Hi,
I am trying to use compound wildcard index to prevent creating too many indexes.
My doc looks like below:
{
"year": 2024,
"month": 8,
"day": 1,
"hour": 0,
"created": {
"$date": "2024-08-01T00:24:37.029Z"
},
"appId": 9,
"os": 9,
"attributes": {
"lang": "zh",
"appVersion": "1.0",
"country": "CN"
}
}
The compound wildcard index script is:
db.my_coll.createIndex(
{
year: 1,
month: 1,
day: 1,
hour: 1,
appId: 1,
os: 1,
"attributes.$**": 1
},
{
name: "compound_wildcard_test"
}
)
And the aggregation pipeline script is:
[
{
$match:
{
year: 2024,
month: 8,
day: 1,
},
},
{
$group:
{
_id: {
appId: "$appId",
os: "$os",
},
value: {
$sum: 1,
},
},
},
]
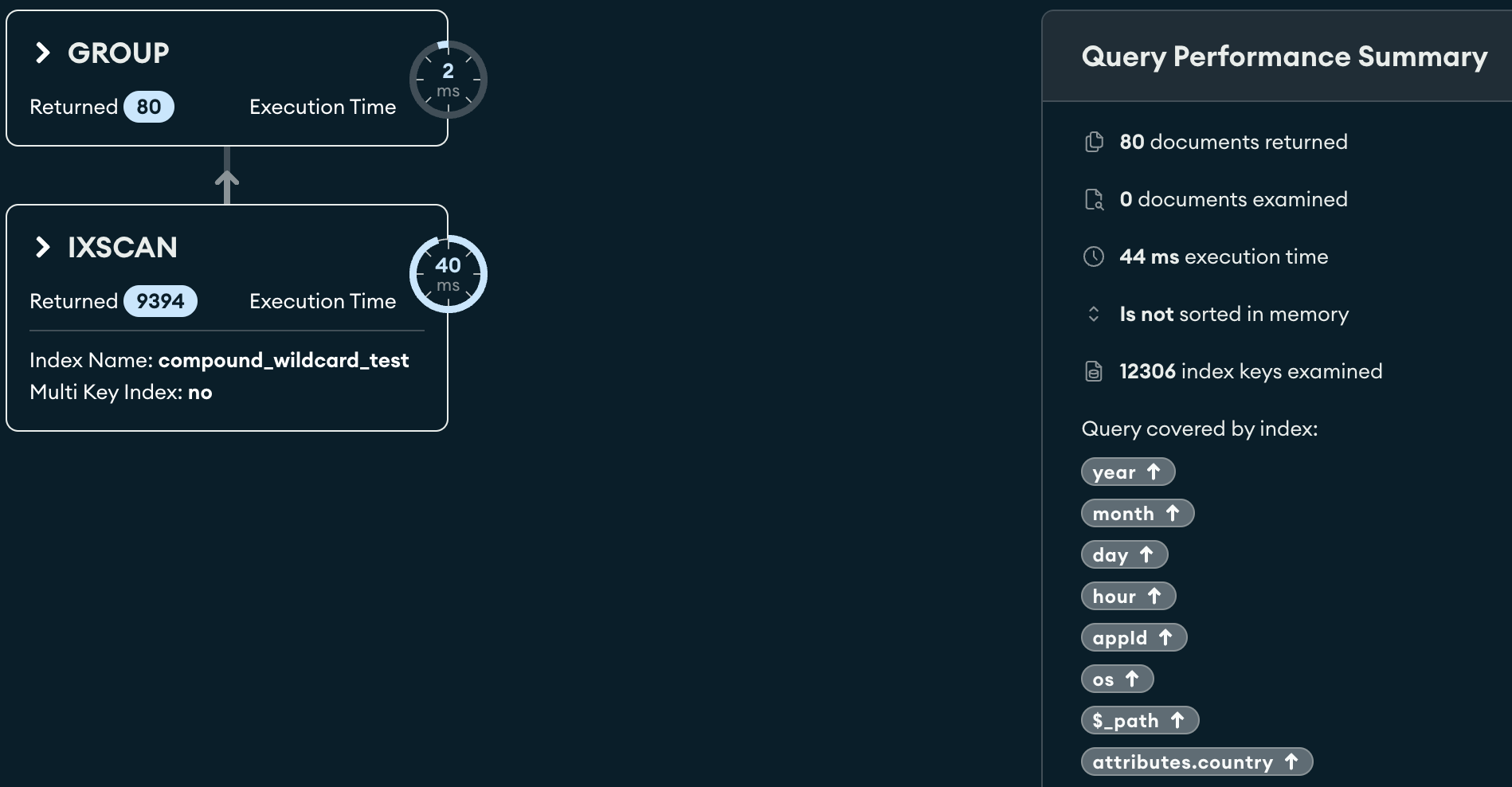
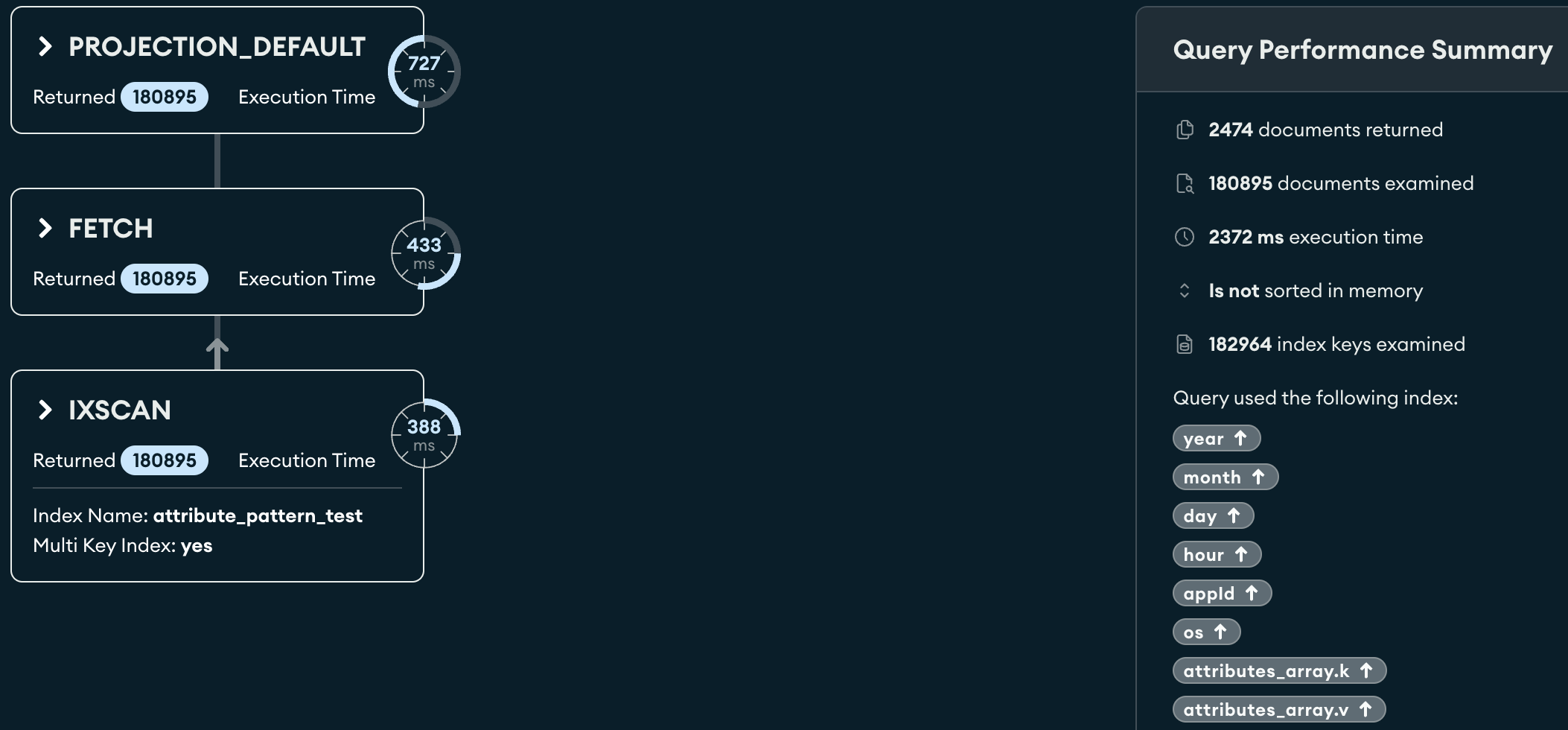
The explain plan is:
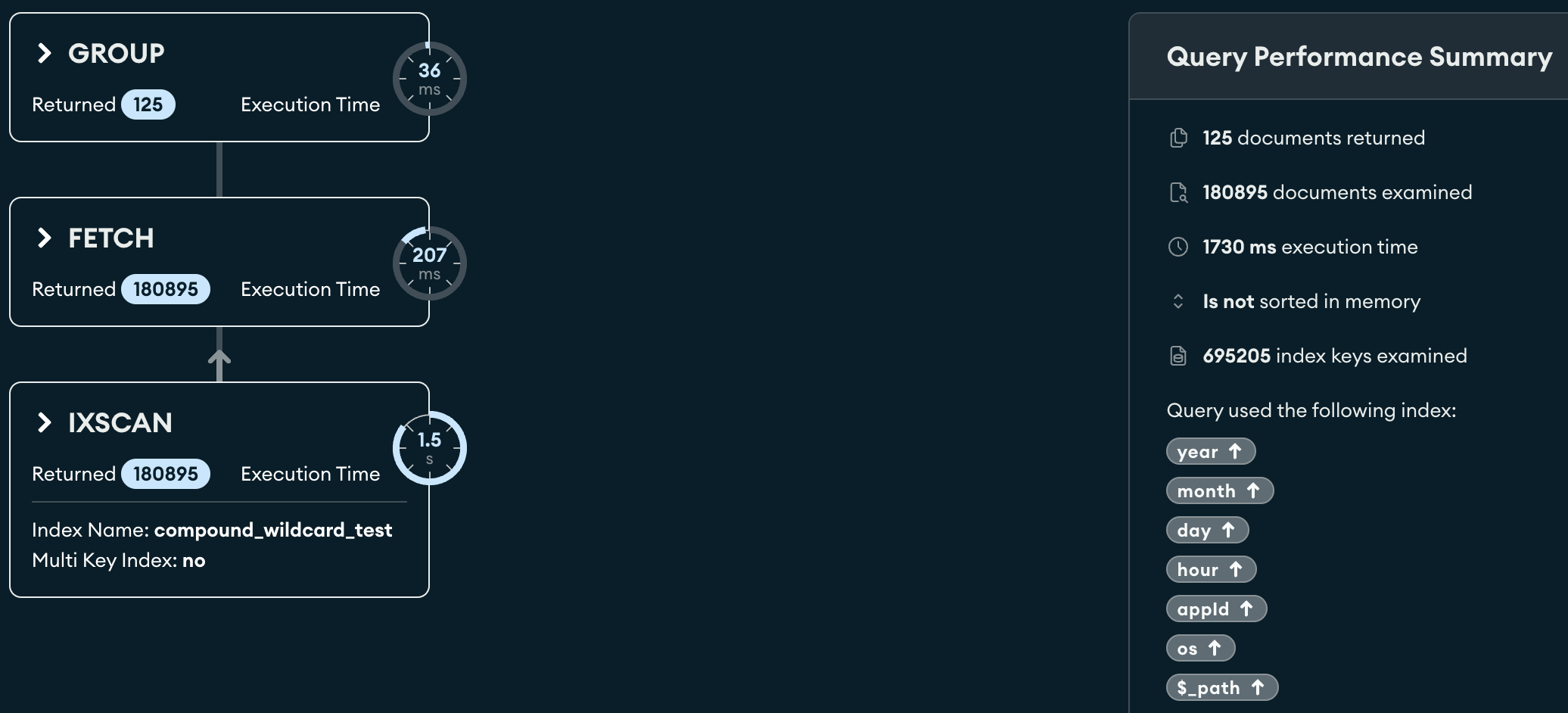
{
"explainVersion": "2",
"queryPlanner": {
"namespace": "my_db.my_coll",
"indexFilterSet": false,
"parsedQuery": {
"$and": [
{ "day": { "$eq": 1 } },
{ "month": { "$eq": 8 } },
{ "year": { "$eq": 2024 } }
]
},
"queryHash": "F4876F52",
"planCacheKey": "E072E021",
"optimizedPipeline": true,
"maxIndexedOrSolutionsReached": false,
"maxIndexedAndSolutionsReached": false,
"maxScansToExplodeReached": false,
"winningPlan": {
"queryPlan": {
"stage": "GROUP",
"planNodeId": 4,
"inputStage": {
"stage": "FETCH",
"planNodeId": 2,
"inputStage": {
"stage": "IXSCAN",
"planNodeId": 1,
"keyPattern": {
"year": 1,
"month": 1,
"day": 1,
"hour": 1,
"appId": 1,
"os": 1,
"$_path": 1
},
"indexName": "compound_wildcard_test",
"isMultiKey": false,
"multiKeyPaths": {
"year": [],
"month": [],
"day": [],
"hour": [],
"appId": [],
"os": [],
"$_path": []
},
"isUnique": false,
