In production AI, what the system retrieves shapes everything that follows. It determines whether an application surfaces the right context in the first place and how much irrelevant information gets passed to an LLM. That affects two things you care about most: answer quality and cost.
In an agentic workflow, retrieval is iterative. The model retrieves, reasons, decides what to do next, and retrieves again. A weak result does not just hurt one response; it can send the next step off course and drive up cost as LLMs spend time processing documents that were never the right fit.
Today, MongoDB is making that retrieval path stronger in two places at once. Hybrid search is now generally available, and native reranking with $rerank is available in public preview on Atlas clusters running MongoDB 8.3. Together, they help developers improve both retrieval candidate generation and final result ordering in the same query path, directly in MongoDB, where live application data already lives.
Retrieval for agents is a two-stage problem
Successful modern retrieval entails addressing two issues. First, you need to identify a strong candidate set. Then you need to put that set in the right order.
Hybrid search improves the first stage. By combining lexical precision with semantic recall, MongoDB helps applications retrieve a stronger pool of possible matches than text or vector search alone can provide. Developers can implement hybrid search directly using MongoDB aggregation stages: $rankFusion merges results using reciprocal rank fusion, which ranks documents by their position across each result set, while $scoreFusion combines results according to normalized relevance scores.
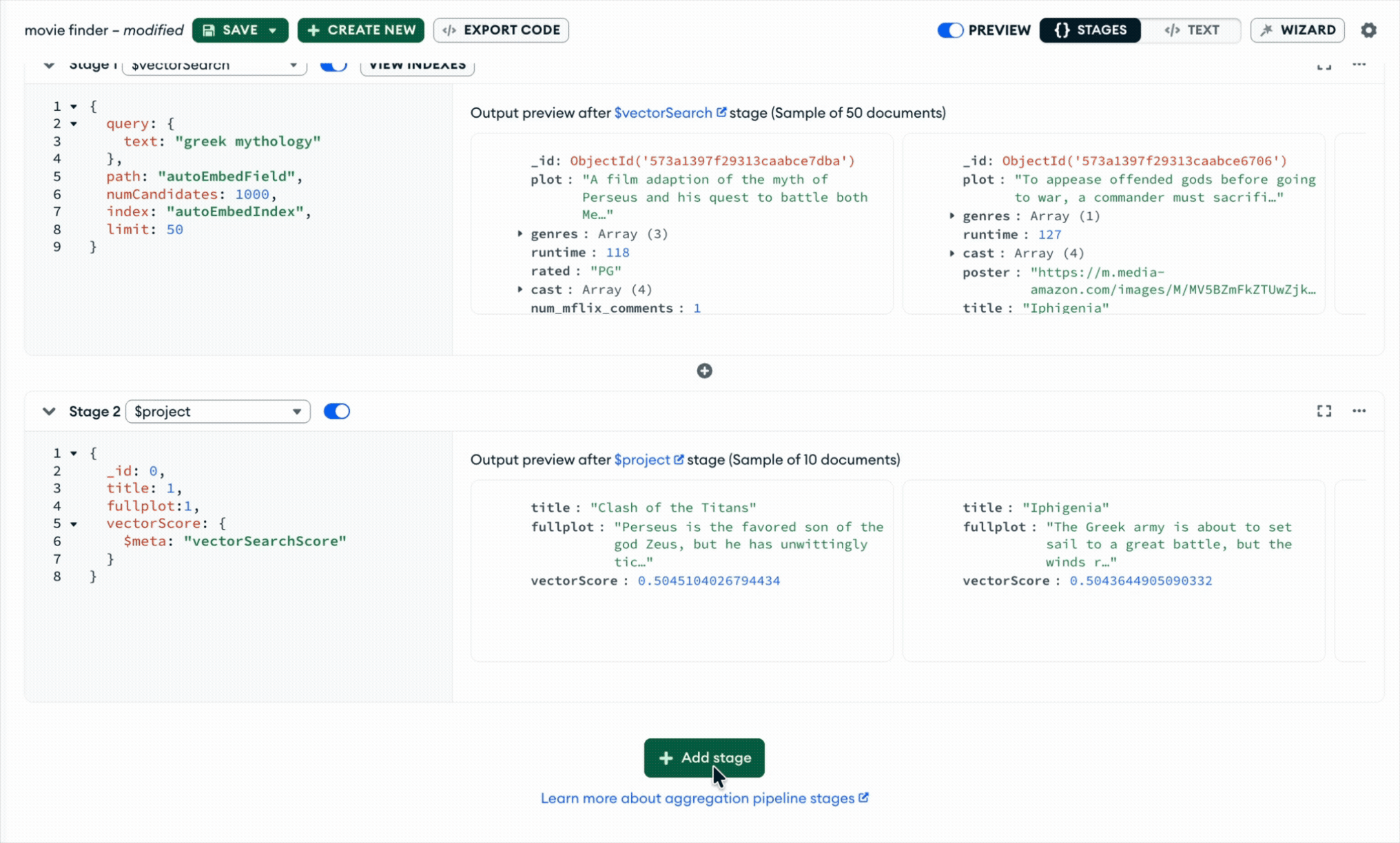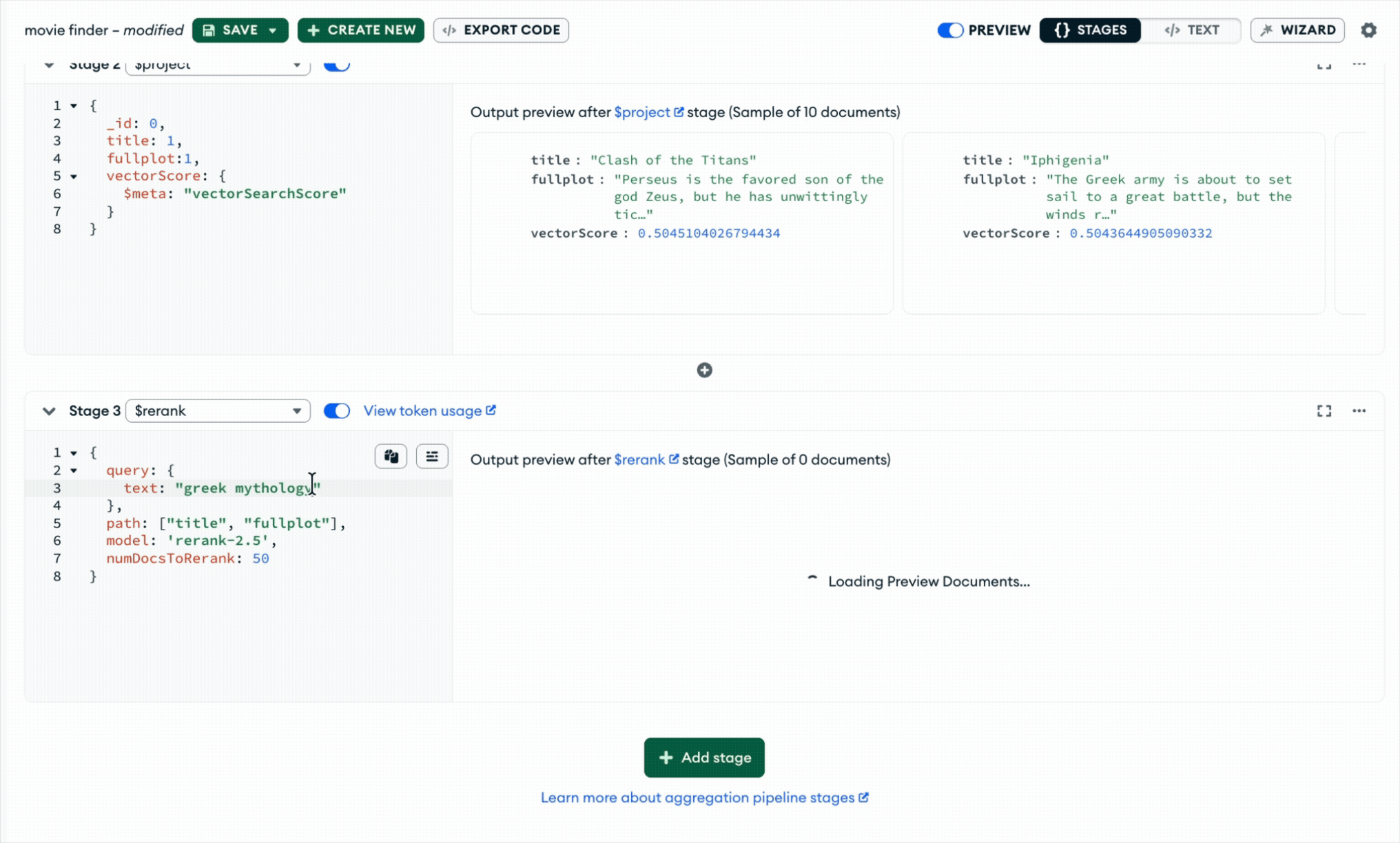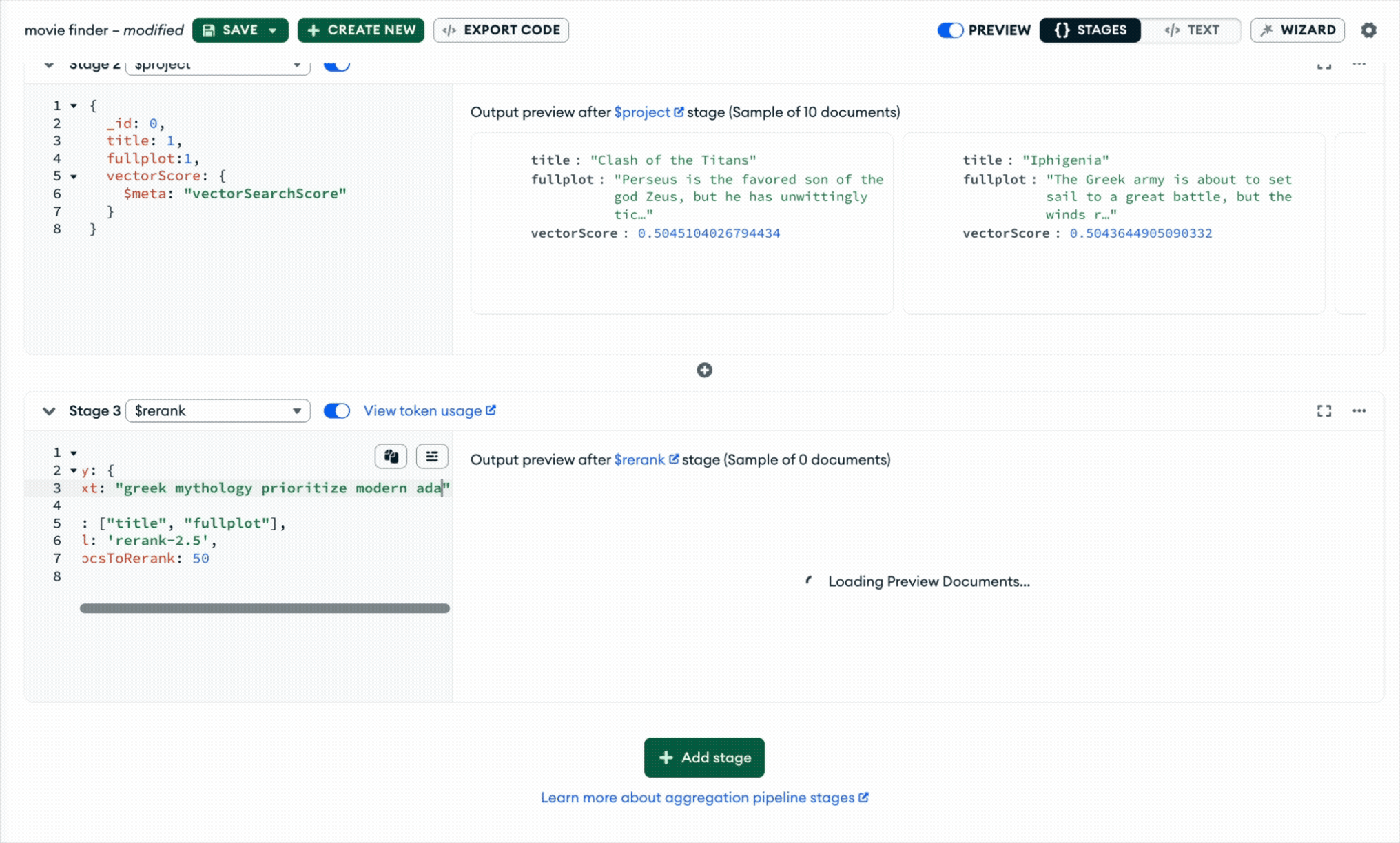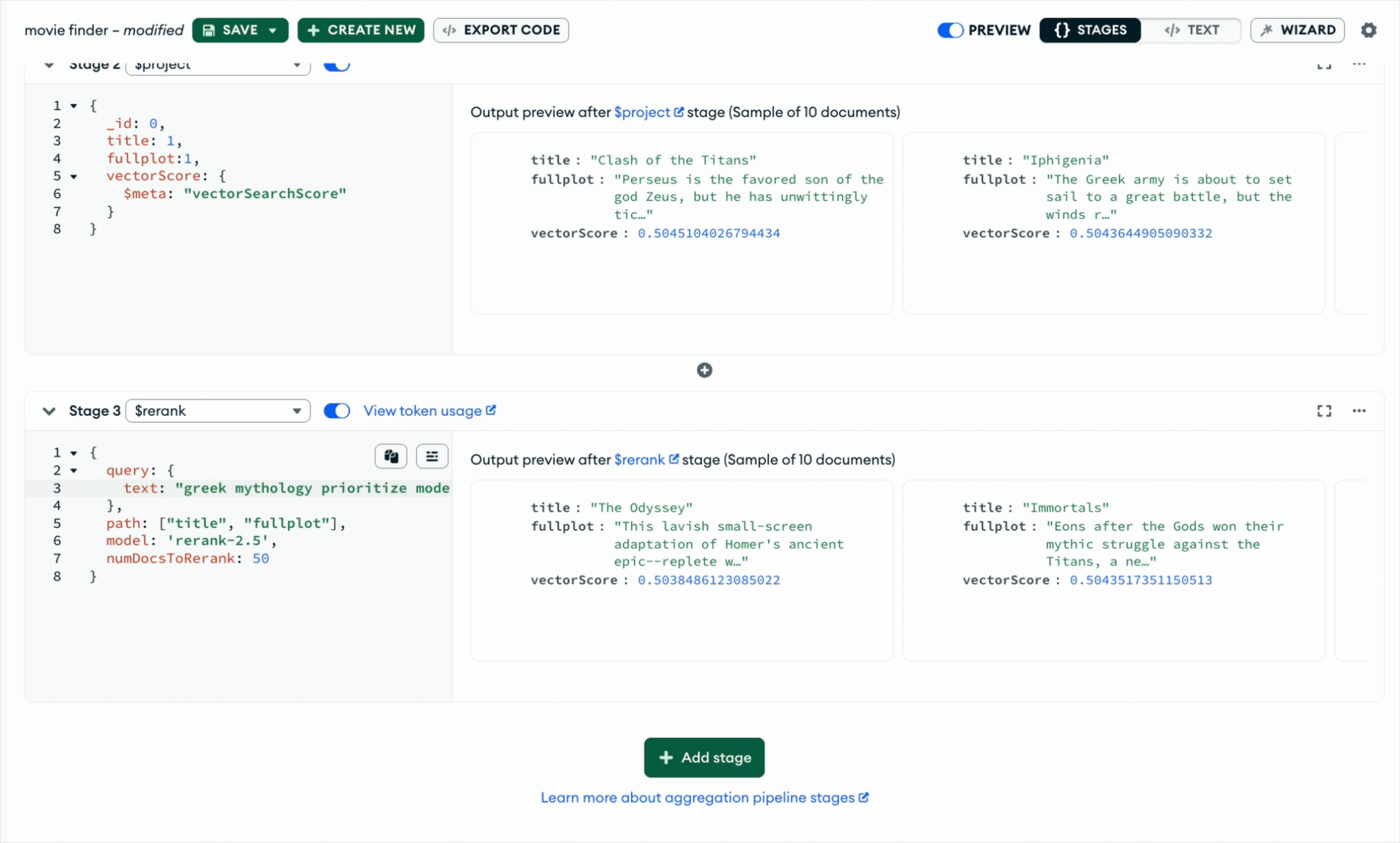
$rerank improves the second stage. A reranker takes a smaller candidate set and re-scores each query-document pair with a cross-encoder model that evaluates them together, then returns the same documents in a better order. In MongoDB, $rerank is a first-class aggregation stage that follows the candidate-generation step and refines results directly in the query path.
Taken together, hybrid search helps surface the right possibilities, and $rerank helps put the best answer on top, improving retrieval quality by up to 30%*.
