Many modern semantic search and retrieval augmented generation (RAG) applications handle large volumes of multimodal and unstructured data. However, ensuring that the data is “AI ready” can be challenging without the right strategies in place. It’s important to have a way to ensure that large volumes of data can be easily ingested by large language models (LLMs) to enable efficient and accurate retrieval. Chunking your data is a solution to these challenges. In this article, we’ll go over what chunking is, and how it can optimize working with the data that powers AI applications.
What is chunking?
Chunking improves and optimizes LLM retrieval accuracy and LLM processing through breaking large documents into smaller, manageable pieces, which can be fed to the LLMs. Most use cases currently involve using LLMs to answer questions about large, highly structured documents such as technical documentation and onboarding documents, but multimodal data (such as audio, videos and more) can be chunked as well.
Chunking is a fundamental technique that enhances the efficiency, accuracy, and scalability of AI-driven applications. By structuring data into well-defined segments, AI models can retrieve and process information more effectively, resulting in better performance, lower costs, and improved user experiences. Whether in retrieval-based AI, vector search, or large-scale natural language processing (NLP) tasks, chunking is a crucial strategy for optimizing AI workflows.
What are the benefits of chunking?
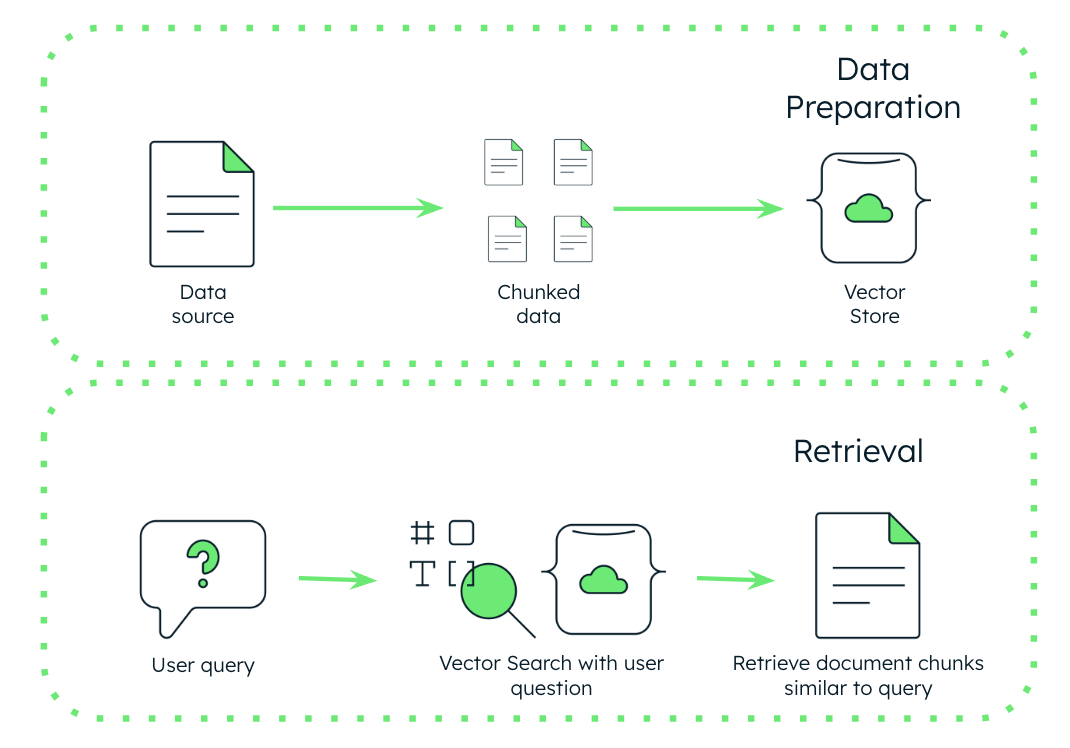
Chunking helps ensure accurate retrieval by allowing embedding models to focus on relevant sections of text rather than analyzing an entire dataset at once. This improves search precision and enhances the quality of retrieved information before it is passed to an LLM for processing. This targeted approach improves the overall efficiency of retrieval processes by reducing the cognitive load on the model and preventing unnecessary computations on irrelevant data. Well-structured chunks help optimize how the data is stored, indexed, and retrieved by ensuring that each chunk contains a meaningful unit of information while avoiding redundancy. This leads to improved precision (retrieving only the necessary information) and recall (retrieving all relevant information), both of which are critical for enhancing the performance of systems that rely on semantic search, question answering, and RAG.
