Enterprise infrastructure increasingly runs declaratively. If a new capability is not available through the Infrastructure as Code (IaC) tool a customer has standardized on, it does not exist for the part of their organization responsible for shipping it to production. For the MongoDB Atlas customers we serve, that tool is overwhelmingly Terraform. And the gap between an Atlas API shipping and the matching resource appearing in the MongoDB Atlas Terraform Provider was four to ten weeks, a function of both the code development required per resource and the bandwidth our team had to maintain the provider alongside competing priorities. Given how central Terraform is to how customers consume Atlas, we wanted it to be a first-class delivery target for new features.
The obvious explanation was that manual implementation is slow. The less obvious one mattered more. Every new resource exposed the same shape of friction: API fields whose ownership the spec did not pin down, lifecycle operations the API did not provide, metadata our Terraform engineers had to fill in on the customer's behalf, high customization, lack of complete examples. And we were paying that cost across every downstream consumer of the Atlas API, each tool reimplementing the same workarounds against the same gaps, with no shared mechanism to fix them at the source.
We built an auto-generation engine for the MongoDB Atlas Terraform Provider as a first-class citizen of the MongoDB Atlas API design that runs every time we make changes to our APIs. The lesson it taught us turned out to be bigger than Terraform: declarative-friendly interfaces don't tolerate ambiguity. Automation forced each of these ambiguities to be resolved explicitly rather than absorbed silently in a hand-written implementation. We treated that as an opportunity: instead of adapting around the gaps or passing them on to our customers, we used auto-generation as a forcing function for fixing them at the source: in the API itself and in the API design standards we've written about separately. Every downstream consumer of the Atlas API (CloudFormation, CLI, Go SDK, Kubernetes Operator) inherits the same improvements, and customers get new capabilities at a faster, more consistent pace through the Terraform workflow they already rely on.
Why APIs break down under declarative tooling
Declarative toolings make specific assumptions about every resource: a stable identity, a clean set of standard operations, an unambiguous answer to "who owns this field?" and "what does this update touch?". When the API holds up its end of that contract, generation is mechanical. When it does not, the gaps surface. The most common patterns made evident through auto-generation included:
- Lack of resource-oriented design and custom methods. Some MongoDB Atlas APIs expose an action as a custom method (POST /api/atlas/v2/groups/{groupId}/serviceAccounts/{clientId}:invite) rather than as a resource the customer can create, observe, and reconcile. Declarative tooling has no deterministic way of consuming a custom method: it is not a declarative state.
- Missing or malformed CRUD semantics. These are standard operations that do not behave like CRUD: a POST that doubles as update, a "delete" that is actually a reset to defaults, partial field coverage where a property appears in GET but is missing from a POST/PATCH response (or vice versa). Patchable by hand, but a fresh special case every time.
- Unclear field ownership. Both the user and the server set values for the same field, and the spec does not state which one owns it. The user provides a value; the server may accept it, override it, or supply its own default. Without a clear rule, IaC tools cannot reconcile config and state and the customer sees a successful terraform apply followed by drift on the very next plan.
- Side effects and silent input rewriting. An update to resource A that implicitly mutates resource B (the customer sees unexplained drift on B) or an API that silently rewrites bad input to a different value instead of returning a validation error. Both lead to unwanted drift: config and stored value will never agree.
These gaps share a common fix: pinning them down upstream. Every ambiguity pinned down in the API and in MongoDB's IPA standards (our internal Improvement Proposals for APIs, which define the design rules an Atlas API must meet) ships once and benefits every downstream consumer.
Inside the auto-generation engine
Our auto-generation system is built as a series of layers, each with a clear responsibility. This separation enables testing, debugging, and future extensibility. It also enables the forcing function mechanism: when an API does not meet the contract a layer expects, either in its design or in its runtime behaviour, the resulting generation halts with an explicit error rather than silently working around the gap.
Figure 1. The auto-generation pipeline.

OpenAPI Spec. Everything starts from the Atlas Admin API's OpenAPI spec—the canonical, machine-readable contract of the API's operations and schemas, and the single source every generated resource builds from. Any path or type that the generator cannot resolve against the spec halts generation rather than being guessed.
YAML Config. A small per-resource YAML file maps API operations to the Terraform resource lifecycle and records the deliberate exceptions (aliases, sensitivity, computability). The trimmed log_integration block:
A new resource starts as a file of this size. The seven production resources we have already automated average roughly 40 lines of YAML each. Anything the generator cannot infer from the spec, such as Terraform provider naming conventions or fields the OpenAPI spec does not mark sensitive, is set once here and applied uniformly everywhere that resource appears, including its data sources, so each deliberate choice stays explicit and auditable. The YAML also pins each resource to a specific Atlas Admin API version, so multiple Terraform resources can be generated side-by-side from different versions of the same MongoDB Atlas resource. And where the API does not expose a clean operation for a lifecycle step—a missing single-resource GET, say—the gap can be handled by an explicit narrow custom hook (covered in the next section) rather than a silent workaround.
