A cluster is a group of multiple servers or nodes connected through a network and configured to work together as a single system. In distributed computing, a cluster—also called a server cluster—distributes workloads across multiple nodes, which improves system performance, ensures high availability, and reduces the risk of a single point of failure.
Key takeaways
- A cluster consists of multiple server nodes working as one system.
- A cluster is made up of several fundamental parts—nodes, servers, and clients—each playing a specific role in the system.
- Clusters improve system performance through workload distribution.
- Database clusters use multiple database servers to manage queries and data.
- High availability is achieved through redundancy and failover.
- Load balancing reduces resource contention across nodes.
Table of contents
How do server clusters work?
Clusters coordinate multiple nodes to process workloads efficiently, but proper configuration and the ability to configure settings are essential for successful cluster operation.
At a high level, incoming workloads are distributed across multiple nodes, each database node processes part of the request, results are combined and returned, and if a server fails another node takes over. Administrators must set variables and system parameters during setup to ensure optimal performance.
Clusters rely on load balancing to distribute queries, data redundancy to ensure availability, monitoring systems to detect failures, and backup processes to protect data. Understanding the technical details of cluster configuration and operation is crucial for maintaining performance and reliability. These mechanisms ensure continuous operation even under heavy load.
Learn more about MongoDB clusters.
What is a database cluster?
A database cluster is a group of database servers that work together to store, manage, and access data. Instead of relying on a single database server, a database cluster distributes queries across multiple database nodes, often organizing these nodes into groups for better management.
This approach improves performance and ensures that if one database server fails, another node can continue serving requests. Replication can occur at the granular level, with collections of data replicated across nodes to provide redundancy and load balancing.
A typical database cluster includes multiple database servers, replicated data stored across nodes, load balancing for incoming queries, and automated failover mechanisms.
In shared-nothing architectures, data is divided into segments, with each node independently managing its own segment to enhance performance and fault tolerance. Changes to data, such as updates or deletions, are propagated across the cluster to maintain consistency, and transactions are processed in the order they’re received to ensure data integrity. Database clustering is essential for applications that require consistent performance and high availability.
What are the key components of a cluster?
A cluster includes several essential components that work together to ensure performance, reliability, and coordination across multiple nodes. Each component plays a specific role in how a workload is distributed, how data is stored, and how the system responds to failure.
Nodes: Individual machines that process workloads or store data. Each node contributes compute, memory, or storage resources, allowing the cluster to handle larger workloads than a single system.
Master node: A central node that manages coordination, scheduling, and orchestration. The master node implements controls to monitor, regulate, and enforce policies for the cluster, ensuring cluster health, assigning tasks, and making sure all nodes are working together.
Database node (in database clusters): Nodes responsible for handling queries and managing data. These nodes store and retrieve data, often replicating data across multiple instances to support high availability and fault tolerance.
Network: Connects multiple nodes and enables communication between them. A reliable network is critical for coordinating workloads, synchronizing data, and maintaining consistent performance across the cluster.
Storage: Holds data stored across the cluster. Depending on the architecture, storage may be shared across nodes or distributed, allowing data to be replicated and accessed even if a server fails.
Load balancer: Distributes incoming requests to reduce resource contention and ensure even workloads across nodes. This helps maintain system performance and prevents any single node from becoming a bottleneck.
Why use a cluster?
Clusters solve limitations inherent in a single system:
Performance: A single server can become overwhelmed when handling a large workload. A cluster uses load balancing, distributing a given number of queries, and processing tasks across multiple servers to improve system performance.
Scalability: Clusters support horizontal scaling. Instead of upgrading a single machine, organizations add more nodes to increase capacity and efficiently manage growing demand.
Reliability: Clusters reduce the risk of a single point of failure. If a server fails, other nodes continue operating, ensuring continuous service availability and uninterrupted access to data.
What are the different types of cluster architectures?
Clusters can be designed using different architectures, where the overall shape of the cluster—its structure and configuration—directly impacts performance, scalability, and resilience.
Shared disk architecture
In a shared disk architecture, all nodes access the same data stored in a central storage system, providing a clear and unified view of data across all nodes. This transparency simplifies data management and ensures consistent access to data, making failover and recovery processes easier, though it can create bottlenecks under heavy workloads.
Shared-nothing architecture
In a shared-nothing architecture, each node has its own storage and memory. This reduces resource contention and improves scalability across multiple servers, but requires coordination to maintain data consistency. Shared-nothing architecture is widely used in modern database clusters.
High availability and fault tolerance
Clusters are designed for high availability. They achieve this through data redundancy across multiple nodes, automatic failover when a server fails, and continuous monitoring of system health.
If a single server goes offline, another node takes over without interrupting access to data. Keeping the system reliable requires continuous monitoring and proactive management to ensure consistent performance and reliability.
