88% of enterprises are using AI in at least one business function. Fewer than 10% are seeing meaningful business impact. That gap isn't explained by model selection. It isn't explained by prompt quality. It's explained by what's underneath.
Here's the thesis I keep coming back to: in almost every production AI system I've looked at: the bottleneck isn't the model, it's the data architecture underneath it. And until teams stop treating agent failures as model problems and start treating them as data problems, that 10% number isn't going to move.
This shows up at three layers of the data stack: whether data is findable, whether it's current, and whether it persists across steps. Every failure mode below maps to one of those three.
Here's what that looks like in practice. A team builds an agent that demos beautifully. It retrieves relevant documents, chains reasoning steps together, and maintains context across a multi-step workflow. Leadership is impressed. The sprint review goes great.
Then it hits production. Not a dramatic failure. Not a crash. Something worse: inconsistency. Some queries return perfect answers. Others hallucinate. A workflow that worked on Tuesday fails on Thursday with nearly identical inputs. The agent confidently recommends a product that the company discontinued last quarter.
The team does what any good engineering team does. Better prompts. Different temperature settings. Retry logic. Guardrails. Maybe a different model entirely. These are all reasonable things to try. They're also almost certainly aimed at the wrong layer.
McKinsey's State of AI 2025 found that 88% of organizations are now using AI in at least one business function. But only about 6% qualify as "high performers" — McKinsey's term for organizations that attribute more than 5% of EBIT to AI use and report their organization has seen meaningful business impact. That's a staggering gap, and it isn't explained by model selection or prompt quality. It's explained by what's underneath.
Before walking through how this breaks, it helps to see what "touches data" actually means.
Most executives picture an AI agent as the model answering questions. What their team is actually operating is closer to this — a simple customer service agent, four steps, nine data sources, fourteen connections:
Figure 1. Data surface area of an agent flow: Each workflow step reads from and writes to multiple data sources.
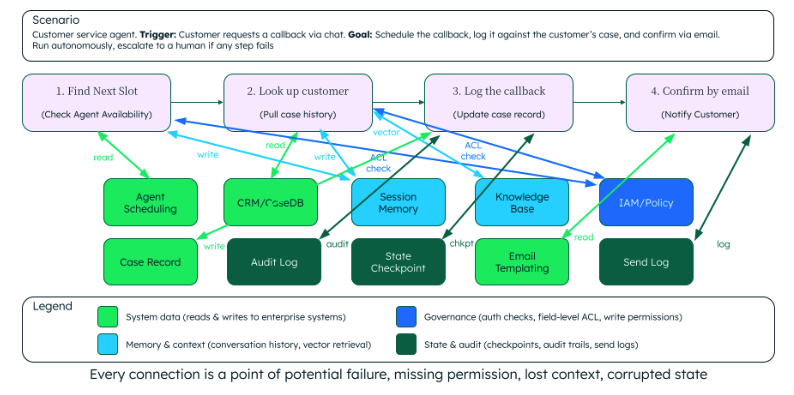
That's the surface area of a workflow simple enough to describe in one sentence. Every connection is a point of potential failure: stale data, missing permission, lost context, corrupted state. And when teams hit those failures in production, they consistently cluster at the three layers named above — whether data is findable, whether it's current, and whether it persists across steps. Each layer fails in a way that looks like something else, which is why they keep getting diagnosed as model problems. Here's each one.
Layer #1: Is your data findable? — "My agent can't find the right information"
This is the one everyone encounters first. You've built a RAG (Retrieval-Augmented Generation) pipeline. You've loaded your documents, set up a vector store, and connected it to your LLM. But the agent keeps pulling irrelevant context, missing obvious answers, or retrieving information from the wrong version of a document.
It looks like a retrieval problem. The chunking strategy is off. The similarity threshold needs adjusting. The retrieval pipeline needs tuning.
But more often than not, you're debugging the wrong layer. Industry analyses of RAG failures in production consistently point to data quality, not retrieval algorithms or language models, as the primary culprit. The retrieval mechanism is working fine. It's faithfully returning the best matches for your query. The problem is that the data it's searching through was never prepared to be retrieved well in the first place.
Philipp Schmid, a staff engineer at Google DeepMind who previously helped grow Hugging Face from zero to roughly $100 million in revenue, has been writing about what he calls context engineering. It's a framework built around seven data components that need to be in place before the LLM is ever invoked: system instructions, user prompts, conversation history, long-term memory, retrieved information, available tools, and structured output formats. His core insight is one that should be printed and taped above every AI team's monitor:
"Most agent failures are not model failures anymore; they are context failures."