Intermediate Model. Before any Go is generated, the YAML and the flattened spec are reduced to a model that describes the resource in IaC-agnostic terms: attributes, types, computability, and where each value comes from in the request and response. It cleanly separates parsing, business logic, and code emission, so the upstream stages can feed other IaC tooling later. This is where field ownership is resolved: whether each value is user-set or server-owned, derived from the API's required fields, the operations that read and write it, and any config overrides. The guarantee is that a single unified schema can be constructed over the chosen operations, or generation fails rather than emitting a broken resource.
Code Generation (with Custom Code). From the intermediate model, the generator emits the Terraform resource schema, data sources, CRUD functions, and registry documentation. Internally, the generated Go does not look hand-written; it is structured around the generic CRUD machinery in the autogen package rather than per-resource code paths. To the customer, though, the resource is indistinguishable from a hand-written one: same schema shape, same plan output, same error surface. Because the result is a fully functional resource, this is the first stage where the API's actual runtime behaviour can be exercised end-to-end, surfacing what static spec checks miss, such as drift, side effects, and silent input rewriting.
Automated Workflows. A GitHub Actions pipeline watches for changes in the Atlas OpenAPI spec, reruns the generator for affected resources, and opens a pull request against the provider repo. A spec change does not require an engineer to notice it; it shows up as a reviewable diff.
Custom code and incremental adoption
Two parts of the system exist specifically to handle the cases where the ideal pipeline does not fit reality: APIs that do not yet meet the declarative-friendly contract, and a provider that still ships dozens of hand-written resources that customers depend on.
Custom code at the CRUD boundary
Not every MongoDB Atlas API today exposes the four operations a Terraform resource needs in the shape the generator expects. mongodbatlas_service_account_secret is the clean example: the API can create a secret and delete it, but it does not expose a GET for a single secret. The only way to fetch one is to list all secrets on the parent service account and filter.
Figure 2. The custom hooks mechanism.
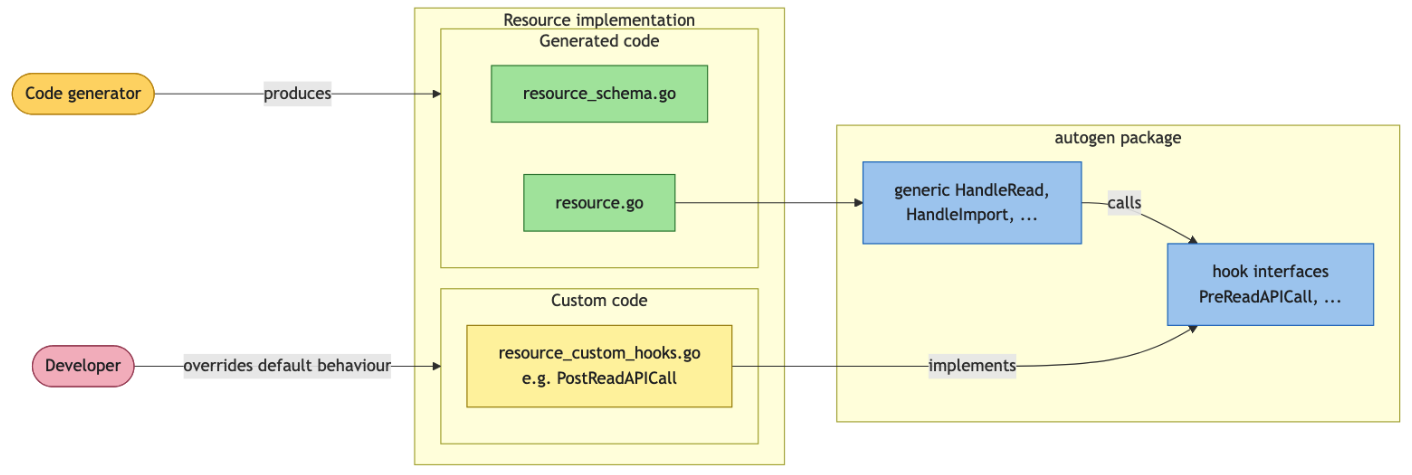
Our custom code layer lets a resource opt into a hook for any CRUD operation; the hook returns a modified request or response, and everything around it stays generated. For service_account_secret, a PostReadAPICall hook (resource_custom_hooks.go) runs after the generated read and filters the secret list down to the one tracked in state. The `autogen` package detects the hook interface at runtime and invokes it only on resources that assert it, leaving the rest generated. When the upstream API later gains a proper single-secret GET, the hook file is deleted, and nothing else changes.
The principle is the same one the API-gap discussion landed on: fix upstream when possible, customize only when necessary, and keep the customization narrow enough that it does not become a parallel maintenance burden.
