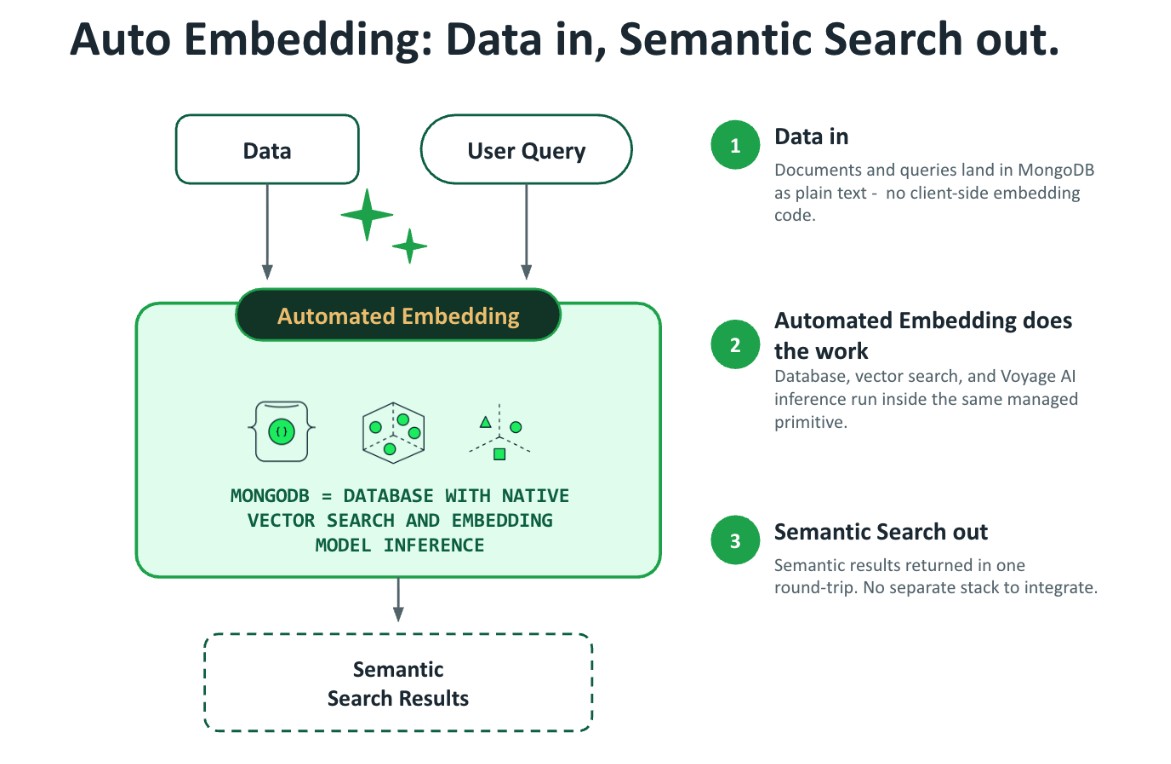
Automated Embedding is now available in Public Preview on MongoDB Atlas.
When we introduced Automated Embedding to MongoDB Vector Search in MongoDB Community Edition, we started from a single principle: developers building agentic applications shouldn't have to operate a parallel embedding pipeline just to search their own data. That release proved the pattern: text in, text out, no client-side embedding code. On MongoDB Atlas, it goes further, using Voyage AI embedding models to solve the operational problems that have made vector search the most fragile part of an agent stack.
Figure 1. Automated Embedding flow in MongoDB Atlas.
Your vector search index falls behind your data
A document gets edited. The vector store still has the old embedding. The agent retrieves stale context and confidently answers based on outdated information. The fix has historically been a backfill job, written by a human, scheduled by a human, and debugged by a human. The time between "data changed" and "index reflects it" is measured in hours, not seconds.
Automated Embedding solves this with field-level delta detection. When a document changes, MongoDB Atlas re-embeds only when an indexed field actually changes. Sync is near real-time, not batch. There is no manual re-index path because there's no manual index to maintain. For agents, this is the difference between trustworthy memory and stale context.
The same property extends to search on views. If your embedding source is a $concat of title, cast, and year, an update to any of those underlying fields automatically propagates through the view to the index.
One inference pool can't serve every workload
Embedding inference is the throughput problem hiding inside a latency problem. A first-time backfill needs to chew through tens of millions of documents as fast as possible. A live query needs a vector back in tens of milliseconds. A change stream sits in between, bursty, sometimes idle, and sometimes hot. One inference pool serves all three workloads poorly: tune it for throughput and queries time out; tune it for latency, and backfills take a week.
Automated Embedding separates inference into two mechanisms, each optimized for the workload it serves:
- Index builds are throughput-optimized using a newly introduced Inference Flex Tier, enabling them to go from zero to fully indexed without competing with live queries. Variable but unbounded throughout.
- Queries are latency-optimized, completing within the time budget agents actually have. Guaranteed but bounded throughput.
