Overview
このガイドでは、Apache Kafka と Kafka Connect に関する次の基礎情報を学習できます。
Apache Kafka と Kafka Connect は
Apache Kafka と Kafka Connect が解決する問題
Apache Kafka と Kafka Connect が役立つ理由
Apache Kafka と Kafka Connect パイプラインでのデータの移動方法
Apache Kafka
Apache Kafka は、オープンソースの公開/サブスクライブ メッセージング システムです。 Apache Kafka は、データストアとアプリケーション全体にデータを移動するための柔軟でフォールト トレランスがあり、水平スケーラブルなシステムを提供します。 システムの特定のコンポーネントが動作を停止してもシステムが動作を継続できる場合、システムはフォールト トレランスがあります。 マシンのハードウェアを改善することで、マシンを追加することでシステムを拡張し、より大きなワークロードを処理できる場合、システムは水平方向にスケーリングできます。
Apache Kafka の詳細については、次のリソースを参照してください。
Kafka Connect
Kafka Connect は、Apache Kafka を MongoDB などのデータストアに接続する際の問題を解決する Apache Kafka のコンポーネントです。 Kafka Connect は、次のリソースを提供することで、この問題を解決します。
データストアとの間でデータを転送するためのフォールトトレランス ランタイム。
Apache Kafka コミュニティが Apache Kafka をさまざまなデータストアに接続するためのソリューションを共有するためのフレームワークです。
Kafka Connect フレームワークでは、開発者が 再利用可能なコネクターを記述するための API を定義します。 コネクタを使用すると、 Kafka Connect の配置で特定のデータストアをデータソースまたはデータ シンクとしてやり取りできるようになります。 MongoDB Kafka Connector は、これらのコネクターの 1 つです。
Kafka Connect の詳細については、次のリソースを参照してください。
Tip
データストアに接続するときに、プロデューサー/コンシューマー クライアントではなく Kafka Connect を使用
ApacheKafkaプロデューサー クライアントとコンシューマー クライアントを使用して特定のデータストアに接続するための独自のアプリケーションを することもKafka の方が適している場合があります。Kafka Connect を使用する理由は次のとおりです。
Kafka Connect は、信頼性の高いパイプラインを確保するために、フォールト トレランス 分散アーキテクチャを備えています。
Kafka Connect フレームワークを使用して、Apache Kafka を MongoDB、PostgreSQL、MySQL などの一般的なデータストアに接続するための多数のコミュニティ コネクターが管理されています。 これにより、データベース接続、エラー処理、デッド レター キューの統合、および Apache Kafka をデータストアに接続する際に発生するその他の問題を管理するために、
Confluent のマネージド Kafka Connect クラスターを使用するオプションがあります。
図
次の図は、Apache Kafka と Kafka Connect で構築されたサンプルデータパイプラインを介して情報がどのように通過するかを示しています。 このパイプラインでは、MongoDB クラスターをデータソースとして使用し、MongoDB クラスターをデータ シンクとして使用します。

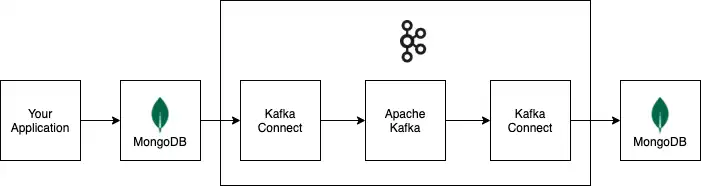
サンプル パイプラインのコネクターとデータストアはすべて任意です。 これらは、配置に必要な connector と データストア に置き換えることができます。