I have a mongo collection where i want to apply an aggregation on it that includes matching, ordering and sorting.
I have around 10 million records and i am testing on my local environment using Mongo bd compass.
My issue is that my query is taking around 7 seconds of execution when i need it to be less then 2 seconds.
This is an example object from my collection
_id
6627c4314c11d4072fef0c37
manager_id
4
client_id
1058
agent_id
1924
source
"home_page"
property_id
292498
property_reference
"054"
property_personal_reference
"054"
property_category_id
2
property_type_id
1
property_price_type_id
4
property_price
1500
property_community_id
969
property_district_id
28
property_province_id
2
property_bedroom_id
3
property_bathroom_id
4
property_area
160
property_boosted
false
property_listing_level
"standard"
created_at
2023-09-11T15:45:56.000+00:00
`
And this is my aggregation
[
{
$match: {
manager_id: 4,
created_at: {
$gte: ISODate(‘2022-08-11’),
$lte: ISODate(‘2023-08-25’)
}
},
},
{
$group: {
_id: {
property_id: ‘$property_id’,
client_id: ‘$client_id’,
agent_id: ‘$agent_id’,
},
impressions_count: {
$sum: 1
},
property_category_id: {
$first: ‘$property_category_id’
},
property_community_id: {
$first: ‘$property_community_id’
},
property_district_id: {
$first: ‘$property_district_id’
},
property_province_id: {
$first: ‘$property_province_id’
}
},
},
{
$project: {
_id: 0,
property_id: ‘$_id.property_id’,
client_id: ‘$_id.client_id’,
agent_id: ‘$_id.agent_id’,
impressions_count: 1,
property_category_id: 1,
property_community_id: 1,
property_district_id: 1,
property_province_id: 1
}
},
{
$sort: {
impressions_count: 1,
property_id: 1,
}
},
{
$limit: 10
}
]
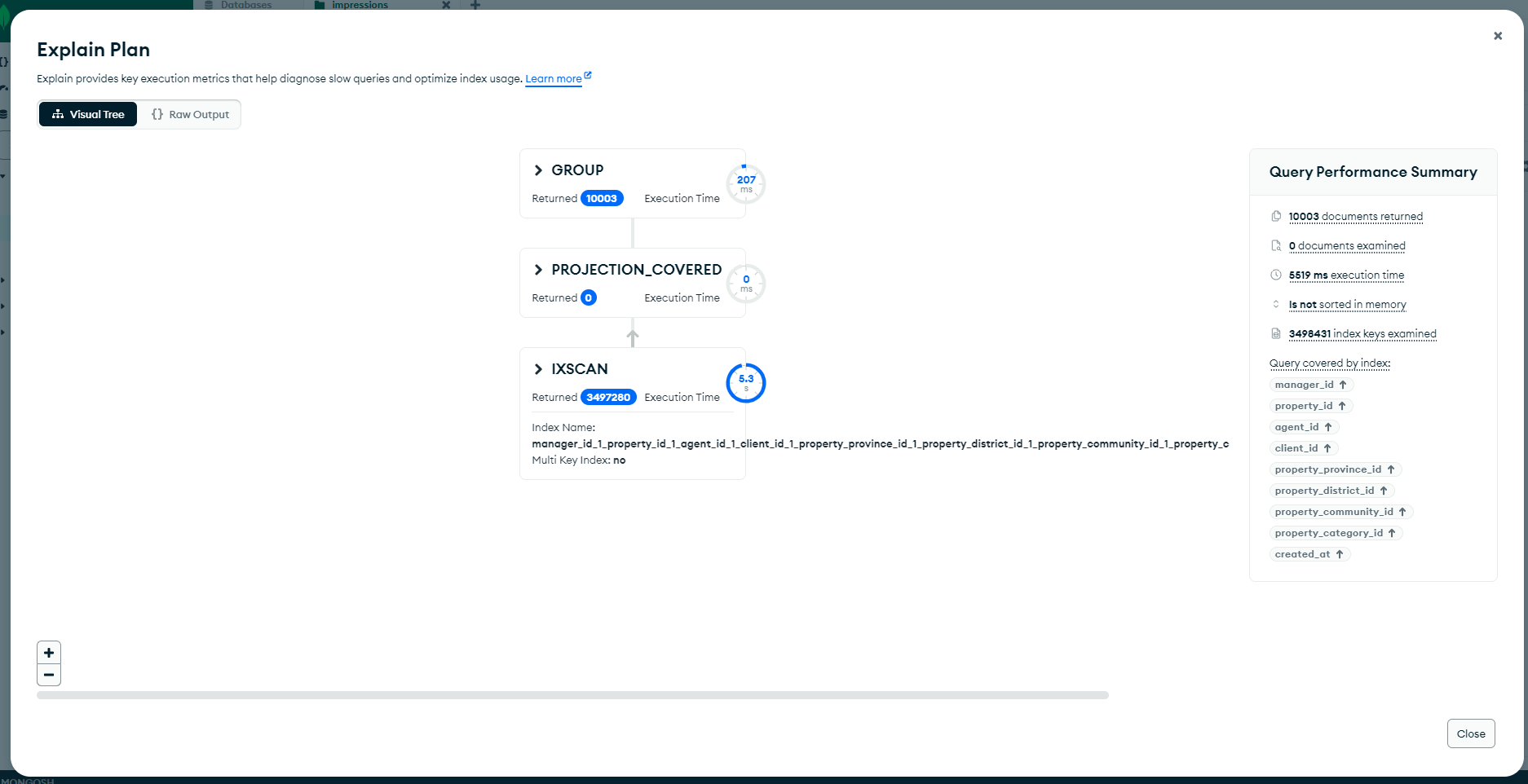
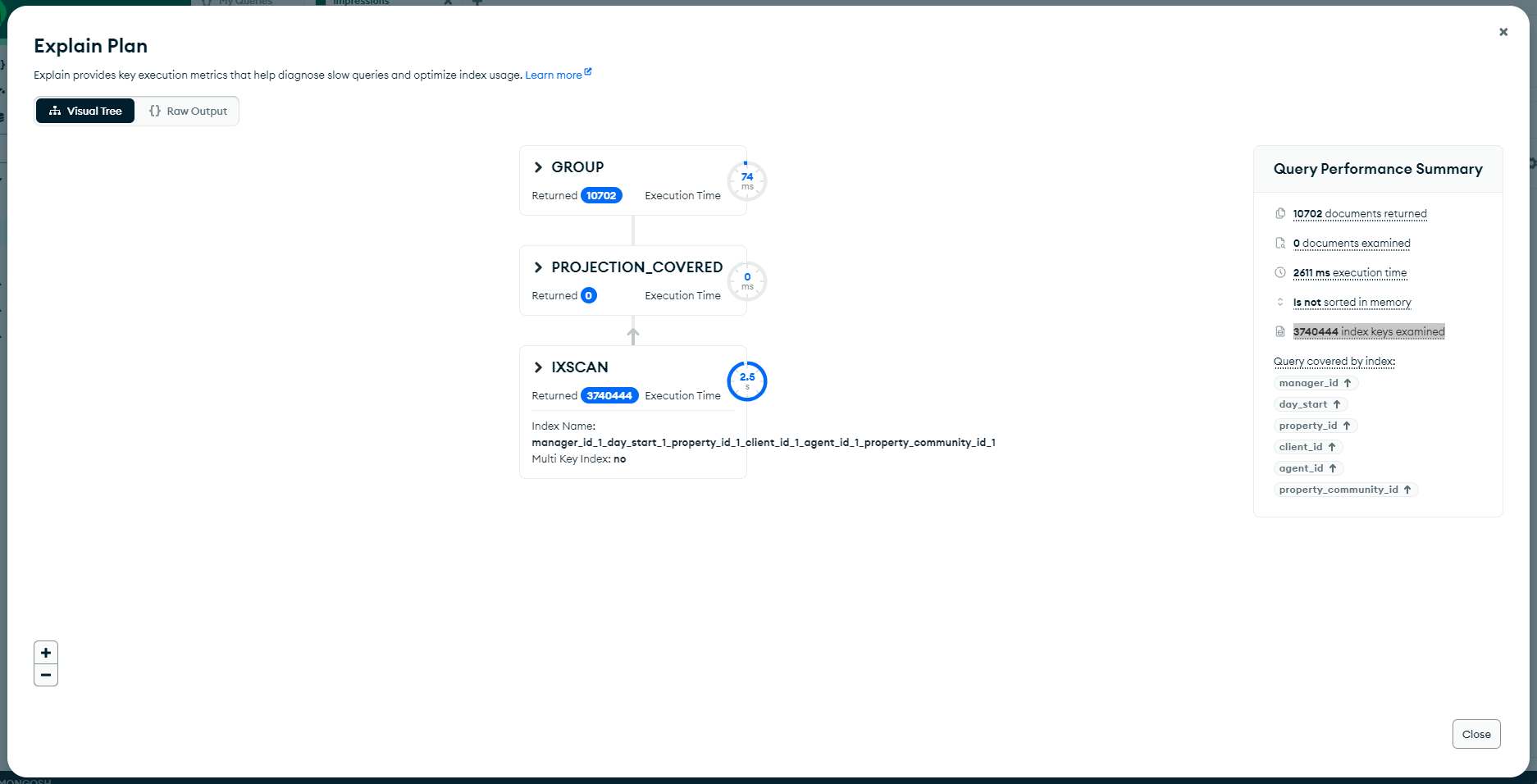
i've created an index to cover this query and it is actualy covering the query. this is the explain result of the query

I need help please !!!!!