大規模言語モデルの仕組み
大規模言語モデル(LLM)は、人間の言語を処理して生成するためにディープラーニング技術を利用することで機能します。
- データ収集:LLM をトレーニングする最初のステップは、インターネットからテキストとコードの膨大なデータセットを収集することです。このデータセットには、人間が書いたさまざまなコンテンツが含まれており、LLM に多様な言語基盤を提供します。
- 事前学習データ:事前学習の段階では、LLM はこの膨大なデータセットにさらされます。LLM は文中の次の単語を予測することを学習し、単語やフレーズ間の統計的関係を理解します。このプロセスにより、LLM は文法や構文、さらには文脈の理解もできるようになります。
- データのファインチューニング:事前学習の後、LLM は特定のタスクのために微調整されます。これには、翻訳、センチメント分析、テキスト生成など、目的のアプリケーションに関連する狭い範囲のデータセットに LLM をさらすことが含まれます。ファインチューニングにより、これらのタスクを効果的に実行する能力が向上します。
- 文脈の理解:LLM は文中のある単語の前後の単語を考慮することで、一貫した文脈に関連したテキストを生成することができます。この文脈認識こそが、LLM が以前の言語モデルと異なる点です。
- タスクへの適応:ファインチューニングにより、LLM は幅広いタスクに適応できます。質問への回答、人間のようなテキストの生成、言語の翻訳、文書の要約など。この適応性は LLM の重要な強みのひとつです。
- デプロイメント:LLM は一度トレーニングされると、さまざまなアプリケーションやシステムにデプロイできます。LLM は、チャットボット、コンテンツ生成エンジン、検索エンジン、その他の AI アプリケーションに搭載され、ユーザー体験を向上させます。
まとめると、LLM はまず膨大なデータセットで事前学習を行い、人間の言語の複雑さを学習します。その後、文脈理解を活用して、特定のタスクのために能力を微調整します。この適応性により、LLM は幅広い自然言語処理アプリケーションに対応する汎用性の高いツールとなっています。
また、特定のユースケースに適した LLM を選択すること、モデルの事前学習やファインチューニング、その他のカスタマイズのプロセスは、Atlas とは独立して行われます(したがって、Atlas Vector Search の範囲外となります)。
大規模言語モデル(LLM)と自然言語処理(NLP)の違い
自然言語処理(NLP)は、コンピュータと人間の言語との相互作用を促進することに特化したコンピュータサイエンスの一領域であり、話し言葉と書き言葉の両方のコミュニケーションを含みます。その範囲は、人間の言語を理解、解釈、操作する能力をコンピュータに与えることであり、機械翻訳、音声認識、テキスト要約、質問応答などのアプリケーションに及びます。
一方、大規模言語モデル(LLM)は NLP モデルの特定のカテゴリとして登場しました。LLM モデルは、膨大なテキストやコードのリポジトリに対して厳しいトレーニングを受けることで、単語やフレーズ間の複雑な統計的関係を識別できるようになります。その結果、LLM は首尾一貫した、文脈に関連したテキストを生成する能力を発揮し、テキスト生成、翻訳、質問応答など、さまざまなタスクに使用できます。