Think about what that means. The distinction between a "cheap demo" agent and a "magical" one isn't the model. It isn't the prompt. It's whether the data preparation pipeline exists. Context engineering isn't a new discipline. It's data engineering wearing a new hat.
And this applies equally to unstructured data and structured data. The question isn't "is your data in rows and columns?" It's "Is your data retrieval-ready?" A well-maintained knowledge base with rich metadata, clear boundaries between concepts, and regular freshness checks works great with RAG, even though it's entirely unstructured. A messy SharePoint dump with 47 versions of the same document and no tagging will poison any retrieval pipeline you put it through, regardless of how sophisticated the model is.
We've seen this movie before. In the early days of search engines, everyone thought the ranking algorithm was the magic. AltaVista, Lycos, and Excite were all working on better ways to match keywords. But Google didn't win because they had a better search algorithm. They won because they understood the web's link graph. PageRank was a data insight, not a search algorithm insight. It treated the structure of links between pages as a signal for relevance, and that turned out to matter more than any keyword-matching improvement. The same pattern is playing out with AI agents today. The teams that win won't be the ones with the best models. They'll be the ones whose data is ready for those models to use.
Meta's engineering team recently demonstrated what this looks like in practice. They built over 50 specialized AI agents, not to serve end users, but specifically to map the "tribal knowledge" buried in their data pipelines. Knowledge that previously lived only in individual engineers' heads. The result: they went from 5% to 100% code module coverage and cut agent tool calls by 40%. Three rounds of critical agents improved quality scores from 3.65 to 4.20 out of 5.0, with zero hallucinations on file path references.
Meta didn't tune prompts. They didn't swap models. They made the data itself legible to agents. That was the fix.
The question this layer forces: can your retrieval layer actually find what it's looking for? Is the metadata rich enough? Are the boundaries between concepts clear? Is it current? If you can't answer those confidently, start there. The retrieval pipeline can only return what the data layer gives it to work with.
Layer #2: Is your data current? — "My agent gives different answers every time"
This one is more insidious because the diagnosis feels so obvious. The LLM is non-deterministic. Outputs vary between runs. The natural instinct is to reach for tighter output parsing, stricter few-shot examples, or a model known for more consistent behavior.
But what if the model isn't the inconsistent part? What if it's being perfectly consistent, and the data underneath is the thing that's shifting?
The world changes. The data doesn't. And the model faithfully reflects whatever reality the data presents, even when that reality is three months out of date.
Informatica's CDO Insights survey reinforces the scale of this problem: 42% of data leaders cite data quality as the primary obstacle to GenAI adoption, and 99% of GenAI adopters encountered roadblocks during implementation. The examples are everywhere. Recommendation engines serving products that are out of stock. Pricing agents are quoting rates from last quarter's catalog. Customer service bots are referencing policies that were updated months ago. The model isn't wrong in any of these cases. The data is.
Gartner makes the timeline concrete: organizations will abandon 60% of AI projects unsupported by AI-ready data, and 63% of organizations either don't have or aren't sure they have the right data management practices for AI. "AI-ready" is, at bottom, a freshness claim. Data that was current when you indexed it last quarter isn't AI-ready today.
Glen Rhodes, writing on his blog in March 2026, coined a useful term for this: data freshness rot. As he puts it:
"Three months later, the system is confidently wrong about a third of what users ask. Nobody changed the model. Nobody touched the prompts. The world moved, and your knowledge base didn't."
That word "confidently" is doing a lot of work in that sentence. The system doesn't throw errors when the data goes stale. It doesn't flag uncertainty. It returns answers with the same confidence it always did. You don't know it's wrong until a customer tells you. Or worse, until the losses show up in a quarterly report.
And here's why this compounds: Kyndryl's research on agentic AI drift frames this not as a bug but as a law of nature. APIs deprecate. Policies update. Business rules evolve. Any static snapshot of knowledge becomes wrong over time. It's not a question of if, it's a question of how fast. Your system isn't failing because you made a mistake. It's failing because static data in a dynamic world is a fundamental architectural mismatch.
Now layer on the math, because this is where the picture gets really uncomfortable. If each step in an agent workflow succeeds at 85% — a reasonable-sounding rate in isolation — a 10-step workflow succeeds end-to-end only about 20% of the time. Probabilities multiply. They don't add.
Figure 2. How reliability decays with each added step: Illustrative example - at 85% accuracy, end-to-end success decays.