"isSparse": true,
"isPartial": false,
"indexVersion": 2,
"direction": "forward",
"indexBounds": {
"year": ["[2024, 2024]"],
"month": ["[8, 8]"],
"day": ["[1, 1]"],
"hour": ["[MinKey, MaxKey]"],
"appId": ["[MinKey, MaxKey]"],
"os": ["[MinKey, MaxKey]"],
"$_path": ["[MinKey, MaxKey]"]
}
}
}
},
"slotBasedPlan": {
"slots": "$$RESULT=s33 env: { s4 = 1728027185275 (NOW), s3 = Timestamp(1728027184, 265) (CLUSTER_TIME), s2 = Nothing (SEARCH_META), s14 = Nothing, s10 = {\"year\" : 1, \"month\" : 1, \"day\" : 1, \"hour\" : 1, \"appId\" : 1, \"os\" : 1, \"$_path\" : 1, \"$_path\" : 1}, s25 = true, s1 = TimeZoneDatabase(America/Indiana/Tell_City...Africa/Blantyre) (timeZoneDB), s6 = IndexBounds(\"field #0['year']: [2024, 2024], field #1['month']: [8, 8], field #2['day']: [1, 1], field #3['hour']: [MinKey, MaxKey], field #4['appId']: [MinKey, MaxKey], fie\"...) }",
"stages": "[4] project [s33 = newBsonObj(\"_id\", s32, \"value\", s30)] \n[4] project [s32 = newObj(\"appId\", s28, \"os\", s29)] \n[4] group [s28, s29] [s30 = sum(1)] spillSlots[s31] mergingExprs[sum(s31)] \n[2] nlj inner [] [s20, s21, s22, s23, s24] \n left \n [1] unique [s20] \n [1] branch {s25} [s20, s21, s22, s23, s24] \n [s5, s7, s8, s9, s10] [1] ixscan_generic s6 s9 s5 s7 s8 lowPriority [] @\"91308ead-aebb-40f8-9b39-fb5dcc5bb80a\" @\"compound_wildcard_test\" true \n [s11, s17, s18, s19, s10] [1] nlj inner [] [s12, s13] \n left \n [1] project [s12 = getField(s15, \"l\"), s13 = getField(s15, \"h\")] \n [1] unwind s15 s16 s14 false \n [1] limit 1ll \n [1] coscan \n right \n [1] ixseek s12 s13 s19 s11 s17 s18 [] @\"91308ead-aebb-40f8-9b39-fb5dcc5bb80a\" @\"compound_wildcard_test\" true \n right \n [2] limit 1ll \n [2] seek s20 s26 s27 s21 s22 s23 s24 [s28 = appId, s29 = os] @\"91308ead-aebb-40f8-9b39-fb5dcc5bb80a\" true false \n"