リアルワードのアプリケーションにおける大規模言語モデル(LLM)の使用例
カスタマーサービスの向上
カスタマーサービスを向上させようとしている企業を想像してみてください。LLM の能力を活用して、自社の製品やサービスに関する顧客からの問い合わせに対応できるチャットボットを作成できます。このチャットボットは、顧客からの質問とそれに対応する回答、および詳細な製品ドキュメントで構成される広範なデータセットを使用して、トレーニングプロセスを受けます。このチャットボットの特長は、顧客の意図を深く理解し、的確で有益な回答を提供できることです。
スマートな検索エンジン
検索エンジンは私たちの日常生活の一部であり、LLM はこれらの検索エンジンをより直感的にします。これらのモデルは、たとえ完璧な表現でなくても、ユーザーが何を検索しているのかを理解し、膨大なデータベースから最も関連性の高い結果を取得し、オンライン検索体験を向上させます。
推薦のパーソナライズ
オンラインショッピングやストリーミングプラットフォームで動画を視聴していると、好みに合いそうな商品やコンテンツが表示されることがよくあります。これらのスマートな推薦は LLM によって実現されており、ユーザーの過去の行動を分析して、好みに合った商品やコンテンツを提案し、オンライン体験をよりパーソナライズされたものにしています。
クリエイティブなコンテンツ制作
LLM は単なるデータ処理者ではなく、クリエイティブな頭脳の持ち主です。ブログ記事や商品説明、さらには詩のコンテンツを生成できるディープラーニングアルゴリズムを持っています。これは時間の節約になるだけでなく、企業がオーディエンスのために魅力的なコンテンツを作成するのに役立ちます。
LLM を取り入れることで、顧客との対話、検索機能、商品推薦、コンテンツ作成が改善され、最終的には技術的な展望を変えることになります。
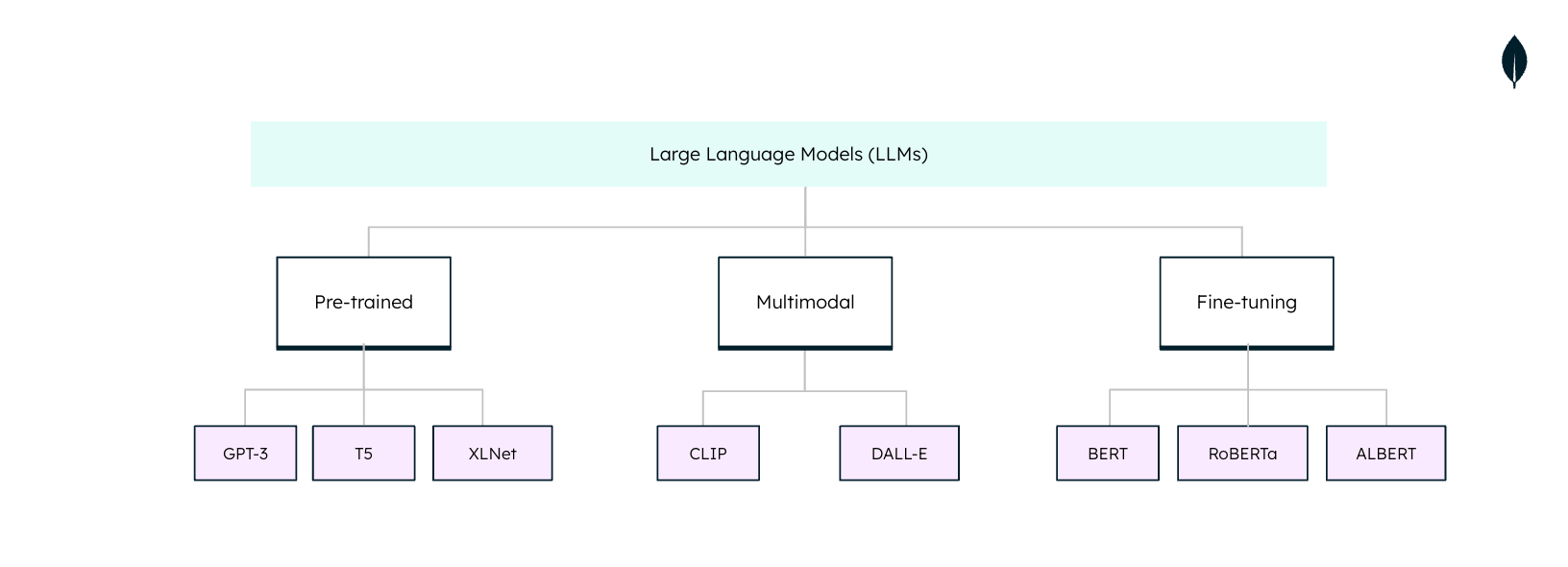
大規模言語モデル(LLM)の種類
大規模言語モデル(LLM)は、自然言語処理(NLP)タスクで使用される場合、万能ではありません。それぞれの LLM は、特定のタスクやアプリケーションに合わせて調整されています。LLM の可能性を最大限に活用するには、これらのタイプを理解することが不可欠です。
事前学習されたモデル:
GPT-3(Generative Pre-trained Transformers)、T5(Text-to-Text Transfer Transformer)、XLNet(Extra Large Neural Networks)のような事前学習モデルは、膨大な量のテキストデータを使った徹底的なトレーニングを経ています。これらのモデルは、多様なトピックについて一貫性があり文法的に正しいテキストを生成でき、さらなる学習やファインチューニングといった他の AI タスクの基盤として役立ちます。
ファインチューニングされたモデル:
