Brief description:
When using timeseries-collections, there comes a point when new buckets are created non-optimally and contain only 1 document ( but if you initiate inserting of such collection on mongo without load ( e.g. just after start ), documents with same metadata will be grouped to one bucket ).
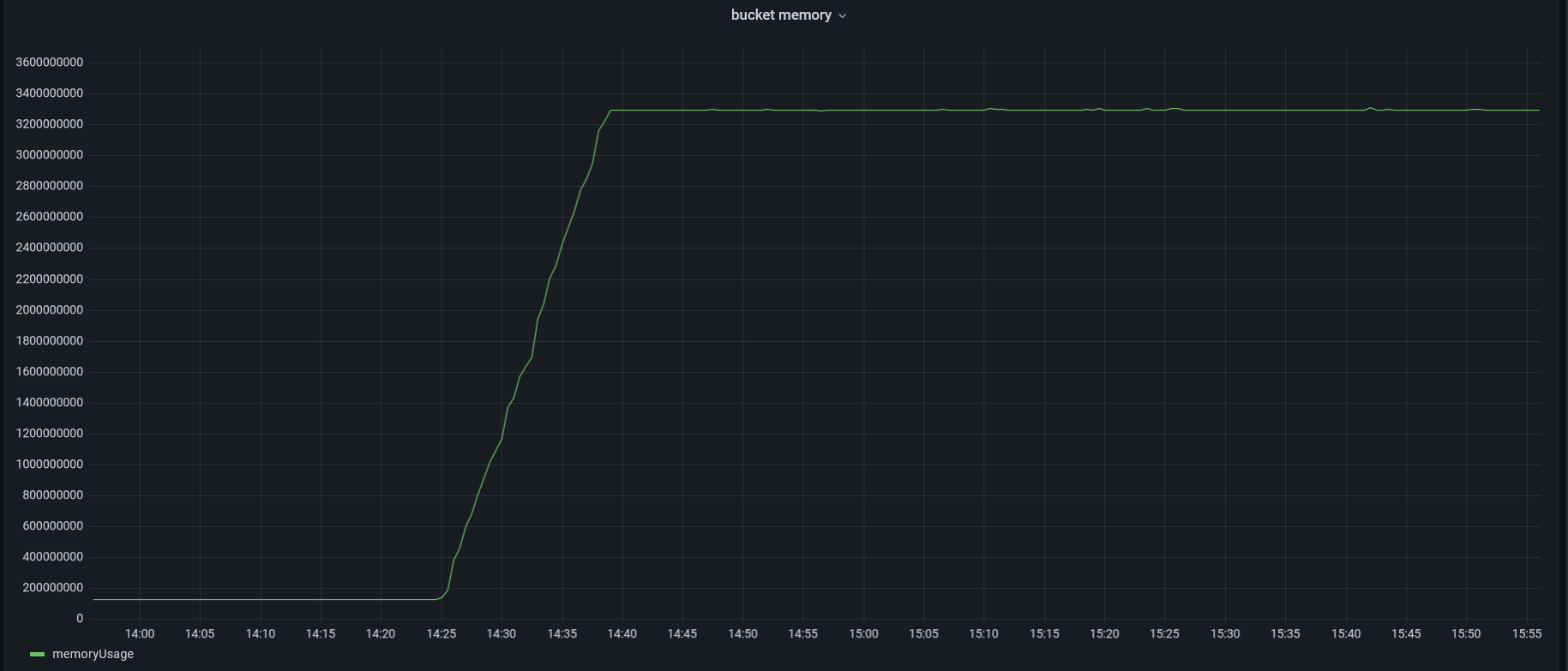
Server parameters: 128 GB RAM, memory usage during the experiment does not exceed 80 GB.
Mongo settings: all default ( WiredTiger Cache : 50% RAM, timeseriesIdleBucketExpiryMemoryUsageThreshold set to 3 GB). Pymongo driver is used.
Experiment Description:
Loading is performed into several collections (50 in total).
The general schema of collections provided below (collections are created with the parameter bucketMaxSpanSeconds": 31536000, date is rounded to day ):
# Type 1:
{"metadata": {"id_1": "string", "id_2": "string"},
"date": "Date", "d_0": "int", "d_i": "int", "d_2": "int"}
# 500_000 unique pairs of ("id_1", "id_2"), avg 15 records in month for id pair, 12 months
# Type 2: # more measurement values, 20 instead of 2 - one record size is larger
{"metadata": {"id_1": "string", "id_2": "string"},
"date": "Date", "d_0": "int", "d_i": "int", "d_i": "int", ... , "d_N": "int"} # N = 20
# 25_000 unique pairs ("id_1", "id_2"), avg 15 records in month for id pair, 12 months
Load testing: during the load testing 50 collections are created, after that data in them is inserted by chunks ( chunk contains all dates from specific month for set of id_pairs ), starting with one month, then proceeding to the entire following month, and so on. Operations across different collections are interleaved. Dates within each chunk are sorted. Chunks of specific collection also inserted in time-order.