}
},
"rejectedPlans": []
},
"executionStats": {
"executionSuccess": true,
"nReturned": 125,
"executionTimeMillis": 1730,
"totalKeysExamined": 695205,
"totalDocsExamined": 180895,
"executionStages": {
"stage": "project",
"planNodeId": 4,
"nReturned": 125,
"executionTimeMillisEstimate": 1726,
"opens": 1,
"closes": 1,
"saveState": 697,
"restoreState": 697,
"isEOF": 1,
"projections": {
"33": "newBsonObj(\"_id\", s32, \"value\", s30) "
},
"inputStage": {
"stage": "project",
"planNodeId": 4,
"nReturned": 125,
"executionTimeMillisEstimate": 1726,
"opens": 1,
"closes": 1,
"saveState": 697,
"restoreState": 697,
"isEOF": 1,
"projections": {
"32": "newObj(\"appId\", s28, \"os\", s29) "
},
"inputStage": {
"stage": "group",
"planNodeId": 4,
"nReturned": 125,
"executionTimeMillisEstimate": 1726,
"opens": 1,
"closes": 1,
"saveState": 697,
"restoreState": 697,
"isEOF": 1,
"groupBySlots": [28, 29],
"expressions": {
"30": "sum(1) ",
"initExprs": { "30": null }
},
"mergingExprs": { "31": "sum(s31) " },
"usedDisk": false,
"spills": 0,
"spilledRecords": 0,
"spilledDataStorageSize": 0,
"inputStage": {
"stage": "nlj",
"planNodeId": 2,
"nReturned": 180895,
"executionTimeMillisEstimate": 1690,
"opens": 1,
"closes": 1,
"saveState": 697,
"restoreState": 697,
"isEOF": 1,
"totalDocsExamined": 180895,
"totalKeysExamined": 695205,
"collectionScans": 0,
"collectionSeeks": 180895,
"indexScans": 0,
"indexSeeks": 1,
"indexesUsed": [
"compound_wildcard_test",
"compound_wildcard_test"
],
"innerOpens": 180895,
"innerCloses": 1,