BERT(Bidirectional Encoder Representations from Transformers)、RoBERTa、ALBERT(いずれも BERT の拡張版)などのファインチューニングモデルも、自然言語処理向けの機械学習モデルの1つです。これらの機械学習モデルは、事前にトレーニングされたモデルとして開始されますが、その後、特定のタスクやデータセットで微調整されます。これらの機械学習モデルは、センチメント分析、質問応答、テキスト分類などの特定のタスクに非常に効果的です。
マルチモーダルモデル:
CLIP や DALL-E などのマルチモーダルモデルは、テキストと視覚情報を組み合わせたものです。CLIP は Contrastive Language-Image Pre-training の頭文字をとった略語です。DALL-E という名前は、"Dali"(画家のサルバドール・ダリ)と "Wall-E"(ピクサー映画のロボットアニメのキャラクター)を組み合わせた言葉遊びです。どちらも、視覚情報と文字情報を結びつけるタスクを実行する能力で知られています。
まとめると、事前にトレーニングされたモデルは幅広い基礎を提供し、ファインチューニングされたモデルは特定のタスクに特化し、マルチモーダルモデルはテキストと画像のギャップを埋めます。選択は、特定のユースケースと手元のタスクの複雑さによって決まります。
Atlas Vector Search:高度な検索機能で生成 AI アプリケーションの構築を加速
今日の急速に進化する世界において、MongoDB Atlas Vector Search は、さまざまな人気のLLMやフレームワークと統合し、AI アプリケーションの構築を簡単に始められるようにすることで、LLM 技術をさらに次のレベルへと引き上げます。Atlas Vector Search を使用することで次のことが可能になります。
- OpenAI、Hugging Face、Cohere によって生成されたベクター埋め込みを、ソースデータやメタデータとともに保存し、検索できます。これにより、テキスト生成、言語翻訳、質問への包括的かつ有益な回答を可能にする高性能な生成 AI アプリケーションを構築でき、分散した運用データベースやベクターデータベースを管理する負担を軽減します。
- 検索拡張生成(RAG)や、LangChain、LlamaIndex などのアプリケーションフレームワークとの統合を通じて LLM に長期記憶を提供します。Atlas Vector Search は、独自のデータから関連するビジネスコンテキストを LLM に提供し、LLM が長期にわたるユーザーとのやり取りから学習して、よりパーソナライズされた関連性の高い応答を提供することで、幻覚を減らします。
- Nomic を使用することで、Webブラウザ上で簡単にベクトル埋め込みデータを視覚化し、探索できます。
- Microsoft Semantic Kernel を使用して、C# と Python で LLM アプリケーションを構築できます。
高度な検索や生成 AI アプリケーションの構築にご興味をお持ちなら、Atlas Vector Search が最適です。Atlas Vector Search は、AI アプリケーションの開発とデプロイのための強力で柔軟なプラットフォームを提供します。
MongoDB Atlas Vector Search について詳しくはこちらをご覧ください!