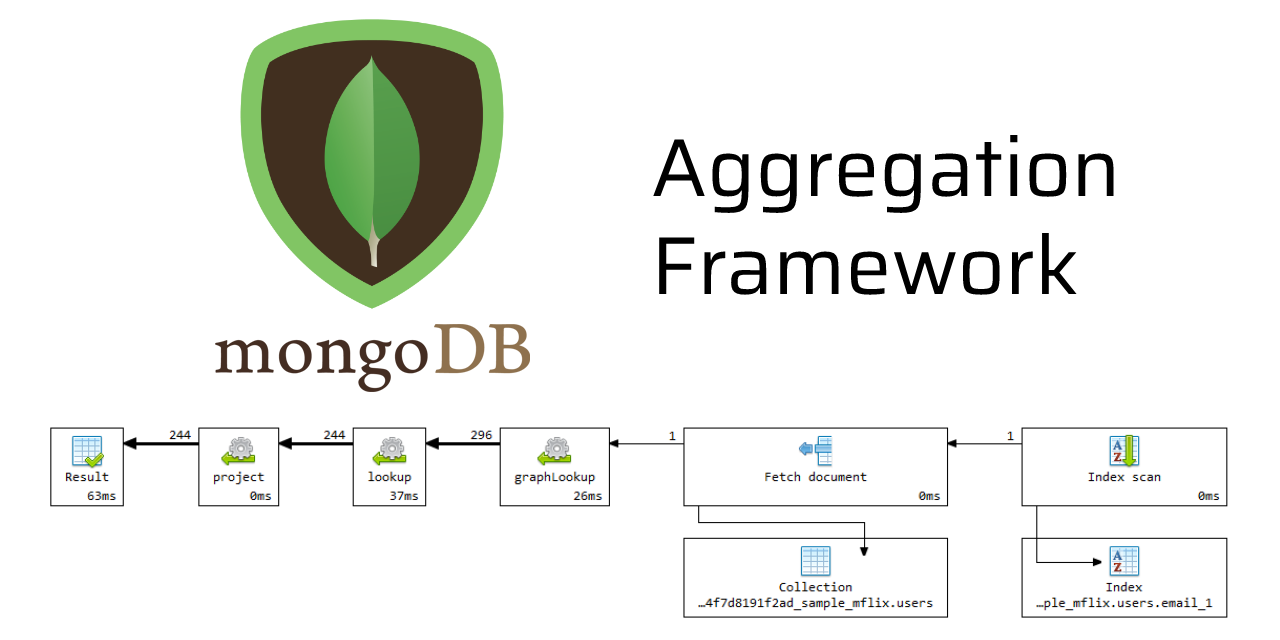
The complex usage of the MongoDB aggregation framework to retrieve documents from multiple collections using an aggregation pipeline query that will perform much faster than the existing functional Map-reduce models.
Run Database query with one-go
The database transaction to retrieve a large number of records in a single query is a daunting task. The millions of documents stored in the database have complex relationships with data nodes that require seamless flow with the software application service.
The data node defines the business data processing workloads to perform an intensive task in real-time. The business software applications ( Stock Market, Disaster Management, Cryptocurrency marketplace, Bitcoin mining, Census dashboard ) require in-flight analytical data with a single database query to retrieve grouped data and a faster business transaction timeline.
Techniques to handle large datasets
MongoDB provides data processing functions to analyze large datasets and produce the final aggregated results. The MapReduce and Aggregation pipeline are two ways of aggregating, grouping, filtering data nodes in MongoDB with several functional stages.
What is Map-Reduce?
Map-Reduce is a javascript functional model to map documents with emit key-value pair-based functions that pass value to the reduce function to perform the aggregation of the data node that returns the output to the client.
Structure of Map-Reduce in MongoDB
MongoDB uses the “ mapReduce ” database command for a collection to apply the aggregation query. The mapReduce function facilitates writing key-value pair objects in the map() function and computational logic in reduce() function to finalize the result.
Why Map-Reduce much slower in query performance?
A sequence of tasks during the process
The map-reduce function uses JavaScript that runs in a single-thread Spider Monkey engine. The map-reduce operation involves many tasks such as reading the input collection , execution of map() function , execution of reduce() function , writing to the temporary collection during the processin g, and writing the output collection .
map-reduce concurrency & global write lock
The map-reduce-concurrency operation applies many global write locks during the queries’ processing, making the execution much slower to generate the final document.
global write lock
- The read lock applies to the input collection to fetch 100 documents.
- The write lock is applied to creating the output collection and insert, merge, replace, reduce documents into output collection.
- The write lock is global and blocks all the remaining operations on the mongod
MongoDB 5.0 release deprecated map-reduce
The aggregation pipeline is much faster in performance querying multiple collections with the complex data-node relationship. However, MongoDB provides a few aggregation pipeline operators [ $group, $merge, $accumulator, $function ] in the framework layer to facilitate writing Map-Reduce operations using the aggregation pipeline.
What is Aggregation pipeline?
The Aggregation pipeline works as a data processing framework in MongoDB to aggregate hierarchical data nodes. There will be several stages in the pipeline to process the documents to filter out the final analyzed document. The pipeline operators used to apply logical queries and accumulate the filtered records to transform an output structure. The performance of the aggregation pipeline is significantly high compared to Map-Reduce because the framework runs with compiled C++ codes. The data flow control works as a sequence of stages that the output of the previous stage becomes the input to the next stage. The database engine decides the type of aggregation operators to perform at runtime.
How to write an Aggregation pipeline?
The pipeline written as BSON format passes directly into the “ aggregate() ” function in the Mongo Shell for executing the aggregation query. Also, MongoDB provides language-specific drivers that will have an in-built Aggregation framework with structure API functions to implement the pipeline in the application.
More about the topic: