Enterprise Content Management (ECM) is mission-critical to almost every large organization. It underpins how contracts are signed, invoices are archived, citizen records are retained, and how billions of documents are searched and governed every day. Yet most ECM platforms still run on architectures designed decades ago, struggling to keep up with today’s scale, agility, and AI expectations.
What ECM really does: Nodes, metadata, and services
At its core, ECM is the set of tools and systems that allow organizations to use content they produce or collect, within the boundaries of policies applied to it. It’s not “just a digital filing cabinet;” it’s a content fabric that connects unstructured content with enterprise data, workflows, and compliance rules.
Most ECM architectures share the same building blocks:
- File storage: The binaries (PDFs, images, videos…) are often stored in SAN/NAS, or modern object storage like S3.
- Metadata storage: A structured description of content: type, owner, lifecycle, retention, security, relationships, and more.
- Value‑added services: Search, workflows/BPM, categorization and filing plans, versioning, signatures, retention and legal hold, and exposure via APIs or UI.
A central concept in many ECM systems is the node. A node represents a document or content item. It has metadata (title, author, business fields, filing plan…), relationships (folder structure, related documents, cases), and content references (0, 1, or many content files, e.g., main PDF + signature file + renditions).
Nodes are the “atom” of ECM: everything (security, lifecycle, search, workflows) acts on nodes, and large ECM repositories can contain hundreds of millions or even billions of them.
This is exactly the problem space where traditional architectures start to creak.
MongoDB offers a modern foundation for ECM: a document database that naturally models content, scales to billions of nodes, and makes metadata instantly searchable with full‑text, semantic, and vector capabilities. In this post, we’ll explore what ECM really is, why legacy platforms are hitting a wall, and how MongoDB, validated by large‑scale customer deployments, provides a better way.
Why traditional ECM architectures fail at modern scale
Most legacy ECM platforms were built on relational databases and monolithic stacks. That made sense when repositories contained millions of documents. It breaks down at national‑archive or global enterprise scale with billions of items and petabytes of content.
Common pain points include:
- Rigid schemas and slow change
- Every new metadata field (e.g., an AI‑generated tag, a new classification code) can trigger schema changes, migrations, and change‑management projects.
- This directly slows down innovation and time‑to‑market for new digital services.
- Vertical scaling and complex scaling patterns
- Traditional RDBMS‑based ECMs tend to scale “up” rather than “out.”
- As content grows to billions of rows, performance degrades non‑linearly, and horizontal scale‑out is extremely hard.
- Operational complexity and silos
- Many ECM platforms are a mesh of components: database, search engine, workflow engine, application server, file store, and custom middleware.
- This makes operations and upgrades complex and creates silos that are not AI‑ready.
- Limited search and analytics
- Metadata search is often bolted on, with separate search engines and ETL pipelines.
- Real‑time analytics on content metadata or access logs is rarely first‑class.
- AI un‑readiness
- Unstructured content lives in fragmented repositories, making it hard to build semantic search, RAG, or knowledge agents on top.
The net effect: employees waste time finding information, projects to modernize ECM drag on, and AI initiatives stall because content is trapped in legacy silos.
Why MongoDB is a natural fit for ECM
MongoDB’s document model looks remarkably similar to how ECM experts think about nodes and metadata.
1. Documents as Nodes
A typical ECM node in MongoDB might look like this:
This matches how ECM platforms already conceptualize content:
Metadata: arbitrary, polymorphic JSON which is perfect for capturing business attributes, AI‑generated tags, and technical metadata (e.g., source system, retention class).
Relationships: parent folders, related cases, or taxonomies encoded as references or arrays.
Content: stored in object storage (S3, Blob, etc.), referenced by URI in the document, is a proven pattern in modern content architectures.
Because MongoDB documents are atomic, everything that happens to a node (metadata update, ACL change, version bump) is a single transaction on that document or a small set of related documents.
2. Flexible metadata: Evolving without migrations
ECM is all about metadata, and metadata never stops evolving. New regulations, channels, or AI pipelines constantly introduce new fields.
MongoDB’s schema‑flexible model means:
- You can add new metadata (e.g., ai_topics, language, sensitivity_level, embedding_vector) without schema migrations.
- Old documents can be enriched on demand over time or kept as‑is. Your application decides the strategy.