Issue:
If a new collection is created and a Type 2 collection chunk inserted at the beginning of the load testing ( or before it ), the collstats results are: {'timeseries.bucketCount': 25,000, 'avgNumMeasurementsPerCommit': 17}.
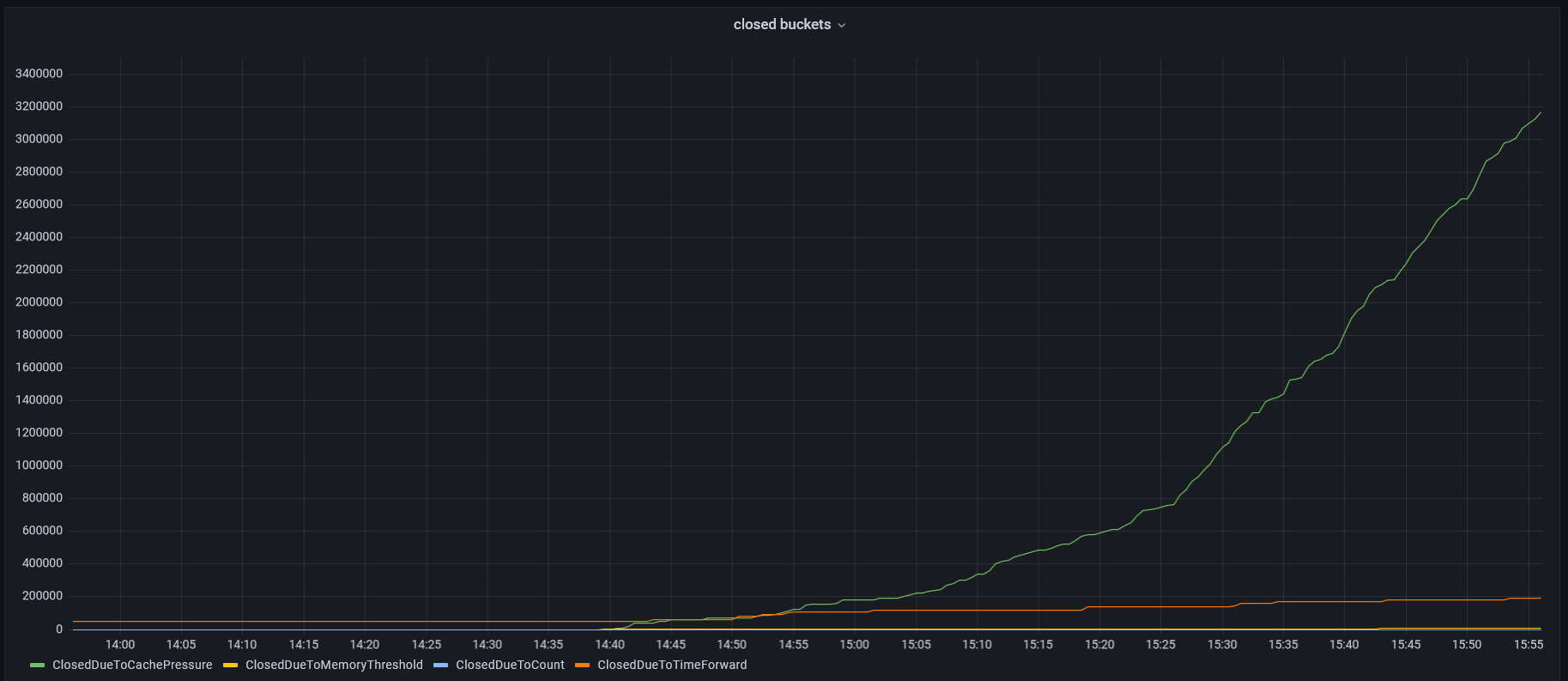
However, if a new collection is created and a Type 2 collection chunk is loaded after loading has been performed in other collections ( during load testing ), the collstats results are vastly different: {'timeseries.bucketCount': 420,000 # (slightly less than the number of elements in the chunk), 'avgNumMeasurementsPerCommit': 1, numBucketsClosedDueToCachePressure: 415,000}. This means that records with the same id pair were not merged, resulting in buckets with a size of 1.
As a result, buckets with a size of 1 are created, although without loading they were of size 17 (for a single chunk) and 200 (for all inserted months). Consequently, the collection begins to occupy significantly more space ( at least 3 times more ) compared to the same collection loaded without any system stress. So bucket effective size optimization seems to create even more load.
Possible reasons:
As far as I understand, when adding a new document, there is a check for the ability to add it to an already opened bucket in the catalog ( check by time, the number of measurements, and so on ). One of the checks involves comparing the size after a potential addition of a new document to the bucket with the effective maximum size of the bucket: bucket.size + sizeToBeAdded > effectiveMaxSize.