In particular, more meaningful chunks minimize the likelihood of omitting vital context, as the system can better preserve semantic relationships between concepts and ideas within smaller sections. For example, in semantic search tasks, chunking allows the AI to prioritize data that has a direct semantic connection to the query, improving the chances of retrieving the most relevant documents or responses. This leads to more precise search results, enabling AI applications to deliver answers that are both accurate and contextually rich, enhancing user satisfaction and operational efficiency.
Cost optimization and operational efficiency are additional significant benefits of chunking, particularly when working with large datasets. By breaking down data into smaller chunks, you reduce the computational overhead of processing large documents in their entirety. In NLP tasks such as sentiment analysis, translation, or named entity recognition, it is far more efficient to process smaller chunks individually than to handle an entire document at once. Processing entire documents can be computationally expensive, especially with large-scale artificial intelligence/machine learning (AI/ML) models, leading to longer processing times and higher resource consumption. By leveraging chunking, models can handle smaller sections of data at once, enabling faster response times and more efficient use of computational resources.
Additionally, with the growing adoption of cloud computing and distributed AI systems, chunking makes it easier to balance workloads across multiple servers or processors. This enables parallel processing of chunks, enhancing the speed and responsiveness of AI applications, particularly in real-time processing scenarios. As a result, organizations can scale their AI/ML workflows without the risk of performance bottlenecks, ultimately lowering infrastructure costs while improving the overall speed and accuracy of data retrieval.
Chunking and tokenization
Chunking and tokenization are both key components of the data preparation that is done so that external knowledge can be processed and stored efficiently. Both chunking and tokenization involve breaking down text data, but they serve different purposes and operate at different levels of data processing.
What are tokens and tokenization?
In NLP and AI, tokens are the fundamental units of text that a model processes. A token can represent a word, subword, or even a character, depending on the tokenization method used.
For example, in the sentence, "Chunking improves AI retrieval":
- if tokenized by words, the tokens might be: ["Chunking", "improves", "AI", "retrieval", "."] (5 tokens).
- if tokenized by subwords, it might break into smaller units: ["Chunk", "ing", "im", "proves", "AI", "retriev", "al", "."] (8 tokens).
- if tokenized by characters, each letter and punctuation mark becomes a token.
Tokenization is the process of breaking text into smaller units, such as words, subwords, or characters, and converting them into numerical representations that an LLM can process. This step is fundamental to how LLMs interpret language, allowing them to recognize patterns, understand context, and establish relationships between words.
Tokenization also plays a key role in computational efficiency and cost. AI models process text token by token, meaning longer inputs require more computation, increasing processing time and resource consumption. Optimizing token usage can significantly reduce costs and improve system responsiveness, especially for large-scale applications.
The way text is tokenized can also impact the meaning and accuracy of AI-generated content. Different tokenization strategies influence how well a model understands and constructs text. This improves language understanding, particularly in complex or technical texts.
Why are tokens important?
AI models, especially LLMs, do not process raw text directly. Instead, they convert text into tokens, which are then mapped to numerical representations (embeddings) before being processed. This transformation allows models to analyze and generate text effectively, breaking down language into smaller, manageable units.
Tokens are fundamental to many AI-driven applications. In chatbots and LLMs, they determine how much context the model can retain in a single exchange. In search and retrieval systems, efficient tokenization enables faster, more precise document retrieval. In machine translation and text summarization, tokenization ensures that sentences are broken down effectively for better linguistic processing while preserving semantic integrity.