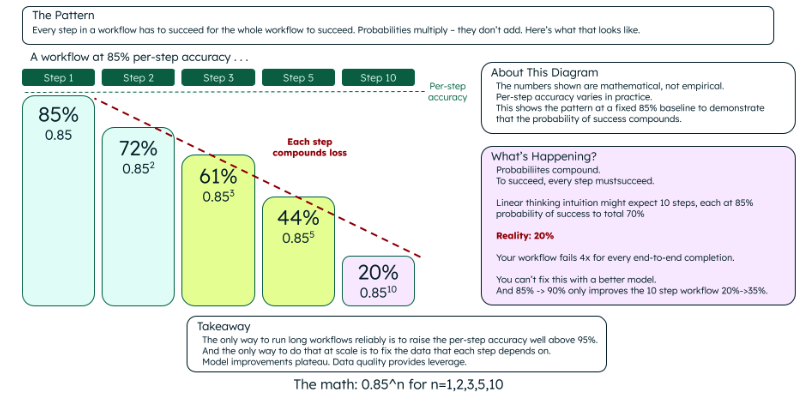
The pattern is brutal and unintuitive. Moving from 85% to 90% per step only lifts end-to-end success from 20% to 35%. That 98% threshold — where 10-step workflows finally become reliable — is a data quality requirement, not a model capability requirement. Prodigal Tech calls this "the compounding error problem." You can't prompt-engineer your way out of compound probability.
I managed the hp.com tech stack when we had 85 data centers spread around the world, including the data consistency challenges of running the 2008 Olympics campaign with a 3-second global page load requirement. Data consistency across distributed systems was the hardest problem in computing then, and it's the hardest problem now. The AI part is new. The data consistency part is as old as distributed systems themselves.
The question this layer forces: can your freshness monitoring catch data drift before your agent does? Map your data freshness. Identify which inputs are drifting. Don't reach for prompt engineering. The model is probably doing exactly what you asked, with data you didn't realize had gone stale.
Layer 3: Does your data persist? — "My agent loses track of what it's doing"
The third disguise is the subtlest. Your agent needs to check a calendar, pull a CRM record, update a support ticket, and send a confirmation. Midway through, it loses context. It forgets a decision it made two steps ago. It repeats work. It fails silently on a permission check and proceeds without the data it needed.
It looks like an orchestration problem. The agent framework can't maintain context. Maybe you need a better memory system, a different architecture, or a more sophisticated planning layer.
But peel it back one layer. What's actually happening at each failure point?
Composio, a $29 million-backed platform building agent infrastructure, is instructive here. What looks like an agent integration problem is almost always a data problem wearing different clothes. Authentication is really data access control. Multi-tenancy is really data isolation. Observability is really data lineage. Three different words for three different cuts of the same underlying question: who can read what, when, and in what order?
There's a key architectural insight here that most teams miss. Legacy automation platforms like Zapier, Make, and n8n were designed for deterministic workflows. Fixed triggers, fixed sequences, predictable outputs. When you build a Zapier workflow, you know exactly which steps will execute and in what order. You can trace the data flow with your eyes closed. AI agents operate probabilistically. The LLM dynamically decides which tools to call and in what order based on context.
Two identical inputs might produce different execution paths. That architectural mismatch means the data layer underneath has to be fundamentally different from what we've built for traditional automation. The data layer needs to support dynamic access patterns, maintain consistency across non-deterministic execution paths, and preserve context even when the agent takes a route you didn't anticipate. The agent isn't "losing state." It never had a coherent data layer to maintain state in.
GitHub's engineering blog arrives at the same conclusion from a different angle. Their team documented why multi-step agent workflows break down in production, and the failures aren't in the agent logic or the LLM reasoning. They're in the handoffs between steps, where context gets lost, permissions don't carry forward, and state isn't persisted in a way the next step can use. Those are all data layer problems. Its engineers at a major platform independently confirm that multi-agent failure is an infrastructure problem, not an intelligence problem.
We've solved the state problem before, multiple times. HTTP was stateless, so we invented sessions, cookies, and eventually JWT tokens. Databases were single-node, so we invented replication, sharding, and distributed consensus. Mobile apps needed an offline state, so we built sync engines and conflict resolution protocols. Every time this industry hits a state management problem, the answer has been a new data primitive. Not a smarter application layer. Not better logic. A new way to persist, share, and reason over state at the data level. We're at that same inflection point with AI agents. The primitive just doesn't exist in most organizations yet. Building it is the actual work.