"outerProjects": [],
"outerCorrelated": [
20, 21, 22, 23, 24
],
"outerStage": {
"stage": "unique",
"planNodeId": 1,
"nReturned": 180895,
"executionTimeMillisEstimate": 1483,
"opens": 1,
"closes": 1,
"saveState": 697,
"restoreState": 697,
"isEOF": 1,
"dupsTested": 695204,
"dupsDropped": 514309,
"keySlots": [20],
"inputStage": {
"stage": "branch",
"planNodeId": 1,
"nReturned": 695204,
"executionTimeMillisEstimate": 1295,
"opens": 1,
"closes": 1,
"saveState": 697,
"restoreState": 697,
"isEOF": 1,
"numTested": 1,
"thenBranchOpens": 1,
"thenBranchCloses": 1,
"elseBranchOpens": 0,
"elseBranchCloses": 0,
"filter": "s25 ",
"thenSlots": [5, 7, 8, 9, 10],
"elseSlots": [11, 17, 18, 19, 10],
"outputSlots": [
20, 21, 22, 23, 24
],
"thenStage": {
"stage": "ixscan_generic",
"planNodeId": 1,
"nReturned": 695204,
"executionTimeMillisEstimate": 1295,
"opens": 1,
"closes": 1,
"saveState": 697,
"restoreState": 697,
"isEOF": 1,
"indexName": "compound_wildcard_test",
"keysExamined": 695205,
"seeks": 1,
"numReads": 695205,
"indexKeySlot": 9,
"recordIdSlot": 5,
"snapshotIdSlot": 7,
"indexIdentSlot": 8,
"outputSlots": [],
"indexKeysToInclude": "00000000000000000000000000000000"
},
"elseStage": {
"stage": "nlj",
"planNodeId": 1,
"nReturned": 0,
"executionTimeMillisEstimate": 0,
"opens": 0,
"closes": 0,
"saveState": 697,
"restoreState": 697,
"isEOF": 0,
"totalDocsExamined": 0,
"totalKeysExamined": 0,
"collectionScans": 0,
"collectionSeeks": 0,
"indexScans": 0,
"indexSeeks": 0,
"indexesUsed": [
"compound_wildcard_test"
],
"innerOpens": 0,
"innerCloses": 0,
"outerProjects": [],
"outerCorrelated": [12, 13],
"outerStage": {
"stage": "project",
"planNodeId": 1,
