There’s a common theme to the conversations I’ve been having with AI teams lately: change. Constant, head-spinning change. Teams across industries are evaluating and re-evaluating model providers, agent frameworks, and harnesses on a continuous basis.
At MongoDB, we believe that your choice of technology partner—specifically, your data platform—should simplify how you build with AI. It should deliver performance at scale, enable you to build and run anywhere, and it should allow you to choose your own providers and frameworks. This is exactly what MongoDB offers, and it’s why more than 67,000 customers rely on us for their most important applications.
The organizations seeing the most AI success are the ones whose technology stacks are set up for the current pace of change. For example, DevRev’s AgentOS platform is powered by MongoDB Atlas. AgentOS handles billions of requests each month, for everything from AI-assisted insights and analytics to internal communications and development. Relying on MongoDB Atlas has helped DevRev get innovations to market faster, and enables the company to scale seamlessly as it grows.
MongoDB is ideal for agentic AI in two key ways.
First, an agent is only as smart as its context—which requires blending short-term memory, long-term knowledge, and enterprise data. Because this information is highly dynamic and unstructured, JSON is the ideal format. It provides the schema flexibility inherently needed by the data and allows attaching metadata like IDs and confidence scores. MongoDB stores JSON natively and provides the scale and consistency required to run thousands of concurrent agents.
Second, it’s designed for how agents work. As memory accumulates, agents must pinpoint the precise context needed for a request. MongoDB solves this by providing state-of-the-art information retrieval capabilities (search, vector search, hybrid search, embeddings) directly where the operational data already lives, eliminating the need to constantly sync data across separate systems. Customers get high-precision semantic retrieval without the operational headache of managing multiple fragmented products.
A good example of how MongoDB powers agents is ElevenLabs. The company relies on MongoDB Atlas to power the long-term memory and knowledge base for its autonomous agents. By leveraging Atlas Search and Vector Search, ElevenLabs enables their agents to retain complex context and deliver highly personalized interactions in real-time.
Adobe, meanwhile, chose MongoDB as the long-term memory and reasoning layer for Journey Agent, its composite multimodal AI agent that unifies Adobe's marketing suite and orchestrates end-to-end customer journeys. Adobe leverages MongoDB Atlas Search and Atlas Vector Search together to power the sub-100 millisecond hybrid search the agent needs to act in real time.
Defining an open standard for agent memory