- JSON Schema‑based validation lets you enforce governance where needed (e.g., for regulated document classes) while remaining flexible elsewhere.
This is a crucial advantage when modernizing ECM and layering in AI: no more multi‑month schema projects to add new tags or embeddings.
3. Scale‑out for billion‑document repositories
MongoDB was architected for horizontal scalability:
- Replica sets for high availability and workload isolation (e.g., dedicated read nodes for analytics or search indexing).
- Sharding to distribute collections across many nodes, with hashed, ranged, and zoned sharding strategies and live resharding.
- Global clusters for data residency and low‑latency access across regions (e.g., separate zones for EU, US, and APAC archives).
MongoDB comfortably handles billions of documents with high ingest and query throughput across use cases like import, search, reindexing, and versioning.
4. Rich search: From keywords to semantics
ECM stands or falls on its ability to find the right document quickly. MongoDB brings several layers of search to the metadata tier:
- Atlas Search: Embedded full‑text search powered by Apache Lucene, eliminating the need for a separate search engine:
- Full‑text search across metadata and extracted content.
- Language analyzers for 30+ languages, fuzzy matching, autocomplete, highlighting, facets, and custom scoring.
- Semantic Similarity: Auto‑embed content with Voyage AI, store embeddings (text and multimodal) alongside metadata, and run advanced semantic queries such as “find similar cases” or “documents about this topic”, with optional reranking for higher‑quality results, all using the same database and query API.
- Aggregation Framework: Powerful pipelines to apply security filters, retrieve current or all versions, implement field‑level redaction, and run analytics on content metadata in one place.