"nReturned": 0,
"executionTimeMillisEstimate": 0,
"opens": 0,
"closes": 0,
"saveState": 697,
"restoreState": 697,
"isEOF": 0,
"projections": {
"12": "getField(s15, \"l\") ",
"13": "getField(s15, \"h\") "
},
"inputStage": {
"stage": "unwind",
"planNodeId": 1,
"nReturned": 0,
"executionTimeMillisEstimate": 0,
"opens": 0,
"closes": 0,
"saveState": 697,
"restoreState": 697,
"isEOF": 0,
"inputSlot": 14,
"outSlot": 15,
"outIndexSlot": 16,
"preserveNullAndEmptyArrays": 0,
"inputStage": {
"stage": "limit",
"planNodeId": 1,
"nReturned": 0,
"executionTimeMillisEstimate": 0,
"opens": 0,
"closes": 0,
"saveState": 697,
"restoreState": 697,
"isEOF": 0,
"inputStage": {
"stage": "coscan",
"planNodeId": 1,
"nReturned": 0,
"executionTimeMillisEstimate": 0,
"opens": 0,
"closes": 0,
"saveState": 697,
"restoreState": 697,
"isEOF": 0
}
}
}
},
"innerStage": {
"stage": "ixseek",
"planNodeId": 1,
"nReturned": 0,
"executionTimeMillisEstimate": 0,
"opens": 0,
"closes": 0,
"saveState": 697,
"restoreState": 697,
"isEOF": 0,
"indexName": "compound_wildcard_test",
"keysExamined": 0,
"seeks": 0,
"numReads": 0,
"indexKeySlot": 19,
"recordIdSlot": 11,
"snapshotIdSlot": 17,
"indexIdentSlot": 18,
"outputSlots": [],
"indexKeysToInclude": "00000000000000000000000000000000",
"seekKeyLow": "s12 ",
"seekKeyHigh": "s13 "
}
}
}
},
"innerStage": {
"stage": "limit",
"planNodeId": 2,
"nReturned": 180895,
"executionTimeMillisEstimate": 206,
"opens": 180895,
"closes": 1,
"saveState": 697,
"restoreState": 697,
"isEOF": 1,
"limit": 1,
"inputStage": {
"stage": "seek",
"planNodeId": 2,
"nReturned": 180895,
"executionTimeMillisEstimate": 196,
"opens": 180895,
"closes": 1,