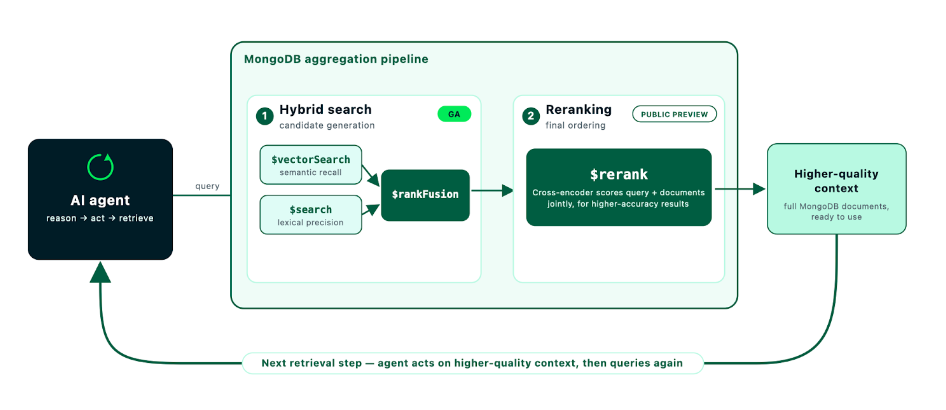
Figure 1. Hybrid search retrieves the candidate set, $rerank reorders the results, and the agent uses the higher-quality context for the next retrieval step.
Why Native Reranking matters
Reranking as a retrieval technique is not new. What is new is where it runs.
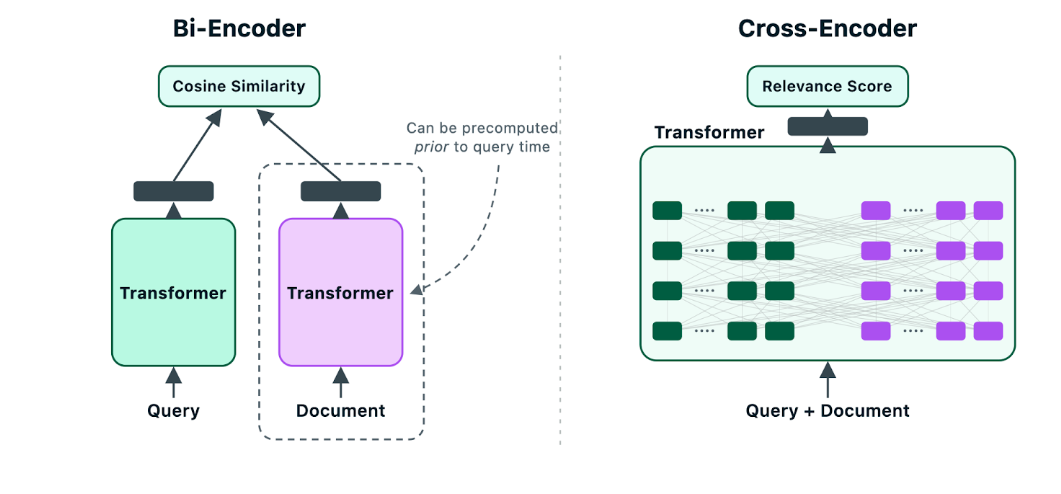
To see why that matters, it helps to distinguish between two related concepts. One is fusion-based ranking like $rankFusion and $scoreFusion, which combine and order results from multiple retrieval methods. The other is reranker models, which take a smaller candidate set and re-score each query-document pair. Because reranker models evaluate the query and document together, they can achieve higher accuracy than vector search over generated embeddings, where documents and queries are processed separately.
In MongoDB, $rerank applies a cross-encoder reranker model to refine the final ordering.
Figure 2. Bi-encoder (embedding model) vs Cross-Encoder (reranker).
In many AI stacks, developers implement reranking as a separate service after the search system returns results. MongoDB brings that capability directly into the query path with $rerank.
For agentic workloads, that matters because retrieval quality affects both output quality and cost. Every irrelevant passage that reaches a frontier LLM is one more chunk of context for the model to read, reason over, and potentially act on. Better reranking helps trim that noise before it reaches the model, so developers are not paying premium inference costs for context that was unlikely to matter in the first place.