One crucial factor in token-based processing is the context window—the maximum number of tokens a model can analyze at once. For example, a model with a 5,000-token limit can only consider text up to that length before losing earlier context. This limitation makes efficient chunking and token management essential for ensuring that AI-generated responses remain relevant and coherent.
How do tokens work with LLMs?
Every LLM operates within a token limit, which defines the maximum number of tokens it can process at once. This includes both input text and the model’s generated output. If the total number of tokens exceeds the limit, the text is cut off, potentially leading to incomplete responses or loss of context.
Because tokenization varies based on the language and structure of the text, different words and phrases translate into different numbers of tokens. Simple words like "the" may count as a single token, while a phrase like "artificial intelligence" might be broken into multiple tokens.
Furthermore, tokens get expensive because processing them takes up a lot of computing power, memory, and time. Bigger models need massive GPU resources, which drives up electricity costs and puts strain on hardware. The longer the input or output, the more tokens get used, which makes everything even more resource-intensive. On top of that, AI services charge based on token usage, so longer interactions mean higher costs. As AI keeps evolving, finding ways to use tokens more efficiently is key to keeping costs under control without sacrificing performance.
Additionally, languages with complex scripts, such as Chinese or Arabic, may have entirely different tokenization patterns compared to English. Understanding these differences is crucial when working with multilingual models or designing AI applications that require precise language processing.
How are chunking and tokenization related?
In a retrieval-augmented generation (RAG) workflow, chunking and tokenization are related but serve distinct purposes in processing source data for effective retrieval and generation. Chunking involves dividing the raw data into smaller, semantically meaningful segments to facilitate efficient indexing and retrieval. The size and structure of these chunks can significantly impact the quality of retrieval, as overly large chunks may contain unnecessary information, while excessively small ones create chunks may lack sufficient context.
Once the source data has been chunked, each chunk undergoes tokenization, where it is converted into discrete tokens based on the vocabulary of the specific tokenization model used. The number of tokens per chunk is crucial because it determines how much information can fit within the context window of the large language model (LLM) used in the RAG pipeline. If a chunk exceeds the model's token limit, it may need to be truncated or split further into smaller segments to ensure it fits within the model’s constraints.
Following tokenization, each chunk is transformed into a vector representation using an embedding model. This step is essential for efficient semantic similarity and search, as the embedding captures the semantic meaning of the chunk in a high-dimensional space. These vector representations are then stored in a vector database, where they can be efficiently retrieved based on relevance when a user query is processed. The retrieval step typically involves performing a similarity search, such as cosine similarity or nearest neighbor search, to find the most relevant chunks that will be included in the LLM’s context window for response generation.
Choosing the right chunking strategy
When preparing your data for LLMs, there are a few different chunking strategies you can employ for lengthy documents in order to better preserve context, get more accurate responses, and deliver relevant results. Finding the right chunking strategy depends on the type of data, the task, and the structure of the LLM. Below are various chunking strategies that you can use.
Chunking techniques
Splitting data into chunks determines where the chunk boundaries will be placed—based on paragraph boundaries, programming language-specific separators, tokens, or even semantic boundaries. There are several chunking methods for splitting content into chunks, each with its own advantages and trade-offs.
Natural language-aware chunking
This method uses natural language processing (NLP) techniques to break up text while keeping the natural flow of language intact, making sure sentences and phrases don’t get awkwardly cut off.
This chunking technique ensures that text is broken up in a way that maintains natural language flow, preventing sentences and phrases from being awkwardly cut off through maintaining precise sentence boundaries. It enhances readability—better context preservation preserves meaning and improves the coherence of processed text, making it particularly useful for tasks like summarization, translation, and conversational AI.
Sentence-based chunking
This method splits the text by sentences, which works well when you need to process or analyze text at the sentence level while keeping meaning intact.
By splitting text at sentence boundaries, this chunking technique maintains the integrity of individual thoughts, making it ideal for applications that analyze text at the sentence level, such as sentiment analysis, machine translation, and sentence embedding generation. Since each chunk is a complete sentence, the meaning of resulting chunks remains intact without requiring additional reassembly.