Together, this turns MongoDB into a search‑ready content hub: keyword, faceted, and semantic search are all native to the platform, not stitched together through multiple systems.
Figure 1. Content management system built with MongoDB.
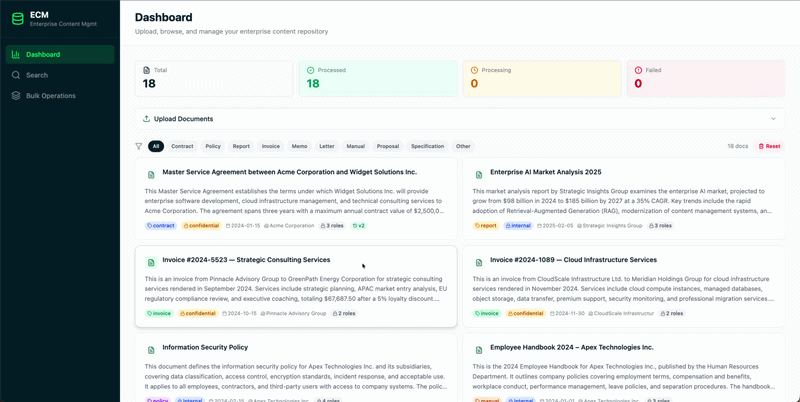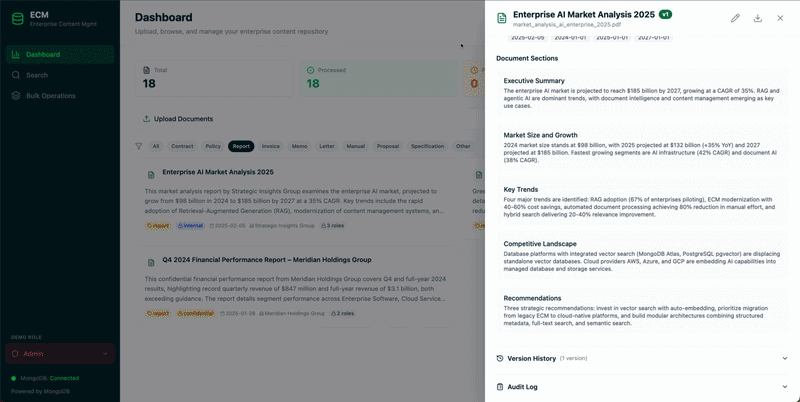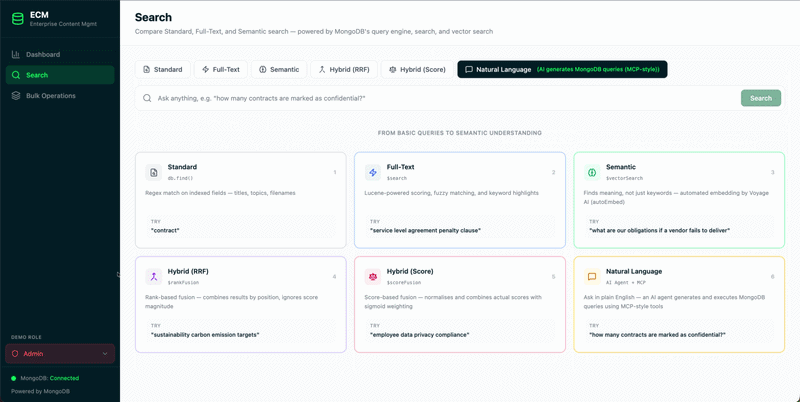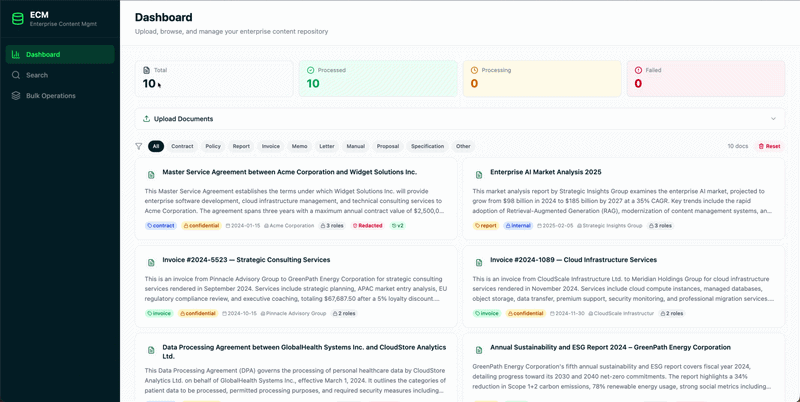
5. Advanced content capabilities in the data layer
MongoDB’s document model also simplifies classic ECM features that are often awkward in relational schemas:
- Versioning: A simple version field with patterns described in MongoDB’s Document Versioning pattern. Aggregation pipelines can ensure you always retrieve the latest or all versions, depending on the use case.
- Taxonomies and folder hierarchies: Multiple patterns to represent trees (ancestor arrays, parent references, etc.) that are efficient to query and index.
- Document‑level security: ACLs and access levels encoded directly in the document, enforced via queries or aggregation stages, ideal for fine‑grained entitlements without overcomplicating the schema.
These patterns have been proven across ECM and archiving workloads in sectors like telecom, public sector, and financial services. For example, MongoDB Atlas helps EVANA, a German AI company serving real estate investors, tackle the complexity and volume of property data involved in transactions. By consolidating disparate, rapidly changing information into a single, flexible document database, EVANA can surface relevant insights quickly and reliably, improving both accuracy at scale and the overall customer experience for real estate professionals.
An on-premise, cloud native, or hybrid environments ECM reference architecture with MongoDB
A modern ECM architecture built on MongoDB typically looks like this:
Figure 2. A modern ECM architecture.