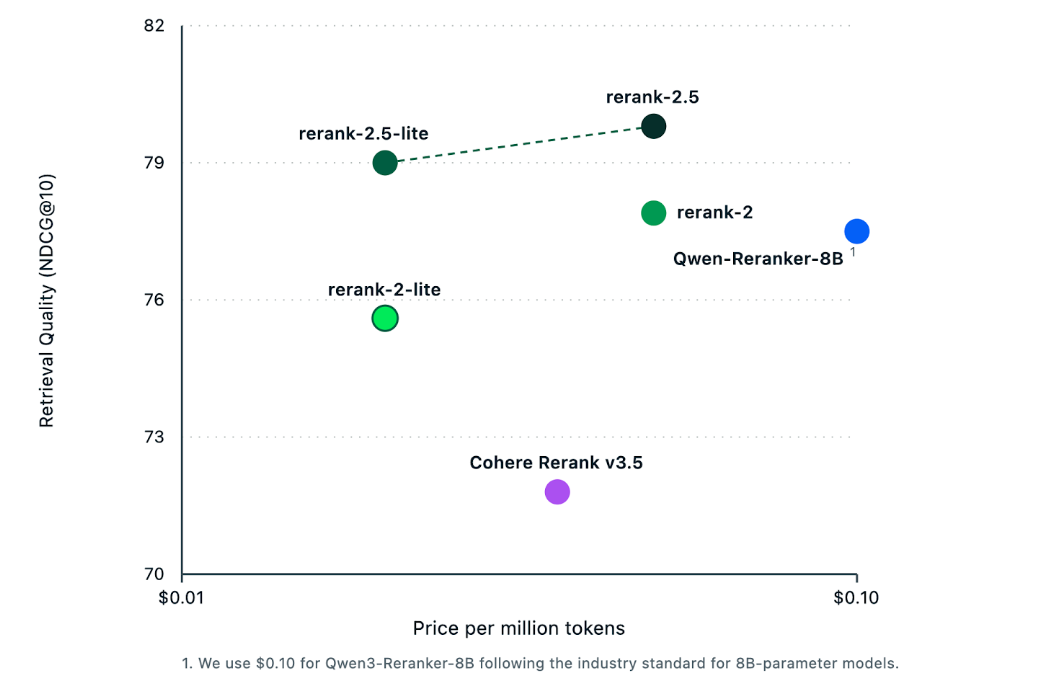
The quality of the reranker matters here, too. MongoDB native reranking is powered by Voyage AI’s rerank-2.5 model, which improves retrieval accuracy by up to 30%*. The model also supports a 32K-token context window, which is important for applications that retrieve longer documents.
Figure 3. Retrieval quality (NDCG@10) versus cost for reranker models.
Just as important, developers can get those retrieval gains without adding another system to manage. In many retrieval stacks, developers have to call an external reranking service after search returns results, manage another API key, add another network hop, and stitch ranked IDs back to full documents in application code. With MongoDB, $rerank runs within the aggregation pipeline on the documents it already holds. There is no separate API client, no extra round-trip, and no second document lookup after the fact.
That changes the trade-off for teams building production AI. Instead of treating reranking as an integration project, they can treat it as an additive query-layer improvement inside the stack they already use.
Improved retrieval results, powered by the MongoDB pipeline developers already use
If you already use MongoDB Search and MongoDB Vector Search, hybrid search and reranking are natural query-layer enhancements: use $rankFusion and $scoreFusion to improve candidate generation, then add $rerank for stronger final ordering where precision matters most. All three slot into the aggregation pipeline that developers already know, alongside stages like $vectorSearch, $search, $match, and $sort. And once $rerank is enabled in Project Settings, no new indexes are required to get started.
There is no separate reranking service to manage and no external fusion logic to maintain. That makes these capabilities easier to try, easier to evaluate, and easier to operationalize in production.
From better candidates to better answers
Hybrid search gets the right information into contention. $rerank helps elevate the best of it. Together, they give developers a more production-ready way to improve retrieval quality for modern AI applications and agents, while keeping the retrieval path inside MongoDB, on the same live operational data their applications already depend on.
Hybrid search is now generally available, including $rankFusion for clusters on 8.0+ and $scoreFusion for on clusters on 8.3. $rerank is available in public preview on 8.3. To use MongoDB 8.3, select “Latest Version with Auto-Upgrades” in the Cluster Builder.
If you are already using MongoDB Search and Vector Search, the next step is simple: start with hybrid search to improve candidate retrieval, then add reranking to refine the final result set where precision matters most.
Next Steps
Visit our Hybrid Search and Native Rerank documentation to learn more.
*Based on Voyage instruction-following rerankers on the MAIR benchmark; improvement measured over first-stage retrieval.