Hi team,
We are facing an issue of latency spikes in while writing the data in db. This is happening randomly, but whenever we are getting spike in write latency approximately after half an hour we are seeing a spike in TTL deletes.
Have anyone encountered this issue previously? Is there any solve for the same?
The delete operations are costly to the database server, so this behavior is due to the increase in server resources/hardware use. If your MongoDB deployment is on Atlas, an alternative solution would be Database Triggers configured to delete the documents when the database use is low.
So basically these TTL expired documents are those for which delete was triggered by client, but are removed at some later point?
Something like that, a process runs in the background on the MongoDB server that will delete all the documents where the field has an expired date.
But can this happen even if we not set TTL for the documents?
What do you mean by “this”?
As shown in below graph there are few documents that got removed by ttl_delete operation. But we have not set any TTL for our DB.
What can be the reason for this behaviour?

Hello @Shubham_Shailesh_Doijad
The system collection system.sessions that is in the config database has a TTL index, the expireAfterSeconds for that is 1800. If you have no other collections with TTL indexes this could be why.
s0 [direct: primary] test> db.getSiblingDB('config').system.sessions.getIndexes()
[
{ v: 2, key: { _id: 1 }, name: '_id_' },
{
v: 2,
key: { lastUse: 1 },
name: 'lsidTTLIndex',
expireAfterSeconds: 1800
}
]
https://www.mongodb.com/docs/manual/reference/config-database/#mongodb-data-config.system.sessions
2 Likes
@chris @Artur_57972
So the issue we are facing is, whenever we are seeing these TTL expired spikes, approximately half hour before the spike we are seeing degradation in write latencies resulting downtime in our system. This behaviour has been constant for quite some time.
Any idea what can be the reason for this?
Attaching the reference for the same
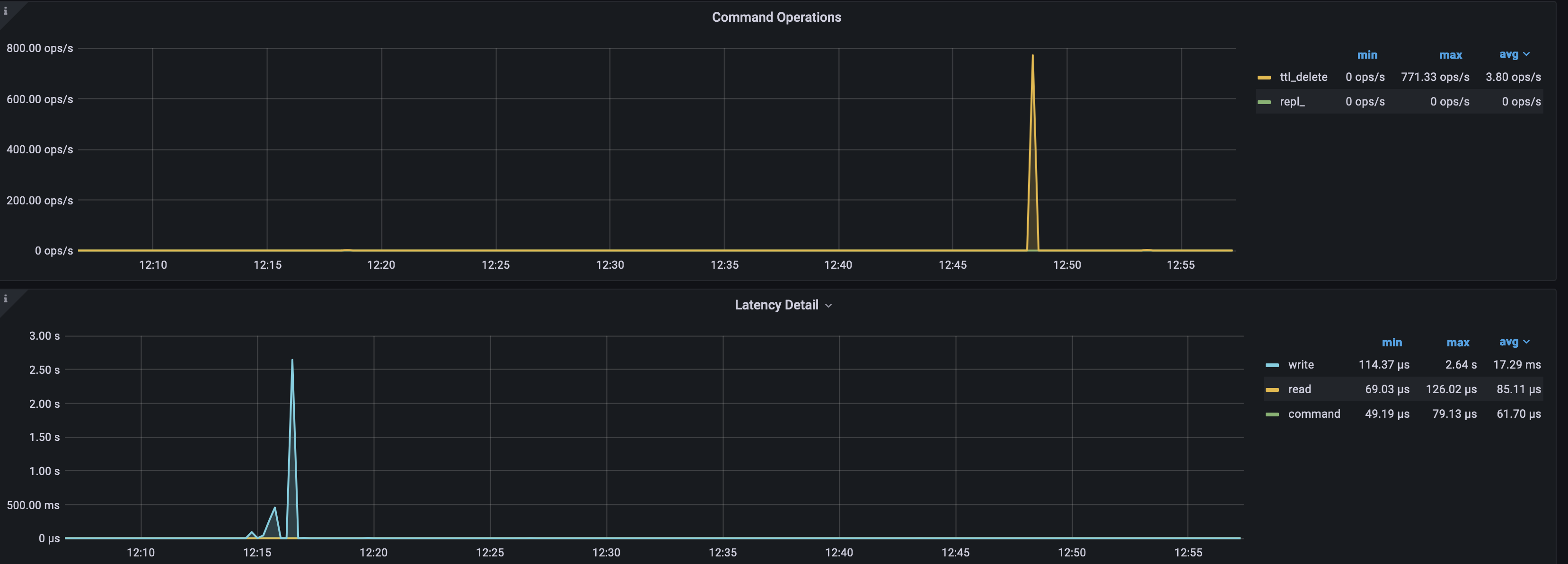
Hey @chris @Artur_57972
Can we setup a call once, to discuss on this
Hi Shubham, I’m not sure how there can be a correlation between your write latency and a TTL delete process 30 minutes later, but if this is happening regularly there may be some other scheduled process or operation happening. If you have more information which you can share then please do so.
Also, please note that this is just a community forum, not a support portal!
Regards
4 Likes
Hey Peter,
Is there a way to check which documents are getting expired? Since the count of the documents getting expired are high so we want to check if its the system data or the actual data stored by the client.
Also what all additional information can help on checking this? Can share it accordingly.
I do not know if there is a solution out of the box, but you probably could set up a change stream that watch for delete operations.
I never did it for a collection that has a TTL index, but I do not see any reason why it would not work. After all change streams are based on the oplog. And all deletes (from TTL or others) are replicated.