The question this layer forces: can your state architecture survive the path the agent actually takes? Not the happy path. The messy one, with permission checks that fail and tool calls that time out, and context that has to carry forward across unpredictable sequences.
Why heavier AI spending isn't the answer
Zoom back out to McKinsey's numbers, and they hit differently. 88% adoption. 10% transformation. The gap between them isn't a model-spending problem or a talent problem — it's what happens when organizations try to bolt agents onto data architecture that was never designed to be read, updated, and reasoned over at runtime. McKinsey's research consistently finds that high performers are more likely to have redesigned workflows, and "workflow redesign" for agents is, underneath, data architecture redesign.
Prompt engineering is starting to feel like polishing the UI while the database is on fire. It's productive work. It's visible work. You can iterate on it in minutes, see results immediately, and feel like you're making progress. But for most teams, it's optimizing the wrong layer. The returns from better prompts plateau quickly when the data underneath is the constraint. And by the time you realize it, you've spent months fine-tuning the one part of the stack that wasn't actually broken.
Your Monday-morning move
You don't need to redesign your data architecture to act on this. You need to see it.
Before your next AI investment review, pick one existing agent — in production or pilot — and ask your team to map its data touchpoints on one page. Every read. Every write. Every permission check. For every step. If they can't produce that map in a week, you don't have a data problem you can solve yet. You have a data architecture you can't see. Start there.
The three questions below are what the map is trying to answer:
Is our data retrieval-ready? Not "do we have a vector store," but is our data well-maintained, properly tagged, and semantically clear enough that an agent can reason about what's relevant? This applies to unstructured documents and structured databases alike.
Is our data fresh? Not "did we load it once," but do we have pipelines that keep it current, and observability that tells us when it's drifted?
Is our data architecture agent-aware? Not "can our agent call APIs," but does our data layer support the read-write-reason pattern that agentic workflows require?
If you can't answer yes to all three, you don't have an AI problem. You have a data problem wearing an AI disguise.
The 10% who figured this out aren't smarter about AI. They're smarter about data. And that's a skill set this industry has been building for decades. We just need to remember to use it.
Next Steps
Visit our solutions page to learn more about how MongoDB can support AI use cases.
Appendix: Sources
Primary sources
McKinsey, "The State of AI in 2025: Agents, Innovation, and Transformation" https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
Informatica, CDO Insights Report (January 2024) https://www.informatica.com/about-us/news/news-releases/2024/01/20240131-new-research-from-informatica-reveals-more-data-leaders-plan-to-capitalize-on-generative-ai-but-data-quality-remains-the-key-obstacle-to-adoption.html
Gartner, "Lack of AI-Ready Data Puts AI Projects at Risk" (February 2025) https://www.gartner.com/en/newsroom/press-releases/2025-02-26-lack-of-ai-ready-data-puts-ai-projects-at-risk
GitHub Engineering Blog, "Multi-agent workflows often fail. Here's how to engineer ones that don't" (February 2026) https://github.blog/ai-and-ml/generative-ai/multi-agent-workflows-often-fail-heres-how-to-engineer-ones-that-dont/
Meta Engineering, "How Meta Used AI to Map Tribal Knowledge in Large-Scale Data Pipelines" (April 2026) https://engineering.fb.com/2026/04/06/developer-tools/how-meta-used-ai-to-map-tribal-knowledge-in-large-scale-data-pipelines/
Philipp Schmid, "The New Skill in AI is Not Prompting, It's Context Engineering" (June 2025) https://www.philschmid.de/context-engineering
Composio, "Outgrowing Zapier, Make, and n8n for AI Agents" https://composio.dev/content/outgrowing-make-zapier-n8n-ai-agents
Secondary sources
Glen Rhodes, "Data Freshness Rot as the Silent Failure Mode in Production RAG Systems" (March 2026) https://glenrhodes.com/data-freshness-rot-as-the-silent-failure-mode-in-production-rag-systems-and-treating-document-shelf-life-as-a-first-class-reliability-concern-4/
Kyndryl, "Agentic AI Risk and How Enterprises Can Prevent Drift" (March 2026) https://www.kyndryl.com/us/en/insights/articles/2026/03/preventing-agentic-ai-drift
Amarnath Byakod, "Why RAG Systems Fail in Production" (February 2026) https://medium.com/@abyakod/why-rag-systems-fail-in-production-part-2-security-scale-data-quality-and-cost-999e17dd5b36