"saveState": 697,
"restoreState": 697,
"isEOF": 0,
"numReads": 180895,
"recordSlot": 26,
"recordIdSlot": 27,
"seekKeySlot": 20,
"snapshotIdSlot": 21,
"indexIdentSlot": 22,
"indexKeySlot": 23,
"indexKeyPatternSlot": 24,
"fields": ["appId", "os"],
"outputSlots": [28, 29]
}
}
}
}
}
}
},
"command": {
"aggregate": "my_coll",
"pipeline": [
{
"$match": {
"year": 2024,
"month": 8,
"day": 1
}
},
{
"$group": {
"_id": {
"appId": "$appId",
"os": "$os"
},
"value": { "$sum": 1 }
}
}
],
"cursor": {},
"maxTimeMS": 300000,
"$db": "my_db"
},
"serverInfo": {
"host": "atlas-9modrn-shard-00-01.aw6o0.mongodb.net",
"port": 27017,
"version": "7.0.12",
"gitVersion": "b6513ce0781db6818e24619e8a461eae90bc94fc"
},
"serverParameters": {
"internalQueryFacetBufferSizeBytes": 104857600,
"internalQueryFacetMaxOutputDocSizeBytes": 104857600,
"internalLookupStageIntermediateDocumentMaxSizeBytes": 104857600,
"internalDocumentSourceGroupMaxMemoryBytes": 104857600,
"internalQueryMaxBlockingSortMemoryUsageBytes": 104857600,
"internalQueryProhibitBlockingMergeOnMongoS": 0,
"internalQueryMaxAddToSetBytes": 104857600,
"internalDocumentSourceSetWindowFieldsMaxMemoryBytes": 104857600,
"internalQueryFrameworkControl": "trySbeRestricted"
},
"ok": 1,
"$clusterTime": {
"clusterTime": {
"$timestamp": "7421820250468909061"
},
"signature": {
"hash": "/UK0CMpYqyJCh8d2WJxz676xcRc=",
"keyId": {
"low": 2,
"high": 1713453437,
"unsigned": false
}
}
},
"operationTime": {
"$timestamp": "7421820250468909061"
}
}
All query fields are all defined in compound_wildcard_test index.
Why it still use fetch stage which makes query slow?
And how can I prevent fetch stage?
Any ideas are welcome!
Thank you.