Last month, MongoDB partner LangChain announced the launch of Context Hub in LangSmith, a place to store, version, and collaborate on the files that define how agents behave, like AGENT.md and agent skills.
But context engineering goes beyond that. Agents also rely on memory: short-term context captured in states, sessions, and interaction history, and long-term memory that persists across sessions.
Figure 1. Agent memory with MongoDB.
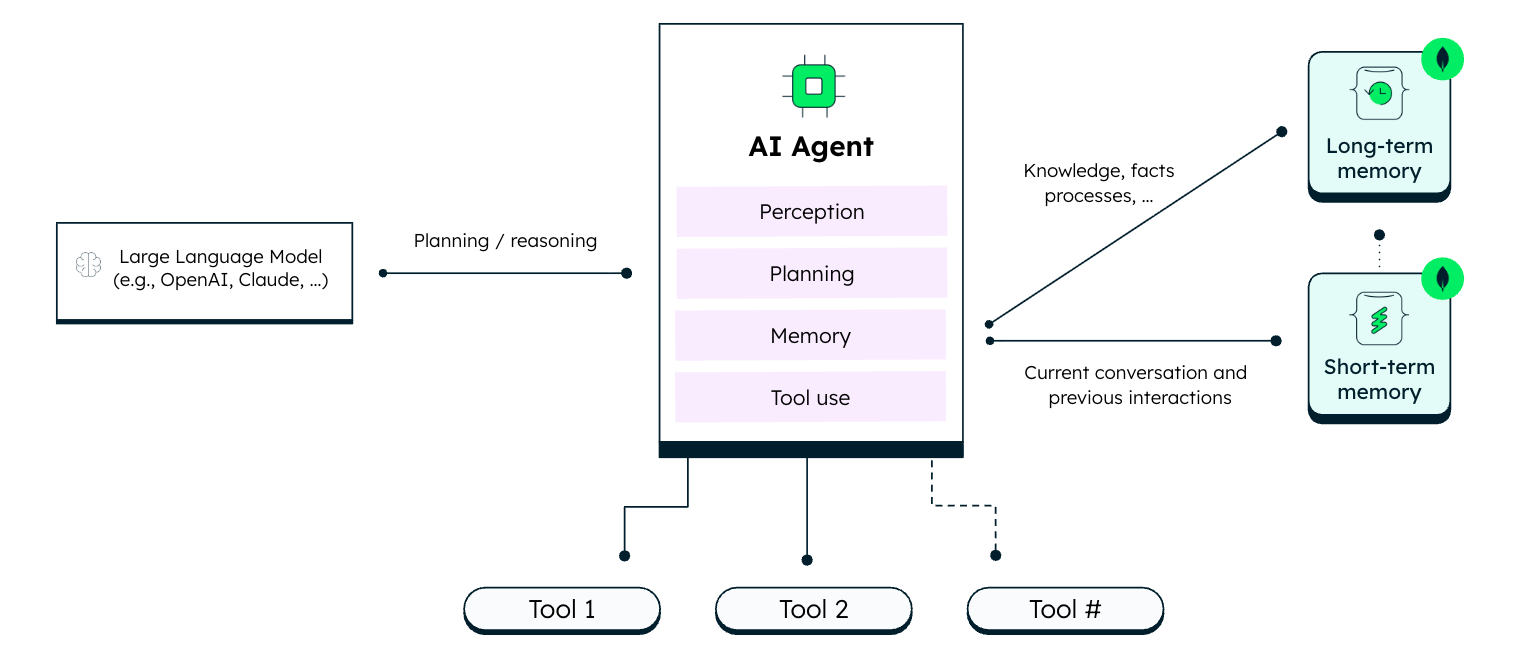
Today, there is no broadly adopted open standard for defining and managing portable agent memory across agent frameworks. Now, MongoDB—alongside LangChain and ecosystem partners—is working on an open reference architecture and contributing toward greater interoperability in this space.
This work will help define what has been missing from the AI ecosystem: shared interfaces, metadata conventions, versioning patterns, and retrieval semantics for the data that differentiate agentic experiences and shape agent behavior.
The aim is to enable organizations to switch model providers or try a new framework on a Tuesday—and not lose Wednesday rewriting memory plumbing. Ultimately, we want to make agent memory and context easier (and faster) to manage.
For customer-facing agents to make real-time decisions, such as responding to a support request or making a policy change, they need contextual information instantly. Not info from a data warehouse that might be 30 minutes old. The context layer needs to be real-time, a required capability we’ve been delivering for tens of thousands of customers going on almost two decades.
MongoDB’s performant, flexible platform = agentic success
The next generation of agents will increasingly be long-horizon systems, running for hours or more. As they take on more complex tasks, context will become even more critical, and agent memory will be central to making them effective.
This will create a demand for diverse, high-performance memory systems, and MongoDB is positioned to provide the flexibility and scalability agents require. With the recent release MongoDB 8.3, our core database has evolved to better support the speed and demands of AI workloads. MongoDB also delivers the retrieval accuracy necessary for agent outputs to be trusted (a non-negotiable for customer-facing applications) while optimizing tokens and cost in production.
Every AI team is currently making a bet about what the future of the agentic stack will look like. The ones betting on a flexible, production-ready data platform like MongoDB—that enables teams to innovate now while ensuring structure and resilience for the future—will be able to pivot quickly. The ones betting on rigid schema designs, or on a smattering of specific models and frameworks, might end up redoing their plumbing instead of shipping products.
Figure 2. Advantages of MongoDB's flexible schema for AI workloads.
