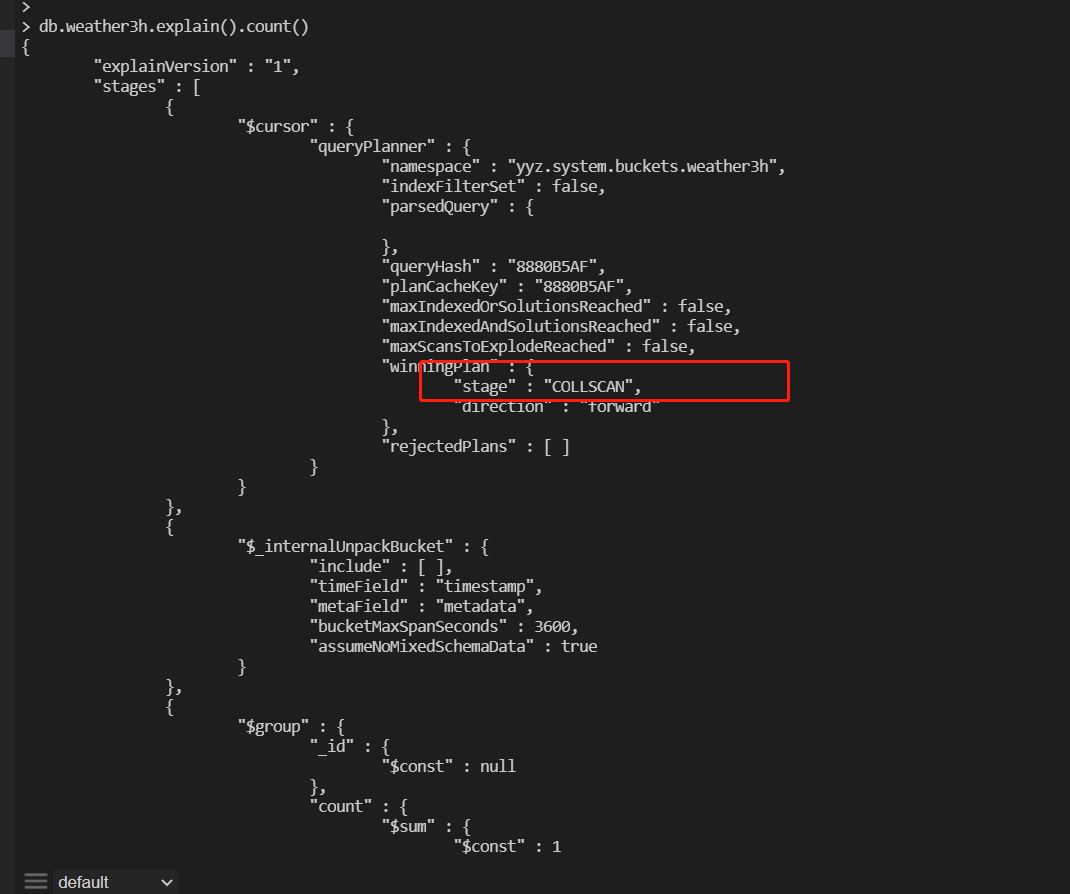
using count to query a collection of 200 million data in a time series collection is very slow, taking about 60 seconds. Looking at the execution plan, it is found that it is a full table scan, which is not required for ordinary collections. Is this a bug or is it a design?
1 Like