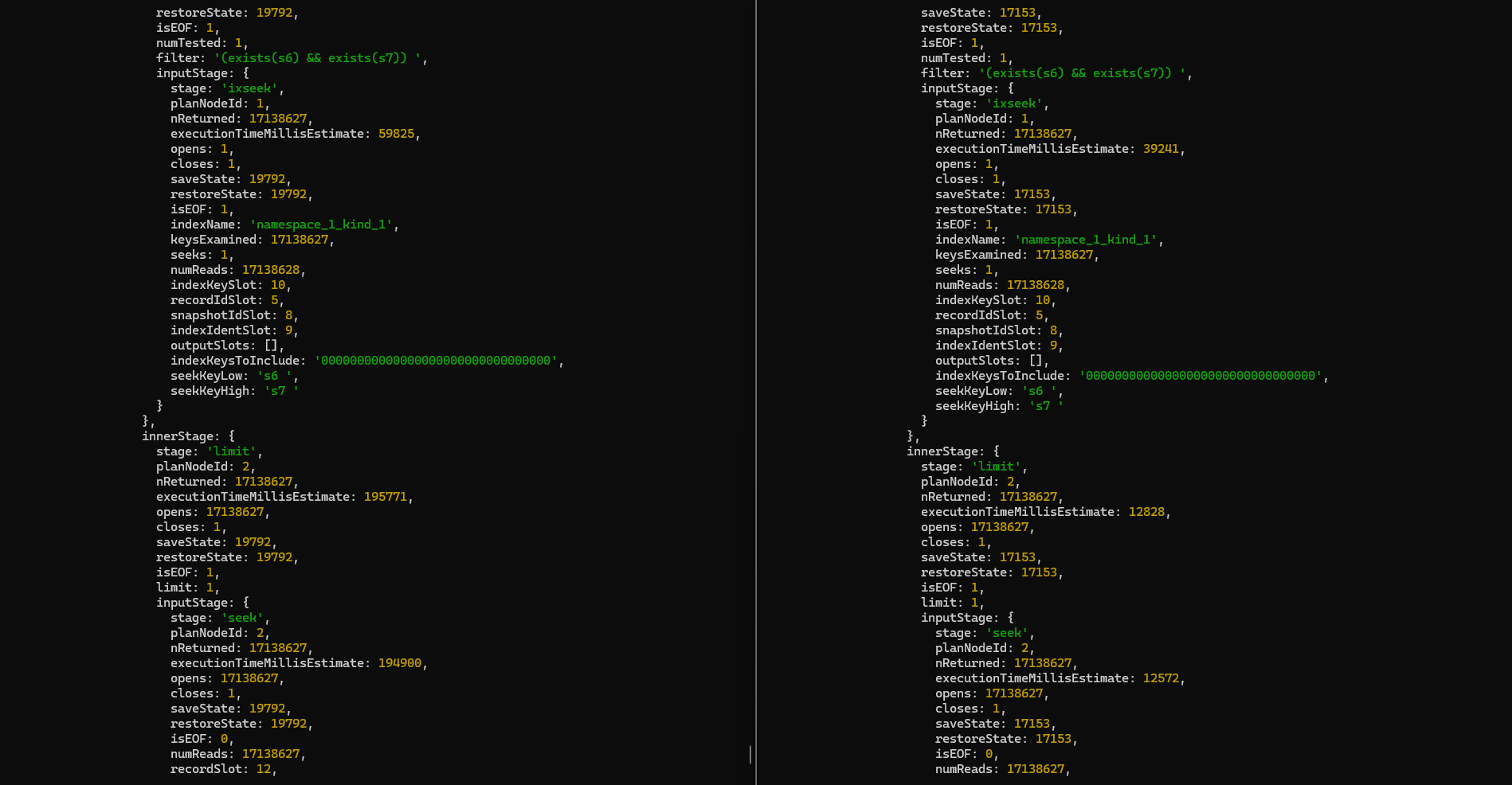
On the left side, it is the screenshot of slow original db. The other side is that of duplicated db.
How could it be? How should I do to make the original db fast without any downtime? What 's the root cause that makes it so slowly?
The methods I have tried:
compact rebuild index
version:
7.0