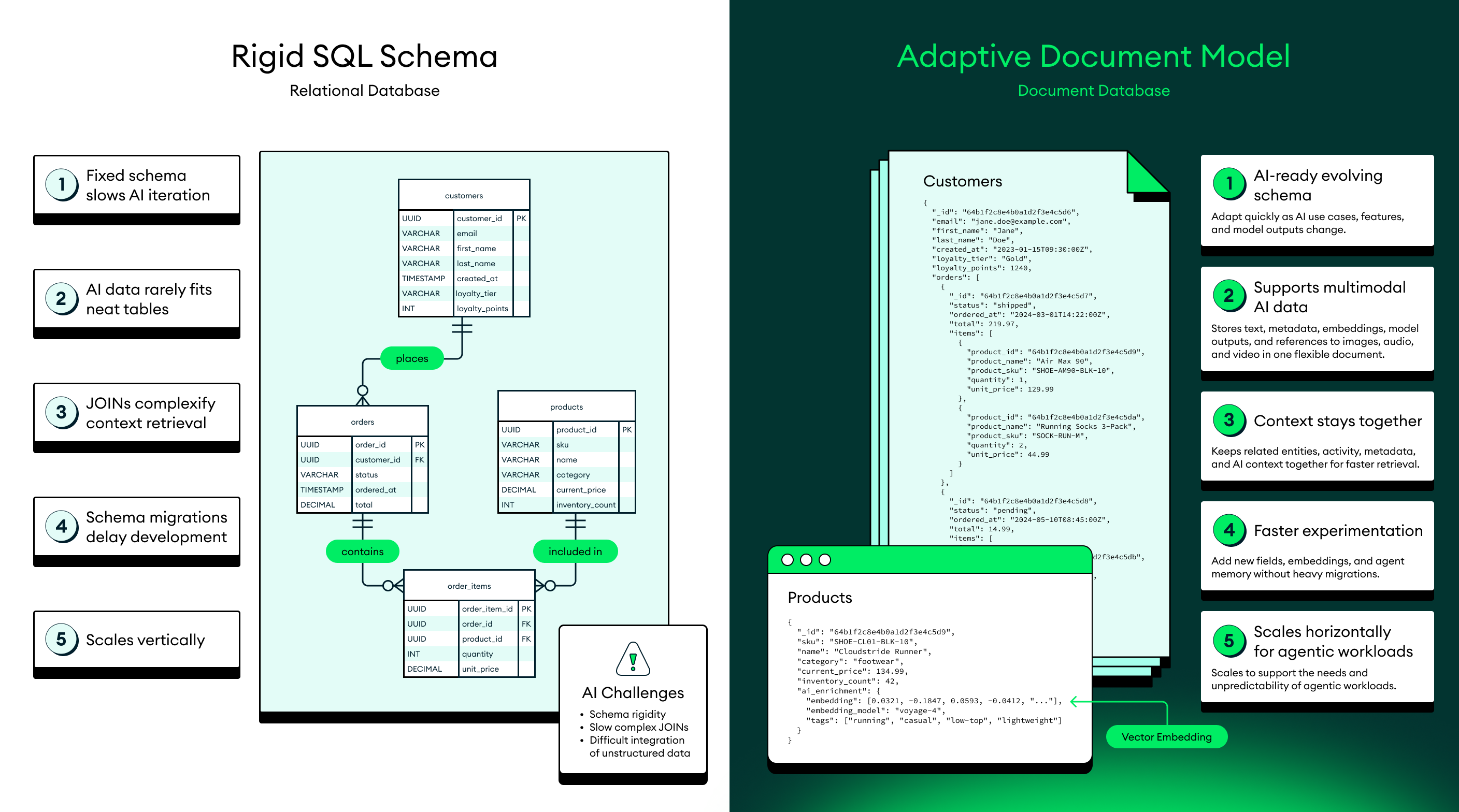
- MongoDB is built for AI: JSON is the lingua franca of AI. The information agents need is highly dynamic and can be structured, semi-structured, and unstructured. MongoDB provides the schema flexibility inherently needed by the data and allows attaching metadata for richer, more precise context. Dynamic, adaptive schemas that evolve in place as fast as thought without breaking what runs on top. The MongoDB document model isn’t adapted for AI; it’s the natural shape of AI data.
- MongoDB offers one data platform: Every data requirement for production AI is natively integrated. Search, vector search, embeddings, hybrid retrieval, time series, and streaming run on the same OLTP foundation 67,000+ customers trust with mission-critical applications—with one API, one security model, one operational footprint.
Next Steps
To learn why the best AI apps are built on MongoDB—and why MongoDB has the flexibility, performance, and security developers need to create transformative AI experiences—see MongoDB for AI.