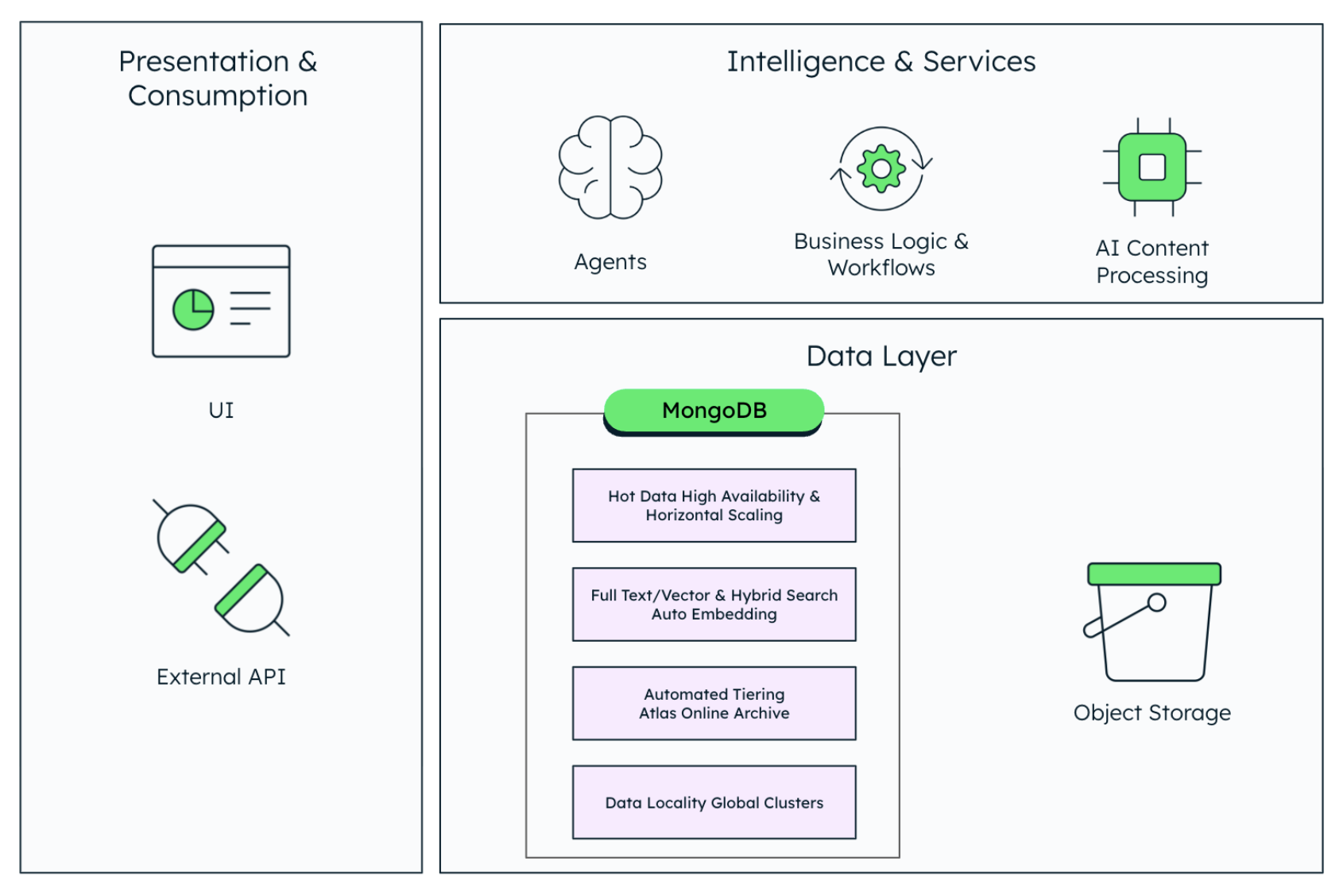
This aligns the functional axis (nodes / documents) with the scalability axis (shards), making large‑scale ECM much simpler to grow. You scale by adding nodes, not re-architecting the entire platform.
When (and how) to choose MongoDB for ECM
MongoDB is not an ECM product by itself. It doesn’t provide a UI, viewer, or workflow engine out of the box. Instead, it’s the ideal backend data platform for ECM and content services when:
You need to handle billions of content items and petabytes of data.
Metadata structures change frequently or must absorb AI‑generated fields without friction.
Search requirements span metadata, full‑text, and semantic use cases.
You want a cloud‑native, microservices‑ready architecture with strong SLAs and data residency options.
You’re modernizing a legacy ECM and want to separate content storage, metadata, and application logic.
In these scenarios, MongoDB provides the scalable, flexible, AI‑ready content backbone, and partners, ISVs, or internal teams build the application layer on top.
Conclusion
ECM is undergoing a profound shift:
From monolithic platforms to cloud‑native content services.
From rigid relational schemas to flexible document models.
From simple keyword search to semantic and vector‑powered retrieval.
From isolated silos to AI‑ready content fabrics.
MongoDB sits at the heart of this transformation. By modeling ECM nodes as documents, scaling horizontally across clusters and regions, and embedding powerful search and analytics, it gives organizations a modern foundation to manage content at massive scale and to finally bring their ECM data into the age of AI.
If you’re looking at modernizing an archive, consolidating multiple content repositories, or enabling AI use cases on top of your documents, evaluating MongoDB as your ECM metadata and search platform is an excellent place to start.
Next Steps
For more information on how MongoDB supports content management use cases, visit our solutions page.