Hi everyone,
I’m running into an issue with decreasing write speeds in my MongoDB setup, and I’m hoping for some advice.
Here’s what I’m working with:
- Library: PyMongo
- Data Volume: About 36,000 documents ready for processing.
- Bulk Writes: Inserting 1,440 documents at a time.
- Threads: Using 10 threads, but only getting up to 6 MB/s.
- Indexes: Six indexes in total, including a 2Dsphere index.
The write speed starts out okay but gets slower over time, which is confusing since the volume of bulk writes stays the same. I’m not sure why this is happening. I am wondering if 2Dsphere is really slowing me down.
Here is my bulk updates from my code including the parallel processing:
def process_batch(batch, start_index):
client = MongoClient("mongodb:************") db = client["Wind_Database"] collection = db['weather_data_test'] try: result = collection.bulk_write(batch, ordered=False) return { "success": True, "start_index": start_index, "end_index": start_index + len(batch), "inserted_count": result.inserted_count, "matched_count": result.matched_count, "modified_count": result.modified_count, "deleted_count": result.deleted_count, "upserted_count": result.upserted_count } except Exception as e: return {"success": False, "error": str(e), "start_index": start_index, "end_index": start_index + len(batch)}
def bulk_loop(x):
operations =
for _ in range(step_size):lon = int(bin_list[x][0]) lat = int(bin_list[x][1]) alt = int(bin_list[x][2]) #print(lat, lon, alt) alt = alt_from_bin(alt) # print(alt) initialize_or_avg_grid_value(operations, local_documents, alt, month, lon, lat, x) x += 1 print("Uploading in bulk") num_threads = 10 batch_size = 1440 # Creating batches of operations batches = [operations[i:i + batch_size] for i in range(0, len(operations), batch_size)] # Using ThreadPoolExecutor to process batches in parallel with ThreadPoolExecutor(max_workers=num_threads) as executor: # Submit all batches to the executor future_to_batch = {executor.submit(process_batch, batch, i * batch_size): i for i, batch in enumerate(batches)} # Process results as they complete for future in as_completed(future_to_batch): result = future.result() if result["success"]: print(f"Bulk operation batch successful for operations {result['start_index']} to {result['end_index']}") ("Inserted count:", result['inserted_count']) print("Matched count:", result['matched_count']) print("Modified count:", result['modified_count']) print("Deleted count:", result['deleted_count']) print("Upserted count:", result['upserted_count']) else: print(f"An error occurred in batch {result['start_index']} to {result['end_index']}: {result['error']}") operations.clear() # Clear operations after all batches have been processed return x
The photo below is what my data schema looks like, geoPoints is an array of geoJSON objects:
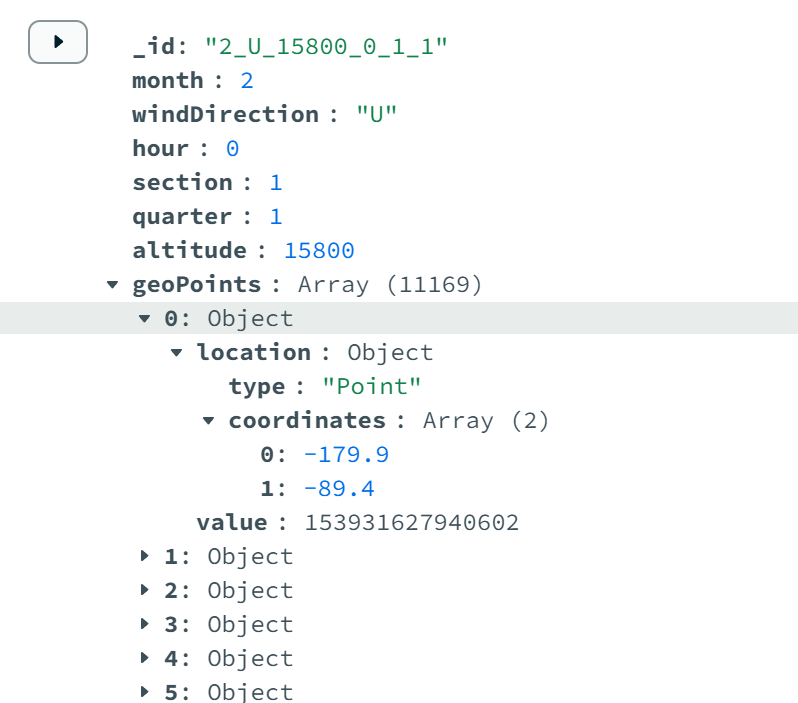
Does anyone have insights on why this might be or how to maintain consistent performance? Any help would be greatly appreciated.