Coexistence with hand-written resources
The provider already ships dozens of hand-written resources backing production customer state. Requiring those to be migrated before any auto-generated resource could ship would have delayed every benefit of the project by months and put existing customer state at risk for no immediate gain. Generated resources, therefore, live alongside hand-written ones in the same provider binary, under internal/serviceapi/, with the same schema framework and the same testing harness. A new resource ships through the generator without touching any of the hand-written code, and a customer using both kinds of resources in the same configuration cannot tell which is which.
Incremental adoption is what made the project shippable in practice. Migrating existing resources without breaking production state is its own problem (covered later), and we did not have to solve it to start delivering value.
Results
The numbers below come from resources auto-generation has actually shipped, compared against the manual baseline for similar work.
The seven resources currently shipping through the generator span three feature areas:
- log integration
- private-link endpoints for data federation
- five-resource service-account family:
- mongodbatlas_service_account (org-level)
- mongodbatlas_service_account_secret
- the project-scoped pair mongodbatlas_project_service_account and mongodbatlas_project_service_account_secret
- mongodbatlas_service_account_project_assignment
The plural data source for mongodbatlas_project_ip_access_list is also generated; its resource and singular data source remain hand-written.
The customer is the ultimate beneficiary
Autogeneration changed how we build. But the metric that matters is whether customers see the difference—and they do, in two concrete ways. Here’s what they experience:
Consistent, predictable APIs across every surface
Declarative tooling demands zero ambiguity. By running autogeneration in parallel with API design, we pushed that requirement upstream: field ownership gets resolved, CRUD semantics get standardized, naming conventions get enforced—before anything ships. The benefit is not limited to Terraform. Any customer navigating any MongoDB Atlas surface benefits from API designs they can learn once and apply by intuition across every resource.
A migration process that leaves no one behind
Every autogenerated resource is pinned to a specific Atlas Admin API version. When a new API version introduces breaking changes, we plan to generate a new Terraform resource pinned to that version alongside the existing one and support migration via Terraform's moved block. Breaking changes land in Terraform Provider major releases; everything else ships in minor releases. When a new major version is cut, we deprecate the old resource and complete the consolidation.
The result:
Customers who cannot upgrade immediately stay unblocked—they keep the version they depend on
Customers who are ready get a smooth, documented migration path
Feature adoption velocity is unaffected by the version cadence
Resource naming stays consistent and predictable across versions
The final verdict is: customers navigating any surface benefit from consistent, predictable API designs they can learn once and apply by intuition across every resource.
What's still manual, and what's next
These are wins we can measure today, and four areas where we will look to improve next:
- Acceptance tests and examples. Successful generation only verifies that a valid schema and CRUD implementation can be produced from a given API design and config overrides, not that the resource behaves correctly at runtime or composes with other resources in a real configuration. End-to-end acceptance tests and real-world example configurations (often using other resources alongside the generated one) are still hand-written, and closing that gap is what takes a resource from generated to production-ready. This is also where the most hand-written work remains. We are exploring generative AI to scaffold acceptance tests and draft realistic example configurations, producing a reviewable first draft that an engineer then verifies.
- Migrating existing resources. The provider's remaining hand-written resources still need to move to auto-generation, without breaking the customer state they have back today. The principle is the same as for new resources: customer experience cannot regress. We are migrating one resource at a time, weighing the migration cost against the future changes a resource is likely to need, which are streamlined once it ships through the generator.
- More advanced IPA validation. MongoDB's IPA validation tooling already checks much of the design ruleset against the OpenAPI spec automatically, catching common gaps before an API ships. The harder cases sit outside the static spec entirely: runtime behaviours that contradict the declared schema, side effects on other resources, and design rules whose evaluation depends on context the spec does not carry. Extending the validation pipeline to capture those signals, without giving up the determinism of the static checks, is ongoing work.
- Expanding to other IaC platforms. The pipeline's upstream stages (OpenAPI spec parsing and the intermediate model) were built to be reusable across IaC targets, so much of the work carries over to new ones. The open question is on the implementation side: which parts of the pipeline still apply as-is, and how much per-platform translation each new target requires.
Takeaways
Three takeaways for teams shipping APIs to declarative IaC tooling:
- Auto-generation is only as good as your API design; use it to improve both. A generator surfaces every gap in your API: field ownership, CRUD semantics, custom methods, and conventions. Fixing the API, and its design standards, is cheaper than working around it in every consumer forever, and the customer experience improves across every integration at the same time.
- Customer UX is non-negotiable, even when automation is the point. It is tempting to celebrate the time saved per resource. The metric that matters is whether the customer can deploy a new feature on day zero through their existing workflow, with the muscle memory they built on every other resource. Generated resources must be indistinguishable from handwritten ones.
- Fix upstream, and design for the cases the upstream fix has not reached. Auto-generation gave us a forcing function for pushing improvements into our API standards, where they benefit every downstream integration. For the APIs that did not yet meet those standards, a custom-code layer extended coverage without giving up consistency. Invest in standards at the source; build escape hatches at the edges.
Next Steps
The resources described here ship today in the Atlas Terraform provider. The API design standards behind the pipeline are open in the IPA repository.