Paragraph-based chunking
This method chunks text by paragraphs, keeping related ideas together and making sure the context isn’t lost in the process.
This chunking technique keeps related ideas together by chunking text at paragraph natural sentence boundaries, ensuring that the broader context of each topic is preserved. It is especially useful for tasks requiring deeper contextual understanding, such as summarization, information retrieval, and long-form content processing.
Semantic chunking
Instead of breaking up text based on fixed rules, this one looks at meaning and context, making sure related ideas stay together so chunks make sense on their own.
Unlike rule-based methods, this chunking technique uses meaning and context to group related information, preserving context and ensuring that each chunk makes sense independently. This approach preserves semantic meaning and integrity and is beneficial for knowledge retrieval, document summarization, and AI applications where maintaining thematic consistency is crucial.
Recursive chunking
This method starts with big chunks (like paragraphs) and keeps breaking them down into smaller ones (sentences, phrases, etc.) until they fit within the needed size, all while keeping things readable.
This chunking technique preserves the logical structure of a document by ensuring that related information stays together, making it particularly useful for RAG systems and long-context processing. By breaking text down hierarchically it minimizes the risk of cutting off important contextual relationships, ultimately improving the relevance of search results. Additionally, it reduces the loss of meaning that often occurs with fixed-size chunking, making it a more effective approach for handling large and complex documents in language models.
Recursive chunking with overlap
Here, chunks overlap a bit, and the text is refined in multiple passes to keep everything well-connected—great for things like search indexing where you don’t want to miss key details.
By allowing chunks to overlap and refining them in multiple passes, this chunking technique ensures better connectivity and reduces information loss. It is particularly useful in search indexing, document retrieval, and AI applications where capturing key details across chunk boundaries improves relevance and accuracy.
Sliding window chunking
Here, each chunk overlaps with the previous one to keep context intact, which is super useful for models that rely on continuity.
This chunking technique keeps context intact by overlapping each chunk with the previous one, making it highly effective for language models that require continuity. It helps prevent loss of important context at chunk boundaries, improving performance in text generation, dialogue systems, and long-context reasoning tasks.
Chunk size
Selecting the right chunk size is crucial for optimizing how LLMs process and retrieve information. Since different models have varying token limits, it’s important to ensure that your chunks fit within these constraints. If your chunks are too large, they risk being truncated; too small, and they may not retain enough context for meaningful retrieval. For RAG, the optimal chunk size should be small enough to fit multiple relevant pieces of information within a prompt, ensuring the model has enough context to generate accurate responses.
The optimal chunk size depends on the specific task. For applications that require sentence-level processing, such as sentiment analysis or translation, a chunk size of 100-300 tokens works best. Retrieval and search tasks typically perform well with chunks in the 200-500 token range, striking a balance between speed and contextual relevance. If you’re working with summarization, a larger chunk size—500-2,000 tokens—allows the model to capture broader context without losing coherence. For text generation tasks like storytelling or answering broad questions, even larger chunks (1,000+ tokens) help maintain logical flow and keep responses well-structured.
Ultimately, choosing the right chunk size often requires experimentation. Running tests on retrieval accuracy, processing efficiency, and model output coherence can help determine the optimal chunking approach for your data. For embedding-based retrieval, evaluating how chunk size affects similarity search performance is especially important. In many cases, a dynamic chunking strategy—where chunk sizes adapt based on text structure—yields the best results. By fine-tuning chunk sizes to match your AI application's needs, you can improve efficiency, ensure high-quality retrieval, and optimize the performance of your LLM-powered workflows.
Chunk overlap
Chunk overlap is a technique used for context preservation across chunks by ensuring that a portion of one chunk carries over into the next. This method helps mitigate the risk of losing key details when splitting text and prevent fragmented or incomplete responses. Without overlap, important information that falls near the chunk boundary could be lost, making it harder for models to generate coherent and contextually relevant output from user queries. By maintaining continuity between chunks, overlap improves the accuracy and consistency of AI-driven tasks, particularly in scenarios where context preservation is critical.