# bucket_catalog_internal.cpp, determineRolloverAction function
auto bucketMaxSize = getCacheDerivedBucketMaxSize(opCtx->getServiceContext()->getStorageEngine(),
catalog.numberOfActiveBuckets.load()); # bucketMaxSize = storageCacheSize / (2 * numberOfActiveBuckets)
int32_t effectiveMaxSize = std::min(gTimeseriesBucketMaxSize, bucketMaxSize);
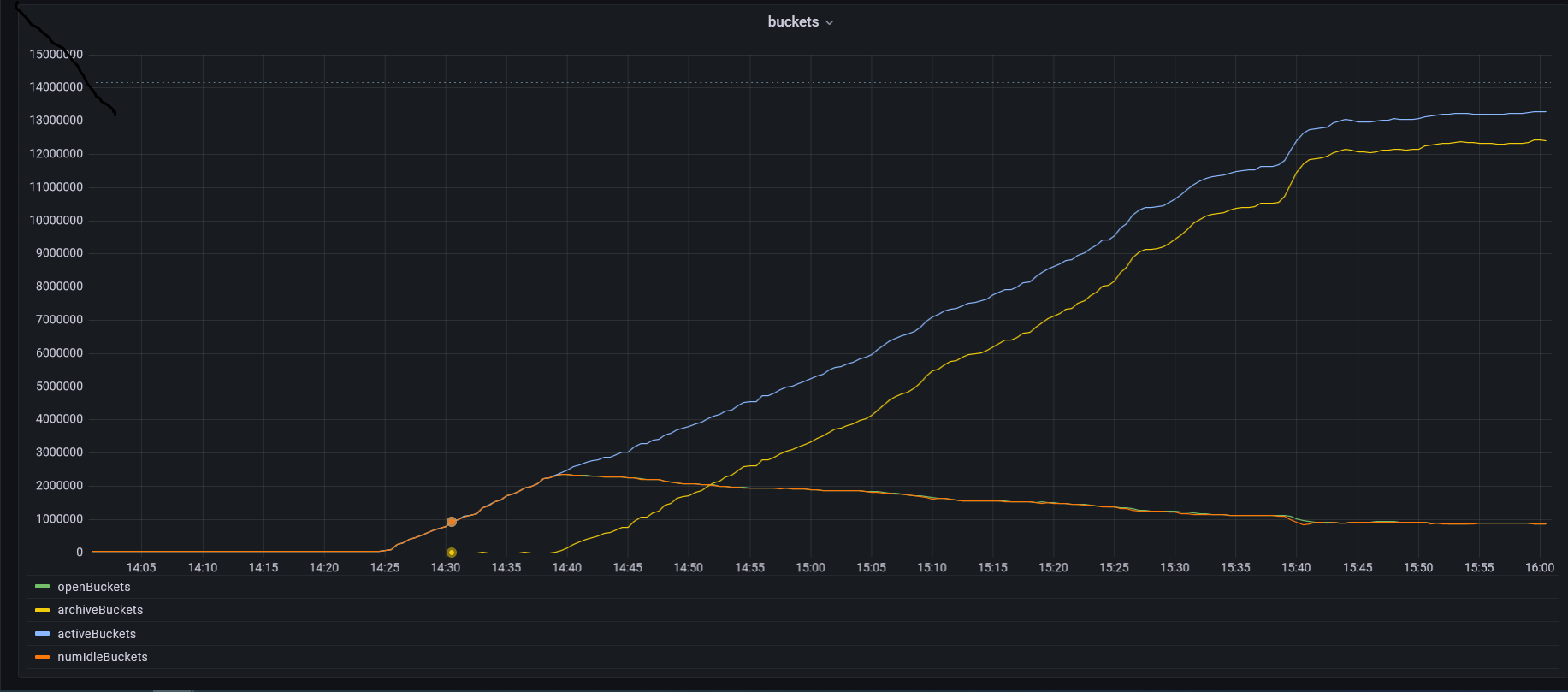
The effective size of the bucket, in turn, depends on bucketMaxSize. bucketMaxSize becomes smaller with more active buckets. With time it becomes comparable to the size of one record.
The graphs showing the changes in the number of buckets and memory during load testing are presented below. Generated based on the statistics from db.runCommand({ serverStatus: 1 }).bucketCatalog.
Questions:
- Is this behavior expected, or is it some kind of a bug (for example,
numberOfActiveBucketsshould be used instead ofnumberOfOpenedBucketsor there should be a bottom limit:gTimeseriesBucketMinSize- which is defined but not used )? - Is there anything that can be done about this, or our use case just not suitable for timeseries-collections?
- Is the assumption about the cause of the problem accurate or I misunderstanding what’s going on?