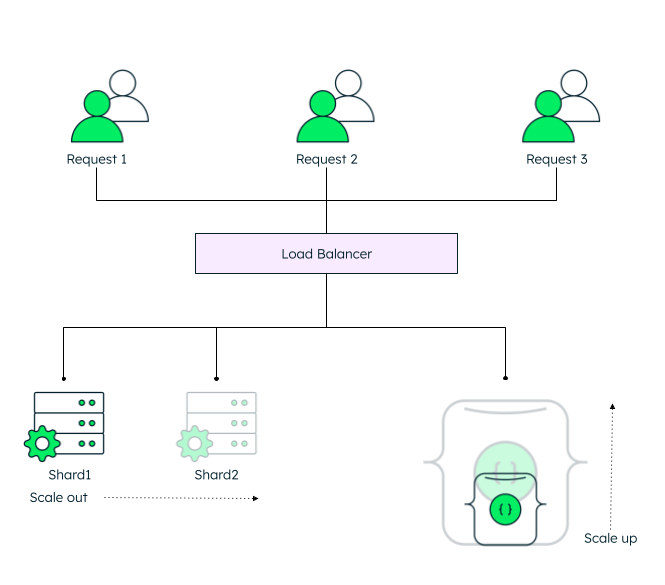
What is load balancing in clusters?
Load balancing distributes queries and workloads evenly across multiple servers. This improves system performance, reduces resource contention, and enables faster response times.
However, issues such as uneven load distribution or stale routing information can occur, especially during cluster restarts or network disruptions. Monitoring and resolving these issues is essential for effective load balancing. Without load balancing, some nodes may become overloaded while others remain underutilized.
Cluster vs. single server
Clusters provide a more resilient and scalable alternative to a single system.
What are common use cases for clusters?
Clusters are used in many environments, including:
Database management: Handles queries across multiple database servers.
Cloud infrastructure: Supports scalable applications across multiple instances. Managed services help customers reduce costs and simplify cluster management—Playtomic, for example, achieved 100-200 milliseconds response times on a single cluster while serving 14 million users.
Big data processing: Manages large datasets across distributed systems
Web applications: Ensures uptime during high traffic.
Challenges of clustering
Clusters introduce complexity. Common challenges include coordinating multiple nodes, managing data redundancy, handling network latency, and ensuring consistency across distributed systems. Administrators must resolve issues such as network failures or stale data, which can be propagated across the cluster if not addressed. Despite these challenges, clustering is essential for modern systems that require scale and reliability.
When should you use a cluster?
A cluster is appropriate when workloads exceed the capacity of a single server, high availability is required, applications must scale across multiple instances, or data must remain accessible even if a server fails. Organizations may choose to deploy a cluster when scaling applications or ensuring high availability is required, as deploying workloads across multiple nodes helps distribute resources and maintain service continuity.
For smaller applications, a single system may be sufficient.
Clustering in MongoDB
In the MongoDB ecosystem, clustering typically takes two forms:
Replica sets: A cluster of nodes that maintain the same data set, providing redundancy and high availability. If the primary node fails, an election automatically chooses a new primary.
Sharded clusters: Used for horizontal scaling, these clusters partition data across many replica sets (shards), allowing you to handle massive datasets and high throughput.
Clustering focuses on availability by creating identical copies of your data so the system stays online if a node fails, whereas sharding focuses on performance by splitting your data into smaller chunks across nodes to handle massive workloads.
Why clusters are essential for modern scalability and reliability
A cluster enables multiple servers to function as a single system, but the real advantage lies in how these servers are managed by control planes or orchestration systems to maintain the desired state. This management ensures reliability by coordinating nodes to achieve the correct system configuration and condition. By distributing workloads across multiple nodes, clusters improve system performance under pressure, reduce latency for high query volumes, and maintain consistent access to data even as demand grows.
Clusters also provide a practical path to high availability. Instead of relying on a single server, organizations can replicate data across multiple nodes, ensuring that if a server fails, another instance can immediately take over. This minimizes downtime and protects both the user experience and business continuity.
From an operational perspective, clusters allow teams to scale incrementally. Rather than investing in increasingly powerful hardware, organizations can add multiple servers as needed, aligning infrastructure costs with actual workload growth. This horizontal scalability is especially important for applications handling large datasets, real-time queries, or unpredictable traffic patterns.
As systems become more distributed and data-intensive, clustering shifts from an optimization to a requirement. It supports modern architectures that depend on resilience, flexibility, and continuous performance, making it a foundational approach for any environment where reliability and scalability are critical.
Related resources
- Understand how clusters work, including their structure, scaling, and core components.
- Learn how to set up and configure a MongoDB cluster for performance and reliability.
- Explore how intelligent workload management optimizes resource usage across clusters.
- See how querying works in MongoDB and how clusters improve query performance.
- Review the fundamentals of database management and how clusters support data operations.
- Understand how replication distributes data across nodes to ensure redundancy and availability.
- Learn how clusters enable high availability and minimize downtime in distributed systems.