One of the primary advantages of overlapping chunks is its impact on vector search and embedding-based retrieval. When text is split into separate chunks and stored as embeddings in a vector database, slight variations in phrasing or sentence placement can cause key details to be omitted from search results. By incorporating overlap, models increase the chances of retrieving relevant information, as each chunk retains additional context from the preceding one. This is particularly beneficial in RAG applications, where maintaining logical flow between chunks can significantly improve response quality.
Overlap is especially useful in documents that follow a sequential or logical structure, such as narratives, technical documentation, and conversational data. The same applies to structured documents like legal texts, research papers, financial reports, and code examples where sections reference earlier content and losing these connections could impact comprehension.
Choosing the right overlap size depends on the task and model constraints. A small overlap (e.g., 10-20% of the chunk size) may be sufficient for general information retrieval, while longer overlaps may be necessary for tasks that require deeper contextual understanding. However, excessive overlap can lead to redundancy, increasing storage and computation costs, particularly when working with large datasets. Striking a balance between overlap, chunk size, and efficiency ensures that models retain critical context while remaining performant.
By strategically using chunk overlap, AI applications can enhance text retrieval, improve the semantic coherence of generated responses, and maintain logical continuity across split data, leading to more accurate and meaningful interactions with LLMs.
Chunked data and RAG
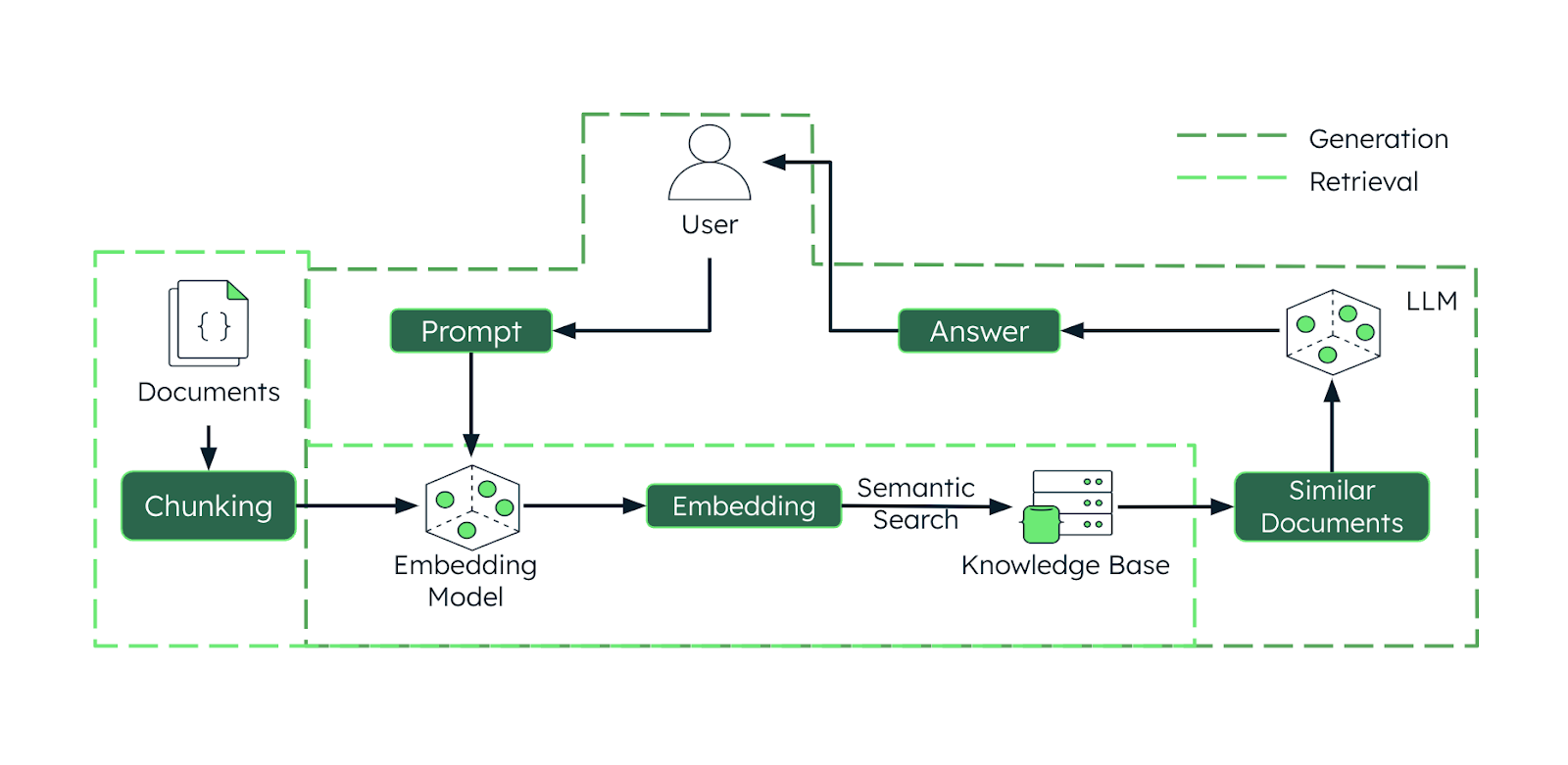
In a retrieval-augmented generation (RAG) workflow, chunked data plays a crucial role in improving search accuracy, relevance, and response quality by structuring unstructured information into manageable segments that can be efficiently indexed, retrieved, and processed. Well-designed chunks ensure that the retrieval system can locate and surface the most contextually relevant information while minimizing noise, thereby enhancing the language model’s ability to generate precise and contextually appropriate responses.
Once data is chunked, each of the chunked documents can be converted into embeddings using an embedding model. These embeddings are then stored in a vector database. Instead of scanning entire documents, the system retrieves the most relevant chunks based on their similarity to a user’s query, improving both speed and accuracy.