A backfill no longer slows your queries, and your queries no longer cap your backfill rate.
At scale, storage and indexing both break
Float32 vectors are honest but expensive. A million 1024-dimensional embeddings is roughly 4 GB before you've stored a single byte of operational data. At a hundred million vectors, storage cost becomes the line item, retrieval latency suffers, and the team starts asking whether they really need 1024 dimensions or whether 512 would do. That's a guess most teams shouldn't be making.
Storage isn't the only thing that breaks at scale.
One document per inference request wastes orders of magnitude of throughput. Hand-tuned batching helps until you hit a document shape that exceeds the model's token window mid-batch, at which point the whole request fails. Errors at this scale don't fail one document; they fail a job, and you find out the next morning.
Automated Embedding addresses both with configurable quantization and built-in dynamic batching, with no manual tuning required.
For storage, configurable quantization gives you the right point on the accuracy/cost curve:
- Scalar quantization (default) is roughly 4x smaller than float32, with retrieval accuracy nearly indistinguishable for most workloads.
- Binary quantization is roughly 32x smaller, for workloads where the corpus is large enough that the recall trade-off pays for itself many times over.
For indexing, built-in dynamic batching automatically optimizes for the maximum tokens per request, adjusting batch size in real time based on document shape and size:
- Automatic batch sizing adjusts in real time based on the actual shape and size of documents flowing through.
- Built-in error recovery means a single malformed or oversized document doesn't take down a multi-million-document indexing job. The system isolates, retries, and continues.
Together, configurable quantization and dynamic batching mean agents can scale to hundreds of millions of documents without storage or indexing becoming a bottleneck.
Integrated feature engineering
Retrieval quality lives or dies on the quality of the input that gets embedded. Automated Embedding supports search on views, which means you can define a composite field declaratively, concatenating or transforming fields from the underlying collection. MongoDB Atlas automatically embeds and indexes the view's output, so feature engineering for retrieval becomes a query-language exercise instead of an ETL pipeline.
The simplest case is embedding a single field directly.
Figure 2. Enabling AI search on a single field in your document.
.png)
When retrieval requirements grow more complex, you can combine multiple fields into a single embedding source.
Figure 3. Enabling AI search on a combination of fields in your document.
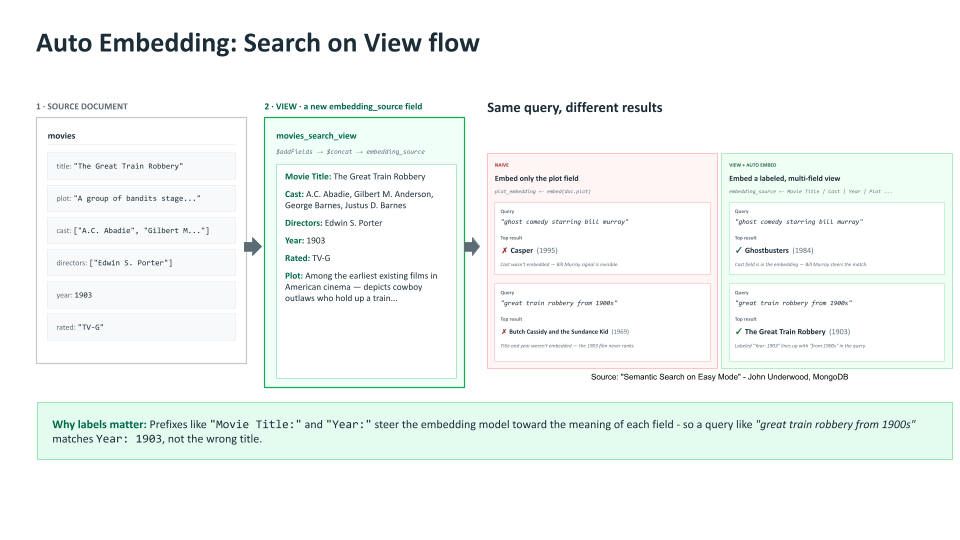
For teams chasing the last 10-15% of retrieval accuracy, this is the lever that makes the difference. For everyone else, it's the reason you don't have to maintain a separate "search index document" alongside your operational schema.
Why this matters
The teams winning at agent applications treat search as a primitive, not an integration project. Automated Embedding provides retrieval that stays current as data changes, fast enough for agent response times, observable down to the token, affordable at any corpus size, and compliant out of the box.
Together, these qualities deliver a memory layer agents can depend on, built into the same platform where their data already lives.
Start building
Automated Embedding is now available in Public Preview on MongoDB Atlas across our supported regions. To get started:
- Spin up or select an Atlas cluster.
- Define an Automated Embedding index on your collection or view, pick a model, and you're done.
- Query with natural-language text - no client-side embedding required.
Next Steps
Jump in with our quick start guide. Documentation, model options, quantization settings, and pricing details are in the Automated Embedding docs. We'd love your feedback while it's in Preview. The next set of improvements will be shaped by what you tell us!