When a user submits a query, the LLM first converts it into an embedding and then searches the vector database for the most relevant chunks based on similarity scores. These high-ranking chunks are retrieved and used to provide context for the LLM’s response. This process ensures that the model focuses only on the most pertinent information, rather than processing an entire dataset.
To further refine retrieval results, reranking models can be used. These models reorder retrieved chunks based on relevance, ensuring that the most important information is prioritized before being fed into the LLM. This step helps improve response quality, particularly in complex queries where multiple chunks may contain useful but varying degrees of relevant information.
Working with chunked data in MongoDB
While chunking data is great for getting your data “AI ready,” efficiently organizing and retrieving context-rich data at high velocity is critical for creating and managing AI-enhanced applications.
With MongoDB, you can perform data retrieval and vector search together, eliminating architectural complexity and improving AI accuracy. Voyage AI’s embedding models and rerankers allow you to easily derive underlying meaning from data and provide semantic-based capabilities to your AI applications, and Atlas Vector Search lets you store and search operational data alongside vectors, enabling RAG to access the most relevant data and provide accurate insights.
Once you produce chunks of data that can fit into an LLM’s context window, you can define the context of encoded data. Voyage AI, which is now part of MongoDB, converts that into embeddings and stores them in MongoDB, enabling efficient searching and retrieval of accurate and relevant information. Atlas Vector Search can then be used during a RAG workflow or semantic search to find the most relevant results, providing precise, context-aware answers that come from user queries.
Start building today—simplify building AI-powered applications and create more value using the fully-managed, secure database, integrated with a vast AI partner ecosystem, including all major cloud providers, LLM model providers, and system integrators.
Resources:
Explore MongoDB Atlas—the vector database with built-in search, vector, and more capabilities, register for free now.
To learn more about Voyage AI, read the announcement.
Get strategic advice and implementation support for search and AI stack by visiting our MongoDB AI Applications Program.